I guess I chose my words poorly. I didn’t expect them to be changed. I suggest to be able to explicitly set them at creation. The nonce solution looks weird.
Right, and its trivial to force it, so lets do that.

I guess I chose my words poorly. I didn’t expect them to be changed. I suggest to be able to explicitly set them at creation. The nonce solution looks weird.
Right, and its trivial to force it, so lets do that.
QuantityOrFlags
The encoding is not standard. Please just reuse var-int as used in BCH already.
The reason VarInt is not used is because this number is a pushed CScript entity so it already has a size. Putting a VarInt in a script stack item specifies the size twice so it inefficient. VarInts also don’t appear in scripts. They are also complicated compared to what I specified which is basically just interpreting the number in standard little-endian format. This is very similar to what CScriptNum does except that CScriptNum has additional “minimal encoding” constraints. These minimal encoding constraints are not needed in Group prefixes because they are not malleable (do not appear in input scripts).
WRT using the lowest bit rather than the highest: Yes, it would use less room for the authorities. But use of authorities is rare compared to normal tx. And I think doing that would be a lot more confusing and likely buggy for normal use. Finally, there is a future use for some of those empty bits. In particular, they might define a maximum quantity of mint or melt that this authority can do. Doing this would be more rules though, so I think we should wait for a need to show up.
But I am willing to change this if the majority of the dev community wants it the more efficient, low bit way.
What about a 160 bit (ripe) based hash instead for the groupID?
It is generally agreed that P2SH is right on the edge with 160 bits due to the fact that for certain operations among multiple parties its security is actually 2^80 via wagner’s birthday attack. A similar attack is possible against groups where a group creator searches for a GrpId collision at difficulty 2^80 and then commits only one of the 2 transactions. This group could have a guaranteed limited supply via burning authorities. However, subsequently committing the 2nd transaction would recreate the authorities that the creator burned.
GroupIds will be highly compressible because they will be repeated a lot, especially when you consider that tokens will likely have exponential popularity (few tokens will constitute most of the transactions).
Group flag bits are part of the hash.
The group flag bits define the properties of the group which are not changeable. That would not be “fair” to holders. Also, its more efficient to do it this way.
confusing note
hmm yes I’m trying to say something obvious very pedantically. What I’m trying to say is that OP_GROUP only has group semantics if it comes first. But it can appear anywhere in the script and is just treated as a no-op that drops its 2 arguments. This makes implementation simple.
IsStandard Changes
What you are saying is the right way to implement it. OP_GROUP appearing anywhere except as the prefix is non-standard. You can’t quite drop it because it should be stored in the UTXO, etc… but basically you can skip executing it.
There was pressure years ago for the Group prefix to be interpretable as part of a normal script, since its in the “CScript”. Group could even be implemented as a soft fork by reusing one of the NO-OP instructions.
If no one cares about this anymore, then the most extensible way to do it is to make CScript be divided into an “attribute prefix” and then the actual script (if there is one). We could use a single leading opcode to identify such a “CAttributeScript”. There are other interesting attributes. For example, if there’s an opcode that pushes attribute N onto the stack then scripts that enforce constraints on other scripts could be much simpler to write since all the variable parts could be factored out into attributes. And really when you think about, P2SH is better conceived of as attribute: the hash of the script that will be supplied later. Its not a viable script which is why bitcoind needs to handle it specially.
But again I’d like to hear overwhelming support from the community for a change like that. Making OP_GROUP an executable opcode that just pops its args from the stack is the minimum-change path.
Subgroup ID
Note that the subgroup id is limited by the maximum stack size. I don’t have strong feelings about this or about what this number should be. But at a minimum, encoding another cryptographic hash makes sense since that hash can act as lookup-and-proof of some larger amount of data.
At the same time, I have always felt that we can solve data-on-blockchain problems by encouraging miners to charge more for data transactions (esp. now that double spend proofs exist), which is why I specced it this way.
So I’m happy with whatever BCHN as the majority hash power or the dev community at large chooses so long as its >= 32 bytes.
The problem with that is that it mixes layers. The code that interprets the group stuff doesn’t care much about Script. Script is really just the carrier wave. To the Group checking code there are simply two byte-arrays that it gets and needs to interpret.
