In Bitcoin Cash we have today efforts underway that try to define a system of “templates”, whic are close to libbitauth templates.
The core features aimed at is that normal users can use this library of pre-defined ASM to build their transactions on top of.
Adding any sort of eval/exec to this mix allows those templates to reference library code. Which I’m sure will happen, as NPM shows, people are doing that kind of optimizations because we are mostly lazy beings. Nothing wrong with that.
The “untrusted” concept is thus absolutly relevant in the wider scope of things.
Using either proposal you can get that code from another output using introspection. But that code may not be vetted as well as it should have been. Which makes it untrusted.
The basic concept of either op-eval/op-exec both allow the unlocking script to have a push with that code, absolutely qualifies as untrusted if you don’t go through the extra steps of validating it.
So, in short, the idea that we need not add (free!!!) protection rules because there is no way to mistakingly end up running “bad” code in your transaction is naive. Nobody downloads plain executables from the Internet either, right? In reality they do, virus’ protection companies exist. That’s the reality we need to operate in.
Wallet bugs are certainly possible. Please don’t dismiss that as a problem that doesn’t exist or can be ignored.
So what? You can replace a .dll on your system with a hacker’s. Why would you do it, though? Just verify the hash so you know what you’re loading.
It’s agnostic of the source. You can just have all the pushes of eval scripts you need be part of the locking bytecode which makes them trusted and you can just call them with <N> OP_PICK OP_EVAL whenever you need them.
As the contract author - choice is yours. You want trusted? Either provide it as part of main script’s pushes (part of locking bytecode), or hash-verify if you load externally (either by unlocking data push or introspection). You want untrusted? Then refactor your contract so those come after the last VERIFY of the main’s logic you want to protect.
Script is low-level, we don’t need it to hold people’s hands.
I’ll add that OP_EVAL is a contract implementation detail, it’s purpose is compression. We can already do MAST-like constructions, we can already run “functions” (words) multiple times by duplicating the code, VM limits are already solved with or without OP_EVAL, etc.
OP_EVAL just allows contracts to be expressed in fewer bytes (often added by a compiler stage rather than by deliberate design of the contract author).
Thanks for all the great comments @bitcoincashautist – just want to note (because I ed the post) that the analogy still isn’t accurate: I see a great variety of uses for “3rd party plugins” across multiple interpretations of that phrase.
Instead, I’m saying that OP_EXEC does not add any “flexibility” or “security” in any possible case.
Stack “isolation” fundamentally misunderstands contract development. It’s an “obvious” solution at the top of a Dunning–Kruger peak.
I really want to encourage people to get past reasoning by analogy about OP_EVAL and/or OP_EXEC:
There’s no security-for-efficiency “tradeoff”
Bytecode isn’t “untrusted” or “trusted”
This is not a question of “architecture” or “philosophy”
There is no “caller” nor “callee”
It’s not a “RISC vs. CISC” thing
“higher-level” and “lower-level” are nonsensical in this context
OP_EXEC is not “isolation” nor a “sandbox”
OP_EXEC doesn’t add “flexibility”, etc.
If you care to understand the topic, drop these mental crutches. Otherwise, here’s a correct analogy:
The claim here is interesting in that what we are doing on bitcoincashresearch is designing a plaform for random people we have never met to start and do “contract development”.
That is to say, it makes zero sense to claim some future people will or will not do something. If given the chance, people will do something. I have the entire history of (computer) security to back that up.
Jason then goes and writes:
Bytecode isn’t “untrusted” or “trusted”
which doesn’t even attempt to disprove or otherwise debate the actual specific technical detailed post I wrote here. It just states the opposite like it is true.
I do agree with various other points he makes there, though.
There is no “caller” nor “callee”
It’s not a “RISC vs. CISC” thing
“higher-level” and “lower-level” are nonsensical in this context
It’s just interesting how Jason is pushing for an idea that has been rejected by the bitcoin community a decade ago. Not even touching the ideas that could fix it, because that would mean debating those ideas. Instead we see him undercutting that possible debate by repeatedly making elusive statements about how basic security would not be needed in bitcoin cash because… something fuzzy.
Anyway, this debate seems not to go anywhere where it may improve the proposal.
