
I will be doing a Podcast episode with @bitjson this Friday to discuss in detail, I believe he plans to time it somewhat with a release of an updated version, so you can look forward to that.
4 Likes
Hey everyone, thanks for your patience while I was working on this over the past few months.
I’m still working on cleaning up a PR to the CHIP, I’ll hopefully have something up shortly. There was some related discussion in Telegram recently, so just wanted to post some notes here too:
- My 2021 benchmarks considered hashing to be much more relatively-costly than other operations, so I had misjudged the impact of increasing the stack item length limit on the cost of other operations. Hashing is still generally the worst, but there’s another class of operations that realistically need to be limited too.
- However: it turns out that simply limiting cumulative bytes pushed to the stack is a nearly perfect way to measure both computation cost and memory usage. I’m just calling this “operation cost” for now.
- O(n^2) arithmetic operations (MUL, DIV, MOD) also need to be limited: it works well to simply add
a.length * b.lengthto their “cost”. - Hashing I still think is wise to limit individually, but should also be added to cost (right now I’m using the chunk size of 64 * hash digest iterations)
- And then to avoid transactions being able to max out both the operation cost and sigchecks, we’ll want to add to the operation cost appropriately when we increment sigchecks. (I’m still benchmarking this, but simply adding the length of the signing serialization seems very promising, and even resolves the OP_CODESEPARATOR concerns).
I’m still working on the precise multiplier(s) for operation cost (the goal is to derive from just beyond the worst case of what is currently possible, maybe even reigning some things in via standardness), but it will simply be “N pushed bytes per spending transaction byte”.
I also now agree with @tom’s earlier ideas that we don’t need the 130KB limit or even to track stack usage at all. Limiting the density of pushing to the stack is both simpler and more than sufficient for limiting both maximum overall memory usage as well as compute usage.
I’ll post a link here as soon as I can get a PR to the CHIP open. For now you can review the benchmark work for:
5 Likes
Also want to share logs from a recent benchmark run here (and also attaching a formatted image of just the BCH_2023 VM results for convenience):
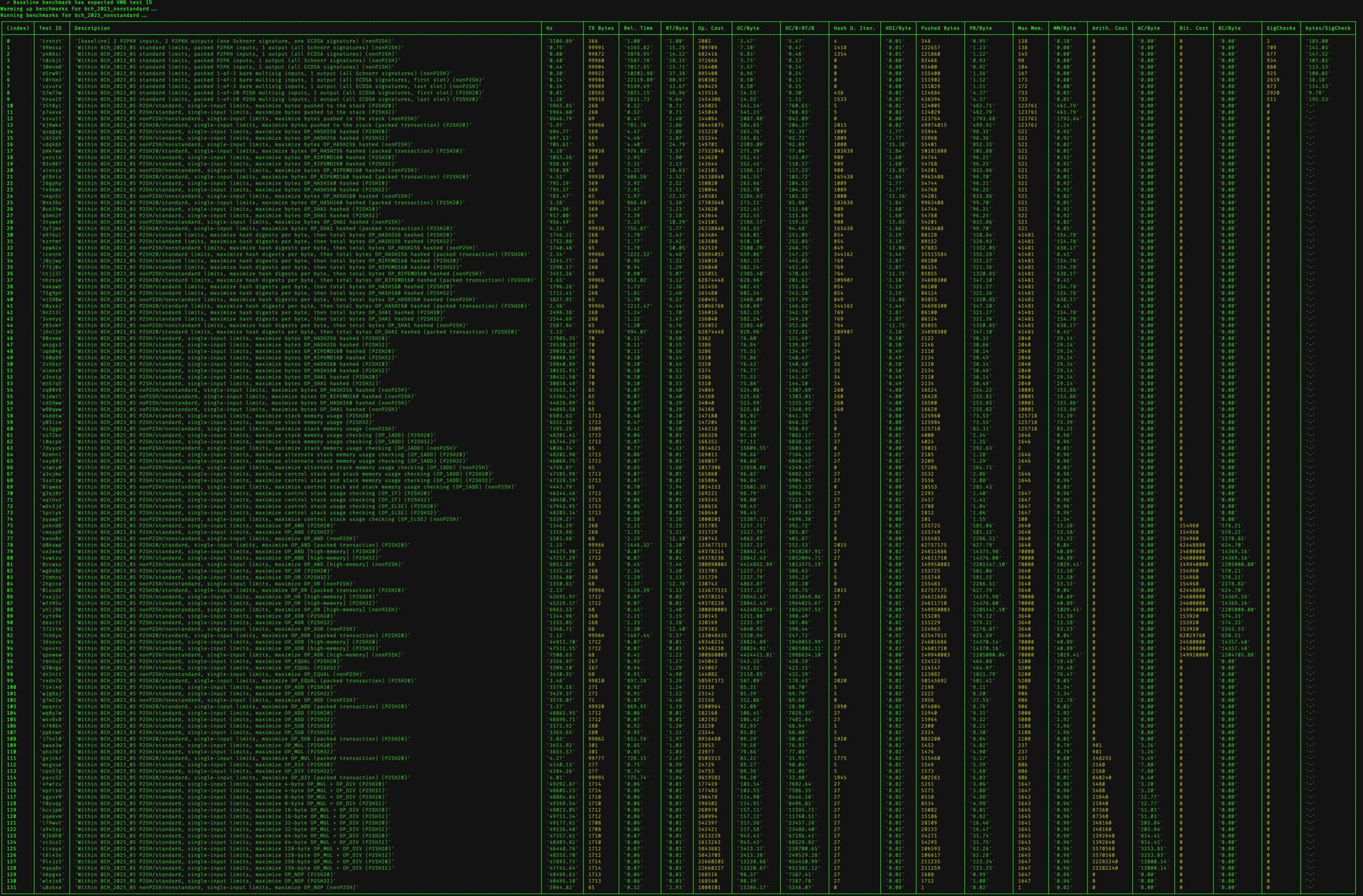
The benchmarks use Libauth’s bch_vmb_tests (BCH Virtual Machine Bytecode) file format described in more detail here. We mark some tests as benchmarks by including the string [benchmark] in their description field.