From that point of view, the input being 2 bytearrays, I think using an existing encoding is the way to go.
I doubt that it would be more buggy. All it adds to “normal usage” is a times by two or divide by two.
Conversely, your option makes that same “normal usage” test for a bit.
Again, the point of view of which software deals with this data is relevant. A JavaScript version is definitely not harder, possibly even easier with the checking bit at the lowest.
let amount = in2 / 2;
if (Math.trunc(amount) == amount) {
Console.log("Token amount being transferred " + amount);
} else {
Console.log("This is a control transaction!");
}
ps. extensibility is not an issue. Its a var-int. If you need more bits, it scales with no backwards compatibility issues.
The whole process on creation of tokens is still unclear to me, I’ll have to read more.
The suggestion was not to remove the bits from the groupId. Naturally the bits are part of the group Id, just not part of the hash (still not clear what is gained by it being a hash, btw).
Ok, I don’t want to go with your much more expensive idea you followed up with. But can we simply agree to the idea that OP_GROUP has to be first, otherwise the transaction is invalid (consensus). The same way that a single byte is appended for the sighash. That approach cleans up your spec too.
You have any explanation of that somewhere?
The whole subgroups part isn’t really explained in the spec or the chip yet. (or I missed it, apologies!)
Ok, lets set the (sub)groupID to 32 + 32 bytes max then. Sounds expensive for the general case, and I will keep pushing to try to optimize that.
But the max is relevant, the avoidance of another general data-store is important and has to be taken into account.
You’re right – it’s not, I plan to add it in the rewrite. For now, an explanation can be found in Andrew’s doc here, link is directly to the relevant section..
Maybe this will help. We have a global rule that sums must balance, and authorities are a way to locally (single TX scope) break that rule. That’s the fundamental principle for all further utility – constrain globally, relax locally. Another rule is that an authority can’t be created from nothing, it must be created from an authority to create authority. So how do we get authorities into the system? Genesis is the only place where that rule can be locally broken, where the first authority can be created, from nothing. And for it to be safe, we must be able to prove that genesis can happen only 1 time for any given groupID, and we do this by hashing so it’s computationally impossible to generate 2 genesis transactions resulting in the same groupID. If you could generate a “double” through birthday attack, you could publish one, and hold onto the other until the right time comes to abuse it.
Tomz, while I am not against your suggestions I think that I’m going to wait for BCHN to weigh in. I like some of my decisions slightly better but do not have strong feelings. As the hash power leader, let’s be honest: what BCHN wants for any of these small things, they’ll get because I won’t block deployment of this for something small. For example, I pretty much expect a subgroup max length to happen like you’ve suggested. But what I don’t want to do is go off and change the code and then have to turn around and change it back.
To continue our discussion:
The problem with that is that it mixes layers. The code that interprets the group stuff doesn’t care much about Script. Script is really just the carrier wave. To the Group checking code there are simply two byte-arrays that it gets and needs to interpret.
I actually think that you are mixing layers because VarInts are part of TX serialization and this is accessed after that. Its also:
But can we simply agree to the idea that OP_GROUP has to be first, otherwise the transaction is invalid (consensus). The same way that a single byte is appended for the sighash. That approach cleans up your spec too.
If we did that, script verification would require another pass, searching for any other OP_GROUP instructions (because parts of scripts may not be executed).
I’m ok with defining OP_GROUP as failing the transaction when executed, rather than popping its args like it currently does. And then requiring that the prefix " OP_GROUP" be chopped from the beginning of any script. However, I think you will find that doing it this way makes more changes because you have to specially handle OP_GROUP in more places. (Again though, I want to wait for BCHN’s opinion).
The suggestion was not to remove the bits from the groupId. Naturally the bits are part of the group Id, just not part of the hash (still not clear what is gained by it being a hash, btw).
Making it a hash ensures that the group id is unique upon creation. Post creation, the fact that its is a hash is mostly irrelevant. The one way its relevant is that it commits to a human readable contract (or a hash pointer to one). So the token creator can’t change the TOS underneath the holders.