What are you even trying to debate that he’s supposedly “undercutting”? Some alternative you randomly came up with that solves non-existent problems?
You’ve been doing the “undercutting” by writing word salads and trying to make parallels that don’t make sense in this context and then whining and making ad-hominems at Jason who’s been very patient here and tolerant of your passive aggression.
We all learned the pattern from previous CHIP cyles: you being wrong and everyone having to spend insane amount of energy and time showing exactly how you’re wrong, all the while tolerating your annoying condescenting tone coming from the peak of Dunning-Kruger hill. I don’t blame Jason for trying to avoid such timesink here.
I don’t know if you’re malicious or incompetent, I’m leaning towards incompetence, but outcome is the same: it’s a drag.
Your posts here show how clueless you are about how smart contract stuff works and yet you posture as some authority because of some “history” and expect people to give you the attention and authority you think you deserve. Ironic above you tried to call out people’s egos all the while your own ego desperately trying to be relevant.
Sure, need to contemplate it some more since it’s an unknown unknowns kind of thing. OP_EVAL is really powerful, especially with recursion, and I start to wonder if the loops CHIP is needed or that would be syntactical sugar.
Makes sense, please let me know if you come across items we need to address in the CHIP
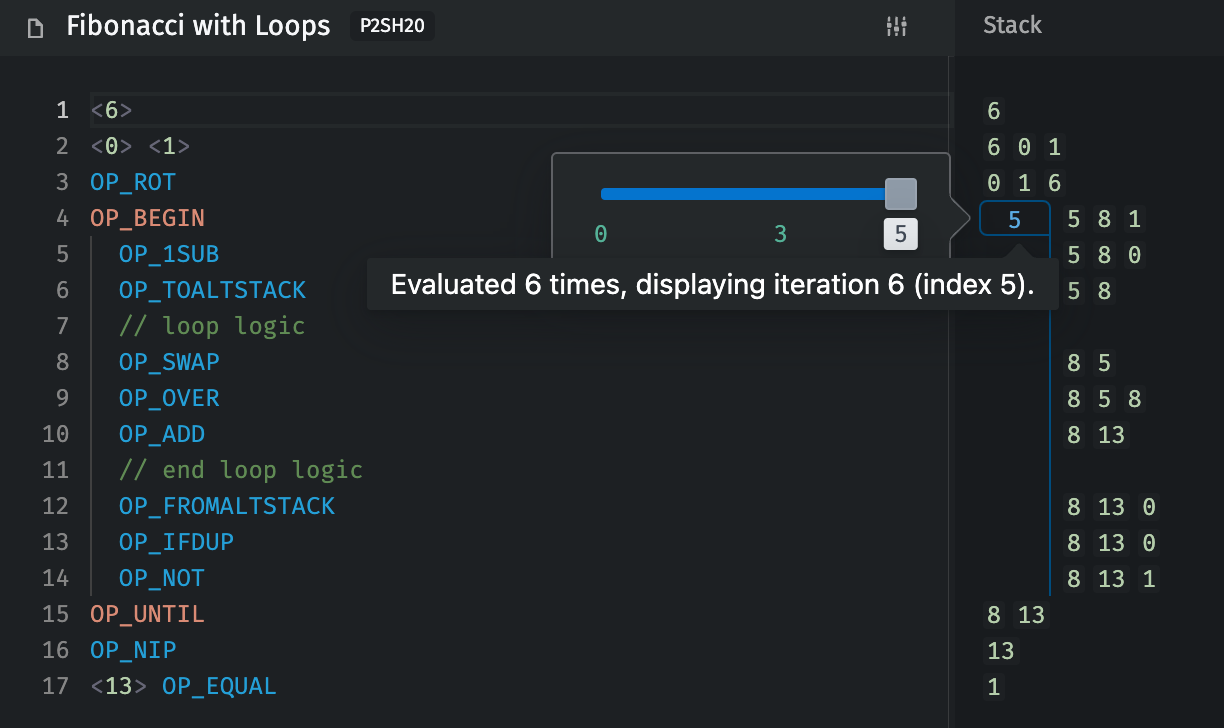
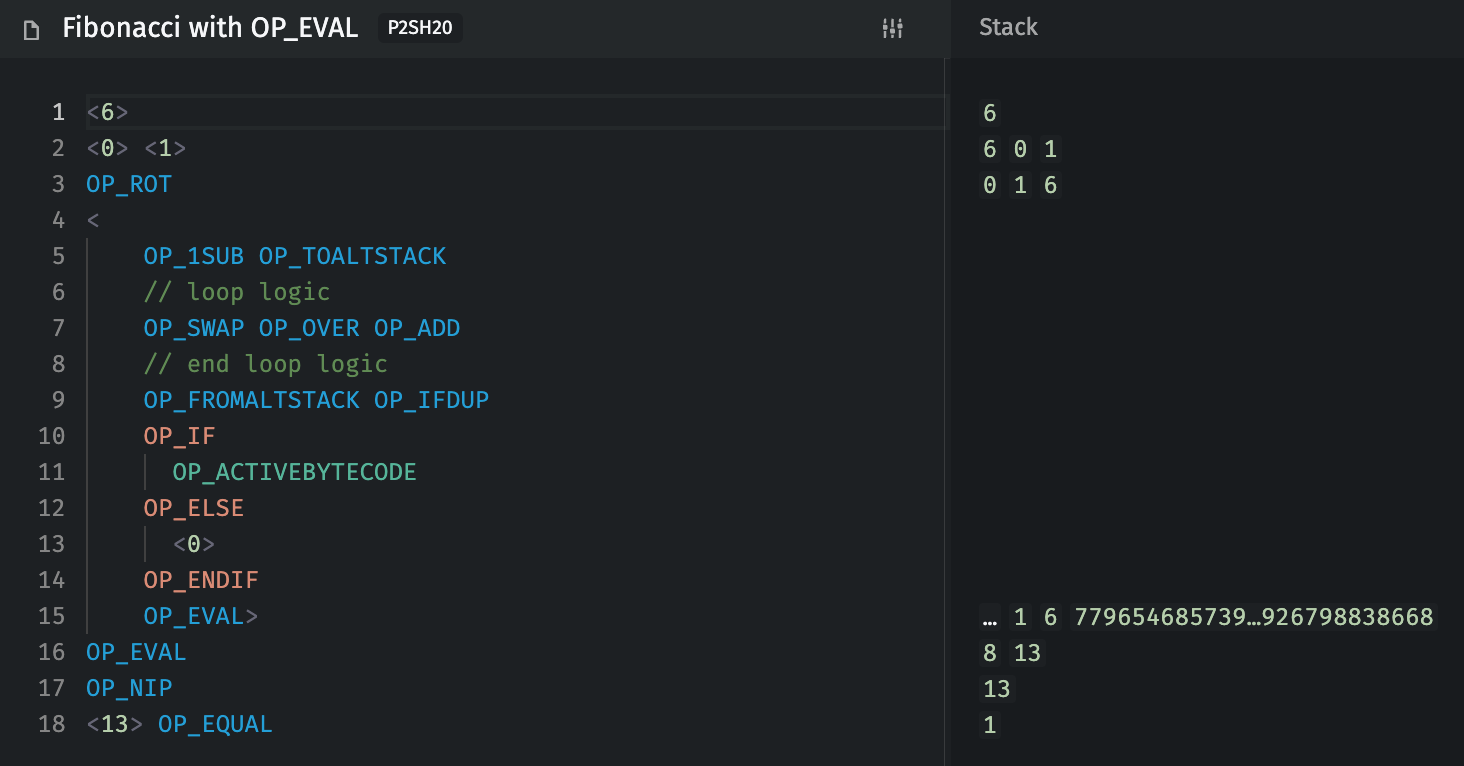
You can technically achieve some compression of iteration logic with OP_EVAL, but loops are generally much more efficient, e.g. merkle tree validation or aggregations like “sum all input values”.
For a good direct comparison, see the VMB tests for each CHIP (loops, eval).
You can see that OP_ACTIVEBYTECODE + internal conditionals allow us to emulate loops with recursive OP_EVAL, but it requires some overhead (larger transaction sizes), is often harder to review, and cannot iterate beyond 100 without some sort of “trampoline pattern” to limit control stack depth. (So OP_EVAL is even worse for >100 iterations, e.g. summing all inputs in large transactions.) Depending on the length of the iterated code, the overall cost of pushing evaluated code can also accumulate very quickly and make otherwise-reasonable things impractical (esp. aggregations from all inputs/outputs).