One of the benchmarks (trxhzt) is also marked with the string [baseline]; that is the most “average” possible transaction, including 2 P2PKH inputs (one Schnorr signature, one ECDSA signature), and 2 P2PKH outputs, useful to illustrate the expected baseline “density” of computational cost in transaction verification (validation time / spending transaction byte length).
In general, our goal is to tune limits such that valid contracts do not significantly exceed this “relative time per byte” (RT/byte) density. There are currently other standard transactions with higher RT/byte values (see 1-of-3 bare legacy multisig, first slot, but note that the Libauth results reflect Libauth’s lack of signature or sighash cache; BCHN’s results here are much closer to baseline).
Libauth’s implementation of both the VM and benchmarking suite print out quite a bit more information than any other implementations need: single-threaded validations-per-second on the current machine (Hz), Relative Time (Rel. Time), Operation Cost (Op. Cost), Hash Digest Iterations (Hash D. Iter.), Pushed Bytes, Max Memory (Max Mem.), Arithmetic Cost (Arith. Cost), Bitwise Cost (Bit. Cost), and SigChecks (according to the 2020 upgrade spec). Each of these also has a column where they are divided by transaction byte length to provide relative densities. These columns are useful for understanding what is happening and designing new benchmarks, but other node implementations only need to determine RT/byte to validate their performance across all kinds of contracts.
You’ll also see some outdated benchmarks from previous iterations of the proposal (before we began constraining compute/memory by density of pushed bytes) – I’ll delete those from the final set soon, but wanted to first publish them and share the results to make it easier for others to validate that counting pushed bytes is a more reliable approach.
3 Likes
And thanks again to @BitcoinCashPodcast for having me on to talk about this work yesterday. We covered some more detail and some of the historical context for the current limits here:

There is more benchmarking to do, but we now have a solid enough set of tests to make confident statements about worst-case performance. Next I’d like to work with other node implementations to get benchmarking implemented and verify that this latest approach is the right direction.
When we’ve figured out the important constants and locked things down a bit more, I plan to continue building out benchmarks until we have a full combinatorial set of tests covering all opcodes (and every evaluation mode of the more complex operations) that can become part of continuous integration testing for all BCH implementations.