Making the bits part of the hash means that they essentially cost nothing WRT blockchain storage space. We need 32 bytes of group ID to block wagner’s birthday attack, but by requiring group authors to do a bit of work to search for a hash, we can use those bits for another purpose, while still requiring the same work to be done for any attempt to find a group collision.
Also from a practical perspective, the group id fits in a 256 bit integer which is very nice. BTW, its also nice (but not necessary because we can use a different prefix) that the size is greater than the 20 byte bitcoin cash address. This is an easy way to tell them apart.
Thank you for continueing the discussion 
Right, I guess I didn’t make clear what I meant becuase I had a suggested design in my head that doesn’t match the example one. So let me give a high level overview of this so we can clearly see the “layers” appear.
First of all, the Group code needs to access the data as stored in the script. But the important part is that those are stored in the output that is spent. So, not inside of the transaction we are checking, but we need to get the data from each of the inputs that are spent.
During validation this is already data that is accessed. And the best way to avoid a double-lookup, I would grafitate towards a solution where the validation process stores the 2 stack items on some transaction-meta-data object.
After the scripts are all validated and Ok, the group information can then be validated based on the data stored with the transaction itself (on the meta obj), avoiding any extra costs for lookups of previous output-scripts.
This means that the group-checking code (which operates on a per-transaction basis) just finds 2 byte-arrays for each input that actually is a group input.
I guess 1 & 2 are personal, my main criterea is to not introduce a new format. All transaction parsing code already knows the varint format that Satoshi invented. Sure, something else can be simpler, but its still more code to do nearly the same thing and more chances for mistakes (which covers 3).
Point 4 is false. No space is wasted because Bitcoin Script reserves OP_1 - OP_75 for direct pushes.
There is no such need. There are various simple solutions to avoid doing two passes. The simplest (kinda hacky) is to add a bool in the Interpreter.cpp call eval() which detects multiple during normal validation. A simpler (clean) solution is based on the general architecture I described above which detects the same, during validation that already loops over the script.
To be fair, we don’t need 32 bytes. The next step after 20 bytes hash (160 bits, or 80 in case of the birthday attac) is not 32 bytes (256 bits or 128). There is a lot in between 160 and 256.
That is a UX question, and while I understand the goal, you may not have included the cost in your calcuation. The current cash-address algorithms won’t work for non-20-bytes bytearrays. Something new has to be designed for that. 
I’m trying to understand this issue of multiple OP_GROUP instances. Is this picture correct?
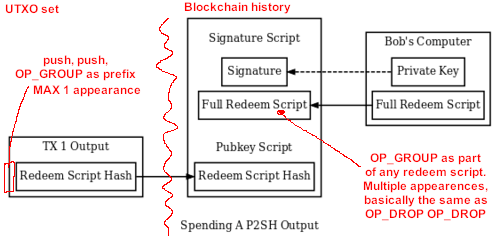
The blockchain would not even see those other instances until someone would post a redeem script, in which case there’s nothing special about OP_GROUP, it could be processed as if it was 2x OP_DROP or just ignored because it’d be cheaper, right? People can use the wide pallete of script to write whatever gibberish they want in the redeem script, so why go out of our way to give one opcode a special treatment there?
This code would recognize only 1 “prefix”, it wouldn’t allow multiple OP_GROUP to appear in the pubkey/output script as those would return TX_NONSTANDARD, right? So other OP_GROUPs could appear only in the signature/redeem script – and they can’t make much problems there, they even allow compressing a 2x pop operation.
If my understanding is correct, then Group Tokenization could be made to work by allowing this in the pubkey/output script: OP_PUSHDATA2 0x20 <arbitrary 32 bytes> OP_PUSHDATA2 0x08 <arbitrary 8 bytes> OP_DROP OP_DROP OP_HASH160 OP_DATA_X <redeem Script hash> OP_EQUAL and then the consensus code would set rules on that data and fail the tx if it doesn’t fit into group semantics. This would avoid a new opcode but it would be uglier.
