Makes sense, please let me know if you come across items we need to address in the CHIP 
You can technically achieve some compression of iteration logic with OP_EVAL, but loops are generally much more efficient, e.g. merkle tree validation or aggregations like “sum all input values”.
For a good direct comparison, see the VMB tests for each CHIP (loops, eval).
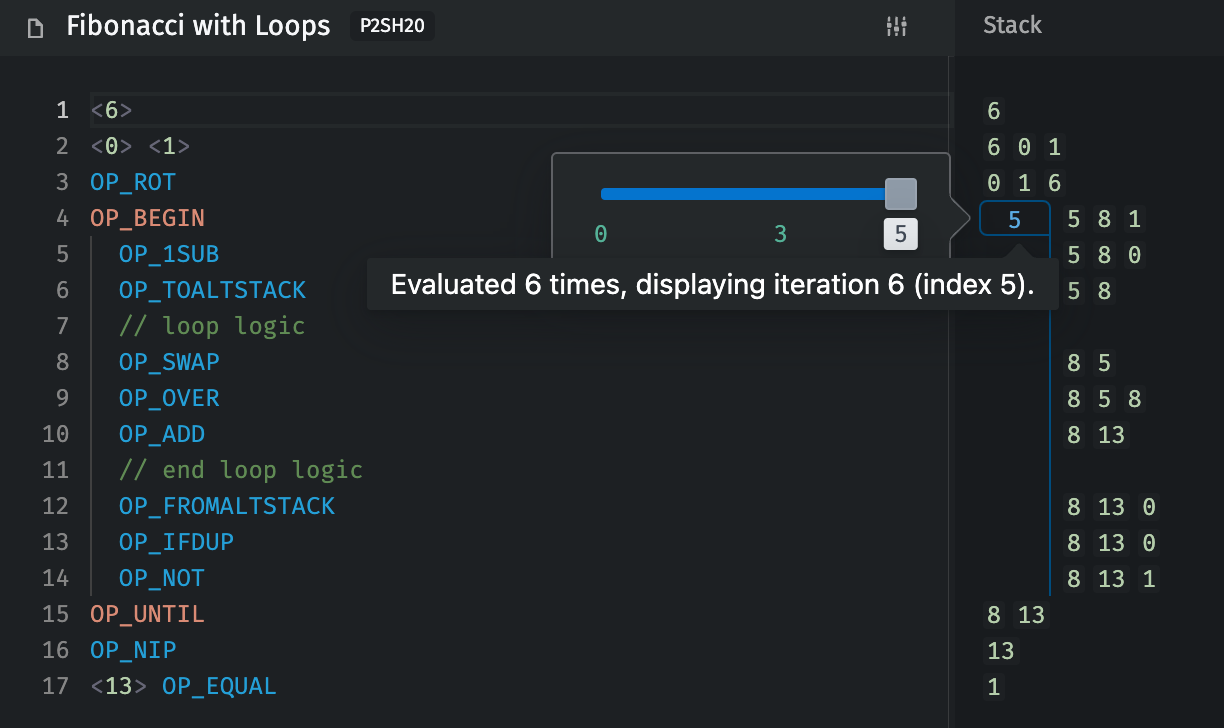
OP_BEGIN/OP_UNTIL: Fibonacci to 13
- Unlock:
<6>
- Lock (16 bytes):
<0> <1> OP_ROT OP_BEGIN OP_1SUB OP_TOALTSTACK OP_SWAP OP_OVER OP_ADD OP_FROMALTSTACK OP_IFDUP OP_NOT OP_UNTIL OP_NIP <13> OP_EQUAL
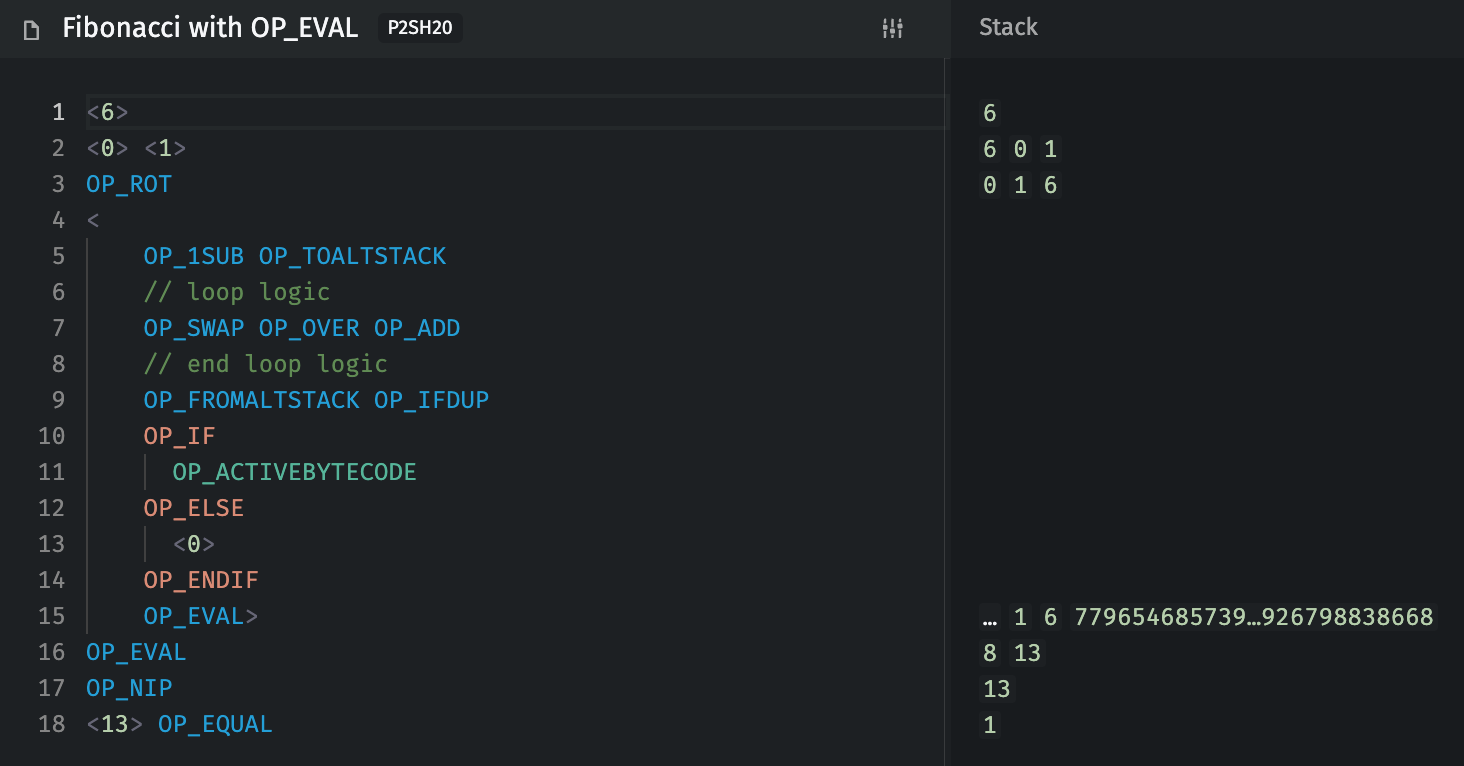
OP_EVAL: Fibonacci to 13
- Unlock:
<6>
- Lock (21 bytes):
<0> <1> OP_ROT <OP_1SUB OP_TOALTSTACK OP_SWAP OP_OVER OP_ADD OP_FROMALTSTACK OP_IFDUP OP_IF OP_ACTIVEBYTECODE OP_ELSE <0> OP_ENDIF OP_EVAL> OP_EVAL OP_NIP <13> OP_EQUAL
And here’s link to open these scripts in Bitauth IDE →
Comparison between OP_EVAL and Loops
You can see that OP_ACTIVEBYTECODE + internal conditionals allow us to emulate loops with recursive OP_EVAL, but it requires some overhead (larger transaction sizes), is often harder to review, and cannot iterate beyond 100 without some sort of “trampoline pattern” to limit control stack depth. (So OP_EVAL is even worse for >100 iterations, e.g. summing all inputs in large transactions.) Depending on the length of the iterated code, the overall cost of pushing evaluated code can also accumulate very quickly and make otherwise-reasonable things impractical (esp. aggregations from all inputs/outputs).
On the other hand, only OP_EVAL can most efficiently “compress” any shape of contract, esp. common functions called in disparate locations. While you can technically wrap your whole contract in a giant loop + (ab)use conditional logic to activate and deactivate various code snippets at the right moment(s), that setup is going to produce quite a bit more overhead than simply calling functions in the right locations.
Summary
OP_EVAL and loops each have their strengths, and they’re often better together.
Loops are ideal for iteration, and OP_EVAL is ideal for compression of all other code sequences longer than 3 bytes.
I’ll also add that logistically, it’s quite a bit easier to implement both Loops and OP_EVAL at the same time: each requires modification to the control stack + carefully testing and benchmarking the VM’s control flow behavior(s) for performance regressions. (Though thanks to the VM Limits upgrade, we already have a very strong benchmarking suite for this purpose.)




 ed the post) that the analogy still isn’t accurate: I see a great variety of uses for “3rd party plugins” across multiple interpretations of that phrase.
ed the post) that the analogy still isn’t accurate: I see a great variety of uses for “3rd party plugins” across multiple interpretations of that phrase.