On the other hand, only OP_EVAL can most efficiently “compress” any shape of contract, esp. common functions called in disparate locations. While you can technically wrap your whole contract in a giant loop + (ab)use conditional logic to activate and deactivate various code snippets at the right moment(s), that setup is going to produce quite a bit more overhead than simply calling functions in the right locations.
Summary
OP_EVAL and loops each have their strengths, and they’re often better together.
Loops are ideal for iteration, and OP_EVAL is ideal for compression of all other code sequences longer than 3 bytes.
I’ll also add that logistically, it’s quite a bit easier to implement both Loops and OP_EVAL at the same time: each requires modification to the control stack + carefully testing and benchmarking the VM’s control flow behavior(s) for performance regressions. (Though thanks to the VM Limits upgrade, we already have a very strong benchmarking suite for this purpose.)
Caught up to all the great discussion here and in the ‘brainstorming EVAL’ thread.
Categories of Potential Use-cases
I appreciate the overview of categories for potential use-cases for OP_EVAL @bitjson!
Contract compression via reusable functions ( common case)
MAST-like constructions
Post-funding assigned instructions ( security theater/use-case covered by CashTokens )
User-provided pure functions ( contrived example )
From the CHIP it’s clear that OP_EVAL is proposed mainly for the ‘reusable functions’ use-case, but it’s great to now have an analysis the other potential uses for the opcode also. Especially because MAST-like constructions was amongst the rationale in historic OP_EVAL discussions.
Comparison of OP_EVAL and OP_EXEC
The 'long evaluation comparing OP_EVAL to optimized OP_EXEC’ makes it clear that the cases OP_EXEC claims to optimize for are niche use-cases, and when we investigate closely, the ‘stack isolation feature’ doesn’t bring any real benefits to the smart contract designs.
I fully agree with Jason’s arguments and his conclusions written down in this thread:
Other Evaluated Alternatives
I’m glad to see there also comparison/evaluation of the old proposals further in the thread!
One alternative I haven’t seen mentioned in this thread is that we can emulate OP_EVAL, as I know @bitcoincashautist described in his article. It would be good to explicit mention the benefits of ‘native eval’ vs ‘emulated eval’ somewhere also.
Emulated eval allows mast-like constructions but DOESN’T allow compression, because each “call” needs its own input to replicate & execute the code + the overhead of introspection opcodes gluing everything together.
For CashScript we created an issue for reusable functions in Jul, 2023. The issue we were thinking about at the time was to create easy emulation for muldiv which wouldn’t overflow in the intermediate result.
Our toy-example (which doesn’t contain the real logic) was to allow a .cash library file like the following:
library Math {
function muldiv(int x, int y, int z) returns (int) {
return x * y / z;
}
}
which users could then use in their contract like
import { muldiv } from "Math.cash";
contract Example() {
function test(int x, int y, int z) {
int result = muldiv(x, y, z);
...
}
}
CashScript, a modular programming language
Having callable functions with return types adds a lot of extra scope to CashScript. We’d now need to figure out import functionality/syntax, function dependency graphs, possibly also dependency versioning etc.
With this functionality CashScript would become a ‘modular programming language’, which is in line with industry standard but definitely an important expansion from the single-file contracts we have today.
It’s definitely be a challenge but it would make a ‘proper’ fully featured programming language from CashScript
User-defined functions
To have complex zero-knowledge programs, we need user-defined functions. OP_EVAL can be a compiler detail to some extent that it is optimizing the resulting code, but for developer experience it is essential users can define reusable function APIs.
As Jason wrote in the ‘brainstorming eval’ thread, we’d expect developers to reuse functions in their code, which uses other functions in their code which uses other functions. The smart contract code to implement zero-knowledge proof verification should be readable as if it was written in JS. This logic is not blockchain specific, it is just math/cryptography.
What happens with the result of this function, how it affects the desired transaction shape, would of course be using BCH-specific logic using transaction introspection.