7 Likes
Hi all,
The CHIP is updated! This reflects all the research since February, feedback and questions are appreciated:
A TL;DR of the whole CHIP if you’re looking at a Satoshi-derived C++ implementation like BCHN:
-
MAX_SCRIPT_ELEMENT_SIZEincreases from520to10000. -
nOpCountbecomesnOpCost(primarily measures stack-pushed bytes) - A new
static inline pushstackto matchpopstack;pushstackincrementsnOpCostby the item length. -
if (opcode > OP_16 && ++nOpCount > MAX_OPS_PER_SCRIPT) { ... }becomesnOpCost += 100;(no conditional, covers push ops too). -
case OP_AND/OP_OR/OP_XOR:adds anOpCost += vch1.size(); -
case OP_MUL/OP_DIV/OP_MOD:adds anOpCost += a.size() * b.size(); - Hashing operations add
1 + ((message_length + 8) / 64)tonHashDigestIterations, andnOpCost += 192 * iterations;. - Same for signing operations (count iterations only for the top-level preimage, not
hashPrevouts/hashUtxos/hashSequence/hashOutputs), plusnOpCost += 26000 * sigchecks;(andnOpCount += nKeysCount;removed) -
SigCheckslimits remain unchanged;nHashDigestIterationsandnOpCostalso get similar density checks. - Adds
if (vfExec.size() > 100) { return set_error(...
Compared to v2.0.0 of the proposal:
- There’s no need to check total stack memory usage after each operation, limiting pushed bytes is both simpler and more effective.
- The limits are no longer static per-input, they’re all density-based like
SigChecks. (Of course, they were always density based, but now we set them explicitly rather than as an implied result of worst-case transaction packing. )
)
And that’s it.
The constants are all derived from existing limits and (re)calculated as densities. In essence, this carries forward the performance testing done in the 2020 SigChecks spec, and also reduces worst-case hashing costs by an order of magnitude, setting a lower standard limit at the “asymptotic maximum density of hashing operations in plausibly non-malicious, standard transactions” (from Rationale: Selection of Hashing Limit).
So the elevator pitch is now: “Retargets limits to make Bitcoin Cash contracts more useful and reduce compute requirements for nodes.”
6 Likes
Seems this is the direction Core is going:
they don’t mention that this solves the ‘looping-cost’ problem there yet, though 
3 Likes
Improvements and enhancements for power users and advanced services are great and all, but let me remind all discussion participants that it is of  paramount importance to test this scheme and all future remaining schemes for single-threaded and multi-threaded performance.
paramount importance to test this scheme and all future remaining schemes for single-threaded and multi-threaded performance.
It could turn out that when we reach gigabyte blocks, the features implemented into the scripting engine could potentialy wreck all future cash use-case by crippling all bull the strongest CPUs if we are not careful.
Especially we should thoroughly test the performance under the heaviest possible scenarios - like gigabyte blocks filled only with the slowest possible combinations of OPcodes.
1 Like
Would love to see this happen, also BigInt, but we are at the end of August and lock in for 2025 is getting very close. Hoping to see benchmarking and other results ASAP.
2 Likes
My technical background has given me the position that an increase of VM limits is not something weird, it is more like it is overdue.
There are two viewpoints here. 1. what the script writer wants. 2. what the full node developer can give without sweating the machine.
Those two seem to not even approach each other. There is no risk of the first over-asking as the computers today are so powerful. In future that will only diverge further, in the positive sense.
My worries, in a very generic fashion, about this topic are:
- are any of the core concepts changed. For instance something that would disallow multi-threading.
Answer, as far as I can see, is no. - With more VM limits we’ll naturally also see that reflected in transaction-size. We’ll also see this greater capability reflected in more usage (more business cases become possible).
This then causes the actual blockspace for these things to become larger and that goes at the cost of simple payments. So the risk is them pushing out simple payments.
The second will continue to be a problem for some time longer, same as for cashtokens really. But so far the p2pkh transaction count is still massively larger than the ‘fancy-transaction’ count. So that’s good.
3 Likes
I have high respect for your expertise, despite our frequent battles on TG chats.
This makes me feel a little better, honestly.
That’s good.
If the new math, opcodes and VM limits cause significantly increased CPU processing requirements, but not to the point of being critical or endangering the future of the network, the way to solve the increasing blocksizes and complexity is simply create miner pricing schemes for transactions based not only on size, but on processing time/CPU usage too.
If we don’t do it, miners will do it anyway themselves, which would be a less preferable option (because they will most likely keep it closed source).
I think this functionality is also overdue BTW, /someone should probably code it.
3 Likes
The CPU processing / byte will stay under the current baseline. That means that no matter the TX size or block size, it all scales up just fine.