PS isn’t VarInt sort of “double wrapping” the data? First you tell the push opcode how many bytes to expect, and then inside those bytes you again use a byte to tell the user how many bytes to expect. If we stored group data info directly into TX format, then varint would make sense. But since the push OP already provides a data size feature, why again introduce the size one more time into the data being pushed?
PPS
What do you mean by this, something new designed for what purpuose? Tokens can be sent to any existing address, we wouldn’t need a new format. We will need a standard (user/wallet layer) to present tokenIDs in human-readable format, link them to a ticker. There is word on that in the doc, Appendix C, but it is outside the scope of this CHIP. Maybe it’s for another CHIP to recommend a standard way to track token metadata across wallets.
To avoid the long discussions from becoming too long, I’ll open issues on the CHIP repo with the change requests.
Here is the first.
Your question:
This question is very confusing because Andrew wrote this:
If nobody addresses a group-id, then why would Andrew write this? There is a consusion somewhere. Maybe you can spot the origins.
Good idea, we can keep everything more tidy that way and anyone interested on the status of certain issues can visit the relevant threads. I’ll make a list here of all that were mentioned in the discussion above, thanks for creating those issues!
Rewriting technical part - done and closed. Todo: write about advanced features (subgroups, hold BCH, covenant) Done.
Include specification in the CHIP body - done and closed
Treatment of multiple OP_GROUP opcodes - discussion ongoing
Using VarInt for data values - discussion ongoing
Encoding of the quantity | flags variable - discussion ongoing
Limit the size of subgroup - discussion ongoing
Yeah, let me know when the issues are fixed. 
Ok so here is some feedback. It would be REALLY NICE if it were possible to read the group data from a scriptOutput without having to really know anything about bitcoin script.
I’m thinking in particular making it as easy as possible for middleware that needs to process tx’s and extract out the group_id and quantity info from a UTXO. This means it would be nice if the special GROUP txo’s had a prefix byte, and the real script data that the interpreter in bitcoin interprets comes later. This way it’s as if we are “Extending” the scriptoutput field in bitcoin tx format and packing new data fields specific to group there.
Right now we have:
<groupid> <quantityorflags> OP_GROUP OP_DUP OP_HASH160 <pubkeyhash> OP_EQUALVERIFY OP_CHECKSIG
Would be nice if the BINARY data inside the scriptoutput field looked like this:
GROUP_PFX_BYTE <groupid> <quantityorflags> <EncapsulatedScriptData>
<EncapsulatedScriptData> then expands to the real script data you send to the script interpreter, which is just normal scriptOutput for that utxo:
OP_DUP OP_HASH160 <pubkeyhash> OP_EQUALVERIFY OP_CHECKSIG
When bitcoind sees GROUP_PFX_BYTE it knows that the real script data comes later in this txo – it reads the next fields of data as group information, then kicks off the interpreter on the <EncapsulatedScriptData>
When middleware that normally doesn’t really interpret scripts sees GROUP_PFX_BYTE it knows that the next 2 data fields are what it cares about: group_id and quantity. Everything later is script data blob that it can ignore.
This way GROUP lives on its own layer “outside” the bitcoin script data – and has nothing to do with bitcoin script. It makes it a little bit clearer to code that processes tx’s on the binary format level what to throw away, what to pay attention to, etc.
In short – it irks me a little bit that code like Fulcrum that processes tx’s now has to worry about interpreting bitcoin script in order to extract out group_id info. Would have been easier had it been living outside bitcoin script, and had its own prefix byte to denote that fact, and so it’s just on its own layer of data encapsulation.
Not a huge deal – just a suggestion.
I think that’s possible with the current scheme. Group consensus code looks at a particular OP_GROUP at a particular place in the script, and expects particularly formed pieces of data. If there’s no such pattern then it’s not a group output and is just an ordinary BCH output with whatever script, and that script may or may not include instances of OP_GROUP but they’re supposed to be benign as they don’t really do anything when processed by the Script machine itself.
Would you need to code in new features into code to recognize and deal with this prefix? My understanding is that OP_GROUP was intended as a kind of soft prefix which can also valid part of your EncapsulatedScriptData so you don’t need to touch Script and TX serialization other than implementing a simple opcode which does pretty much nothing when used in the “wrong” place.