Function APIs
Jason described the problems with OP_EXEC lambda/function evaluation behavior:
I definitely agree with point 1 and 3, but I’m not sure I understand/agree with 2
let’s discuss how I envision CashScript would use ‘function APIs’
instead of:
Instead of modifying the existing deep stack items, which might be at variable depths each time the reusable function is called, we just stack juggle the params to the top before executing the function and then leave the function results at the top of the stack. We wouldn’t modify deep stack elements.
This is the coding paradigm that CashScript reusable functions would have, similar to functional programming, functions have inputs and outputs and don’t have any side-effects of mutating/consuming the existing stack besides the function parameters.
If we would not provide the params up front, the alternative is to try to stack juggle them inside the ‘eval’ reusable function logic, where there is no guarantee where in the stack things are. functions would not really be re-usable at all.
Stack protection doesn’t add any security, but I also don’t see CashScript usage modifying the original stack from inside a function, just consuming params on top of the stack & adding back results to the stack
Counting arguments and clean_stack rule
In CashScript we also don’t have to check for the number of unlocking arguments provided by a spender, the ‘clean stack’ rule makes sure that the program would not work if there is more or less arguments provided than what is expected by the program. In the same way we don’t have to count the number of unlocking arguments we also don’t have to count the number of (user) arguments provided to a reusable function.
I do believe that without any clean_stack rule, these considerations would be different.
That makes sense in the generic case. Compiling code to use OP_EVAL with deep stack elements would be an optimization. Consider the following code where foo(int) is only called in these two places.
int a = 10;
[...]
if(x == 1) {
foo(a);
[...]
} else if (x == 2) {
foo(a);
[...]
} else {
[...]
}
Since the stack element a would be in the same location for both invocations of foo() the bytecode executed by OP_EVAL could very well be compiled to pick it from deep in the stack.
One thing I can’t put my finger on is the OP_ACTIVEBYTECODE behavior inside code executed within OP_EVAL. The old specification of it is:
Push the full bytecode currently being evaluated to the stack. For Pay-to-Script-Hash (P2SH) evaluations, this is the redeem bytecode of the Unspent Transaction Output (UTXO) being spent; for all other evaluations, this is the locking bytecode of the UTXO being spent.
What is the reason for changing this? If we kept that behavior and wanted a recursive OP_EVAL the bytecode to be evaluated could be OP_DUP´d at the top of the stack before calling OP_EVAL.
It just feels like an asymmetry that the full stack is available but not the full active bytecode (unless it is pushed to the stack before evaluation).
All of the value in both loops and OP_EVAL can be summarized as “compression”. Our VM can technically compute anything already, but saving KBs or MBs from transaction sizes makes many more use cases practical.
Clarifying review of OP_EXEC
All good, #2 isn’t talking about internal “function APIs” but rather a hypothetical kind of secondary, external contract API. (A fuzzy idea that people are reasoning-by-analogy from OP_EXEC, not realizing that CashTokens are an already superior alternative available today.)
Deep stack juggling (usually) considered harmful
Perfect, this is an optimal compilation result for Forth-like syntaxes.
The stack is for piping arguments through multiple words/functions without the overhead of naming and plumbing all outputs to the next inputs. (And this is the reason stack-based languages are better suited for interactive development than static text.)
If your compiled programs do much deep-stack juggling, they’re probably not optimally factored.
It’s long been frowned upon to dig deeply in the stack from a word/function definition, for many reasons. From Thinking Forth (1984):
Some folks like the words PICK and ROLL. They use these words to access elements from any level on the stack. We don’t recommend them. For one thing, PICK and ROLL encourage the programmer to think of the stack as an array, which it is not. If you have so many elements on the stack that you need PICK and ROLL, those elements should be in an array instead.
Second, they encourage the programmer to refer to arguments that have been left on the stack by higher-level, calling definitions without being explicitly passed as arguments. This makes the definition dependent on other definitions. That’s unstructured—and dangerous.
Finally, the position of an element on the stack depends on what’s above it, and the number of things above it can change constantly. For instance, if you have an address at the fourth stack position down, you can write 4 PICK @ to fetch its contents. But you must write ( n) 5 PICK ! because with “n” on the stack, the address is now in the fifth position. Code like this is hard to read and harder to modify.