Maybe not. Consider my chainwork oracle idea, with current state of VM I would need to make a 3000 byte multi-input TX for every update of the oracle.
With new VM & Int limits that would come down to maybe 200 and would fit in 1 input.
What we could see is more transactions of reduced size, resulting in more total use of the network capacity. Today I was reminded of the Jevons paradox:
when technological progress increases the efficiency with which a resource is used (reducing the amount necessary for any one use), but the falling cost of use induces increases in demand enough that resource use is increased, rather than reduced
so if there’s demand for these applications that now need 2000 byte TXs and would later need 200 byte TXs, we could expect more of them, so more fee revenue for the miners!
Miners want more fee-paying bytes, that’s all. The CPU cost of this or that opcode or this or that TX type is kinda irrelevant because it’s not their bottleneck, pool node validates it all fast enough not to matter.
But this could lead to perverse incentives: if VM optimization means that a 2000 byte TX can do the same thing with 200 bytes, that would mean 1800 less fees, right? So miners might have the incentive to lobby to keep our VM as inefficient as possible.
Unless they’d learn to understand the above Jevons paradox, and see that long-term it will bring them even more fee-paying bytes.
1 Like
Be wary, this is only an assumption.
@bitjson said to me that some combination of opcodes (apparently order matters!) produce significantly higher CPU usage than other combinations.
Is it?
Let’s say one day, somebody constructs a “seemingly innocent” transaction that uses 100x the CPU time it should use and then fills a whole 1GB block with a copy of it.
I am sure miners wouldn’t like their nodes being slowed down to a crawl so they cannot process blocks for 2 minutes…
Yup, which is why the concept of CPU density is important (CPU cost / byte) and why we introduced SigOps counter, so you can’t fill a 1 GB block with 1B sigops and make nodes choke on it.
Same logic is now being extended to other opcodes.
1 Like
Nice! 
Since when is this a thing?
Can you point me to the discussion or a commit?
Everything is looking good so far  . I am at peace.
. I am at peace.
…but if anything goes seriously wrong, I will be the “I told you so guy” in 5 years.
1 Like
Hi everyone, thanks for all the messages and feedback. I just pushed up two small but substantive corrections:
- Correction to density formulas to base them solely on input length (Rationale: Use of Input Length-Based Densities and Rationale: Selection of Input Length Formula)
- A correction to the arithmetic operation cost limit (Rationale: Inclusion of Numeric Encoding in Operation Costs).
Thanks again to @cculianu for encouraging me to reconsider input length-based densities rather than based on transaction length. Vastly superior, now documented in rationale.
I also want to highlight that the operation cost change is a great example of our defense in depth strategy working as intended. 
Basically: after some benchmarking of bigint ops (up to 10,000 bytes) on Libauth and BCHN, I realized we shouldn’t “discount” something (VM number encoding) that should be very cheap on well-optimized implementations (BCHN) but is a hassle to optimize in other implementations. (If we make it “cheap” because it can be cheap, we’ve forced all future implementations to implement the optimization. So now this CHIP always takes the more conservative approach.)
Anyways, it’s notable that even in the worst case, this correction only slightly improves the alignment between the consensus-measured “operation cost” and the real-world runtime performance on a non-optimized VM (worst case less than 2x the expected validation time).
If our limits were more naive, for some implementations this issue could easily produce an order of magnitude difference between cost and real-world performance (and if it were bad enough, maybe an implementation-specific exploit). However, our limits are also designed to catch unknown, implementation-specific issues (just clarified this more in rationale):
Because stack-pushed bytes become inputs to other operations, limiting the overall density of pushed bytes is the most comprehensive method of limiting all sub-linear and linear-time operations (bitwise operations, VM number decoding,
OP_DUP,OP_EQUAL,OP_REVERSEBYTES, etc.); this approach increases safety by ensuring that any source of linear time complexity in any operation (e.g. due to a defect in a particular VM implementation) cannot create practically-exploitable performance issues (providing defense in depth) and reduces protocol complexity by avoiding special accounting for all but the most expensive operations (arithmetic, hashing, and signature checking).
This was some nice unexpected validation of our approach, so wanted to highlight it here.