Only when placed in the right place it becomes a “magical” opcode and activates the group consensus code so the special meaning to OP_GROUP is given by the self-contained group consensus code if and only if any output matches the “prefix” pattern i.e. it’s the first set of instructions in the script. If it doesn’t match the prefix pattern, it’s simply ignored by group code and processed by existing BCH code similarly to OP_DROP. As far as Script is concerned OP_GROUP just pops 2 elements instead of 1 and does nothing.
I hope I’m making sense, if I got something wrong @andrewstone can correct me. Anyway, I think we need to update the spec so this behavior is more obvious.
You wouldn’t need to touch tx serialization or anything in what I am suggesting. To code that doesn’t know any better, it just looks like a script it doesn’t understand.
This is the same situation you have now with what’s being proposed.
Only when placed in the right place it becomes a “magical” opcode and activates the group consensus code so the special meaning to OP_GROUP
Yes and I’m suggesting that magical place be as the first byte. And that there should be no mixing between script data and the token stuff. It just seems cleaner.
Putting the token data inside script is just kinda gnarly…
Extracted summary:
A lot of work and research has gone into the technical specification of this CHIP. However, in its current form, GP does not think it is simple / minimal enough to be considered for acceptance into the network. Furthermore, important sections about costs, risks and alternatives are incomplete or have wrongfully been asserted as non-existent. GP would like to see a minimum viable change isolated from the current large scope, and then a deeper evaluation of costs, risks and alternatives.
A lot of work and research has gone into the technical specification of this CHIP.
Thank you for recognizing it. However, I don’t subscribe to the labor theory of value so that labor will have been meaningless if doesn’t achieve the desired outcome and impact which is to grow the ecosystem and BCH value, and with it my net worth as well I’m not interested in participation trophies, I’m interested in 10x gains on BCH. While other proposals also increase the likelihood of a 10x, I felt that this one was neglected and has lots of potential so that’s where I’m putting my energy, it all adds up. The best way to predict the future is to make it happen.
However, in its current form, GP does not think it is simple / minimal enough to be considered for acceptance into the network.
Is there a broadly accepted simpleness / minimalism criteria for consensus layer changes? How do we quantify this requirement? Lines of code? Number of script ops required to perform token operations? If it’s a matter of opinion, then I simply disagree and will wait for other stakeholders to weigh in.
Furthermore, important sections about costs, risks and alternatives are incomplete or have wrongfully been asserted as non-existent.
Addressed below.
GP would like to see a minimum viable change isolated from the current large scope
Minimum viable change would be only the BATON, MINT, and MELT authorities. Even with only those, a lot can be done (tokens, atomic swaps, token CoinJoin/CashFusion), as demonstrated in the examples section.
However, covenants are really useful and would benefit from other Script opcodes as soon as they’re activated e.g. covenants would benefit from the introspection CHIP because it enables an entry into the covenant. Reducing the scope would mean we push that feature far away into the future. Why would we want to do that? The feature is cheap, enabled by a simple optional constraint on top of the above mentioned “base”.
How do we quantify “large”? If it’s a matter of opinion, then I simply disagree and will wait for other stakeholders to weigh in.
It is unclear what the author means with “The market demands smart cash but, with Ethereum, it got smart contracts disguised as cash”. What are the practical differences between smart cash and smart contracts disguised as cash?
Accepted, I’ll reword.
A strong statement such as “the market demands X” needs some actual backing.
How’s this: All Tokens | CoinMarketCap,
paired with the price appreciation of the “main” coins on whose blockchain those tokens exist.
If that is not sufficient, what kind of evidence would be satisfactory?
The noun/verb analogy is confusing and creates more questions than it answers.
Accepted, I’ll reword.
The only listed cost is “possible implementation errors”. At the very least this change will add complexity to potential future upgrades since future updates will need to account for both BCH and tokens.
This is vague so hard to address, let’s try and work it out.
Is BCH balance checking adding complexity to potential future upgrades? Token logic is in the same class as that. It just works, regardless of upgrades in other parts of the code.
Even if we only get what’s currently proposed in the CHIP and never ever upgrade it why would some future unrelated upgrades need to account for it?
Here are some changes that would NOT be affected by having group tokens:
and some that might be:
There are likely other costs that are not mentioned / researched.
Another vague statement. What kind of costs are you expecting to find in some code performing simple arithmetic operations and a few IF statements? What kind of research are we looking for here?
It’s not clear which features are part of the current proposal.
All of the features in the CHIP. What’s described in technical description is also formalized in the specification. There’s a dedicated section for future upgrades, which is not part of the current proposal but for information only.
If all features are included, this is much more than a minimal viable proposal, and should be separated.
I did not see a convincing argument why we need to limit ourselves to a minimal viable proposal.
The authority system seems very complex.
Complex by what criteria? It’s no more complex than adding up balances, the only difference is that instead of summing up token amounts we’re summing the quantity field using a logical OR i.e. sum |= qty and then placing a few logical rules on that sum. I’m surprised by experienced developers classifying this as “complex”. On the outside, both token amount and token authority UTXOs are the same, and everything that works with BCH outputs work the same with both token amounts and authorities.
So these alternatives (e.g. CashTokens, SLP, SmartBCH) should still be evaluated.
Accepted, will add.
An evaluation of alternative versions of GROUP tokens could also be added.
Do you mean some historical proposals, or different scopes of the current one? The current authority system really made this “click” with me as an elegant solution. I didn’t look deeply into historical proposals but I understand that those had problems because they used a different way to perform management ops so I was not interested in that. What value would there be to entertain obsolete proposals? I actually got an opposing comment when I tried to explore an alternate design approach in the CHIP.
The evaluation of alternative rollout approaches is a good addition.
Thanks!
it does have serious implications on the core functioning of the network. So security considerations need to be further specified.
It’s vague, what kind of considerations are you looking for here? The network continues to function the same, but we could end up having lots of BCH dust UTXOs which would carry tokens, and with them economic value. We can even have lots of dust UTXOs now, but there’s no utility in having them other than to spam the network. It would cost only 5460 BCH (about $3m) to spam the network with 1b UTXOs. I understand that there are entities who’d like to see BCH fail, so why haven’t they attacked BCH in such a way? Maybe because they know it would be a futile attack because:
If it will not be an attack but the aggregate market demand for tokens which ends up locking 5m BCH into 1T token UTXOs then I will be celebrating that on my yacht which I will have bought for 1 BCH.
Besides the workload increase for node developers, the only listed cost is that “BCH will get more adoption”.
What if it really is the only one? How hard do I have to try find others before giving up? We cannot invent problems to satisfy the expectation that there have to be problems. I don’t like complexity, that’s why this proposal appealed to me in the first place, because it so simple, cheap, and easy to reason about. Lots of potential impact at a low cost – yes please!
If you can think of any other costs then I’ll be happy to either dispute them or add them to the list if I fail to dispute them. Maybe this one should be turned to (-) for some stakeholders: “This functionality will enable competition from within our ecosystem.”
Please notice that I, as a stakeholder, have found several problems too which go unsolved.
There must be a big confusion about the general process. I wrote more on it here: A process towards acceptance of Bitcoin Cash Improvement Proposals.
Tl;Dr: It is the responsibility of the proposal owner to convince the ecosystem.
Those are non-blocking and clearly defined and I believe we can successfully resolve those. Even though I may not always fully agree with you, I value your feedback and admire your positions on many other topics.
I’m hoping to convince more and more people, but there will always be some where it may be in their interest not to be convinced. Ecosystem is big and wide, and I hope it will become bigger and wider, and not one single entity represents it. If I fail to convince, giving up is also an option.
Meanwhile, something unexpected happened which blew my mind – a stakeholder of the “whale” class, Marc De Mesel, has signaled his support by giving this same response a $1k upvote.
As a developer and co-founder of Mint SLP https://mintslp.com/
I believe miner validated tokens is a smart step in the right direction! The Group Token proposal seems like a big improvement over SLP.
Thank you @andrewstone and others involved for working on and pushing this feature into BCH.
I hope the community can come together to support the Group Token proposal or something similar! You have my support for what it is worth!