3 Likes
This is definitely a possibility, though I think we should try to avoid it if possible: right now we’re in the enviable position of not having to even account for computation in the “pricing” of transactions. That means transaction fee-rate checking can occur at a higher level than the level which validates the VM bytecode in TX inputs. It probably wouldn’t be a huge issue in practice to muddy TX fee-rate checking with VMB evaluation, but avoiding that makes the most of our architectural advantages over systems like EVM (which are architecturally forced to incorporate computation into pricing).
That said, I certainly see a place for a future upgrade which offers a higher per-byte budget based on the actual fee-rate paid, so e.g. fee rates of 2 sat/byte would get a budget slightly higher than 2x the 1 sat/byte budget (to encourage economizing on bandwidth rather than forcing extremely expensive computations to pad their contract length). But I avoided that additional complexity in this CHIP to cut scope. Once people are creating significant contract systems using ZKPs or homomorphic encryption, the topic can be revisited by a future CHIP, ideally with some empirical evidence of how much bandwidth the network would save by offering those users more “compute” for a higher fee-rate. As it stands, authors would simply need to re-arrange cross-input data or pad their contracts with extra unused bytes to afford a higher budget, and we’ll be able to see those behaviors on chain. (Note that it’s also possible a future CHIP will choose simply to increase the base compute budget rate offered for 1 sat/byte transactions, especially if validation performance continues to improve at a faster rate than required by block size scaling.)
Anyways, thanks for this comment @ShadowOfHarbringer, I added a bit more about it to this rationale section:
Finally, this proposal could also increase the operation cost limit proportionally to the per-byte mining fee paid, e.g. for fee rates of
2satoshis-per-byte, the VM could allow a per-byte budget of2000(a2.5multiple, incentivizing contracts to pay the higher fee rate rather than simply padding the unlocking bytecode length). However, any allowed increase in per-byte operation cost also equivalently changes the variability of per-byte worst-case transaction validation time; such flexibility would need to be conservatively capped and/or interact with the block size limit to ensure predictability of transaction and block validation requirements. Additionally, future research based on real-world usage may support simpler alternatives, e.g. a one-time increase in the per-byte operation cost budget.
3 Likes
Next Steps
We now have two implementations (of both Limits and BigInt) – BCHN (C++) and Libauth (JS/TS) – with extremely consistent results and relative performance differences in exactly the places we would expect based on complexity analysis (in each case, the spec takes the most conservative approach to assigning operation costs).
We learned a bit more in bouncing the spec between JS and C++. I’m fairly confident now that further changes to the spec will be minor, so implementation work in other node implementations won’t have to go through the same churn. This is also an opportunity to verify empirically that we’ve gotten everything right.
To “preregister” my planned approach to evaluating whether or not we got these CHIPs right: as we get performance benchmark results from each implementation, I’ll rank-order all results by their worst performance-to-opCost ratio for the worst-performing implementation on the benchmark in question. The worst case should be within the same order of magnitude as worst-case 1-of-3 bare multisig (BMS), and ideally it should never exceed 200% 1-of-3 BMS performance-to-opCost.
Given the results from Libauth (shared last month) + Calin’s BCHN results from last week, it seems this will be proven empirically, but I’ll wait to get complete results (and any more spec feedback) from all other implementations before claiming we’re done.
So: We need help getting patches and then benchmark results for all other node implementations. I’m reaching out to all the teams today, and I’m happy to hop on calls to help teams ramp up quickly or answer any questions. This is also the perfect time to get wider feedback on if any spec details can be further simplified to make implementation easier in other languages (JS and C++ gave us a pretty wide view already, but another round of implementation feedback should give us more confidence that we’re not leaving any more protocol simplifications on the table.)
In the meantime, I’ll revise all the benchmarks again for this latest iteration (hopefully one last time  ) and make some pretty graphs that I can keep updated as we get results from other implementations. I’m also hoping to knock out the stretch goal of expanding our new test suite to incorporate the old
) and make some pretty graphs that I can keep updated as we get results from other implementations. I’m also hoping to knock out the stretch goal of expanding our new test suite to incorporate the old script_tests.json such that it can be fully deprecated.
When we’re done here, we should have both an expanded set of functional test vectors and an extremely comprehensive set of benchmarking test vectors that can be used to reveal any performance deficiencies in any VM implementation.
5 Likes
I agree, however this is now.
I was talking about a possible future. If computations become more expensive in the future, but not dangerously expensive, including a simple algorithm with some kind of ratio for calculating the cost of a TX the miner bears + TX fee is a natural thing to do.
1 Like