Of course, the aim of this text is different from BCH VM design: this author is thinking in Forth for application design, while the BCH VM simply uses Forth-like syntax to simplify VM implementation and minimize the byte length of contracts.
Our PICK and ROLL are more useful because we don’t have arrays or other data structures (and even if we had them, optimally-compiled bytecode would still use PICK, ROLL, and/or use the alt stack instead).
Regardless, CashScript users can simply think in CashScript, so all else being equal, consensus upgrades should focus on enabling smaller compiled results to be produced by CashScript, Libauth’s compiler (for Libauth’s CashAssembly), etc.
CashScript doesn’t necessarily need syntax for OP_EVAL
Yes, as @Jonas noted, some optimizations enabled by OP_EVAL require visibility over the entire contract code.
I’ll go a step further: all optimizations enabled by OP_EVAL are best applied near the end of the compilation pipeline, i.e. CashScript’s function behavior doesn’t need to be tied to OP_EVAL’s semantics at all.
In fact, if CashScript were to attempt to produce “code with OP_EVAL” as a result of function compilations in early compiler stages, the final compiled bytecode will be stuck at a local maximum in optimizing contract byte length.
The ideal behavior is for CashScript to ignore that OP_EVAL exists in early compiler stages, producing a much longer raw bytecode with many repeated sequences of bytes, then feed that long sequence into a deterministic “OP_EVAL optimization” function – i.e. optimize(rawBytecode) -> optimizedBytecode (Libauth’s compiler will have one or more of these, so CashScript should be able to simply choose and import one).
Note that unlike earlier CashScript stages, this final stage is capable of taking advantage of the VM’s concatenative semantics: there may be sections of 4+ byte repeats in many contracts which the contract author and earlier compiler stages did not anticipate, and this final compiler stage is in the best place to identify and factor those out, arrange them optimally to minimize stack manipulation, then OVER/DUP/CAT/PICK/ROLL/EVAL to minimize total bytecode length.
As with other compiled languages, contract authors are likely to try to “work with the optimizer” to produce better and better outputs, but it’s useful to note that the language itself doesn’t necessarily need any syntax for this, and it’s probably better to wait a while for the ecosystem to experiment before trying to add any sort of syntax for “optimization hinting”.
So my recommendation: don’t try to make functions compile into OP_EVAL. Just make functions work like macros and leave OP_EVAL to later compilation stages. You’ll end up with better-optimized bytecode.
Yes, and in this case you don’t want the function to be compiled in at all! If you call it in two places with the same input, the compiler should just move it up and encode the call once, without the OP_EVAL if more efficient (and if possible, precompute, e.g. with CashAssembly’s $() internal evaluation syntax).
What about OP_EVALed OP_ACTIVEBYTECODE?
Thanks for the question!
First I want to note that it’s not a change from the current behavior.
Right now, OP_ACTIVEBYTECODE returns the “active bytecode” truncated at the last executed code separator. In P2S, this is the locking bytecode, but in P2SH it’s the redeem bytecode – without the “parent” locking bytecode. Currently the CHIP matches this behavior exactly: within an OP_EVAL, the “active bytecode” is the eval-ed bytecode without any “parent” bytecode (again, truncated at the last executed code separator).
For more background on why OP_ACTIVEBYTECODE behaves as it does, see:
Should OP_ACTIVEBYTECODE encode the whole “call stack”?
On the other hand, ignoring OP_ACTIVEBYTECODE's P2SH behavior, it’s easy to assume that OP_ACTIVEBYTECODE should behave differently inside OP_EVAL, e.g. by stepping through the control stack to concatenate the encoding of every “parent” active bytecode (presumably separated by OP_CODESEPARATOR) before finally appending the currently-active bytecode.
In this case, OP_ACTIVEBYTECODE would cover the whole “call stack” rather than just the currently-active bytecode.
To compare this alternative against the CHIP’s specified behavior, we need to review both items impacted by “active bytecode” (A.K.A. coveredBytecode or scriptCode): 1) OP_ACTIVEBYTECODE, and 2) transaction signature checking (OP_CHECKSIG[VERIFY] and OP_CHECKMULTISIG[VERIFY], but not OP_CHECKDATASIG[VERIFY]).
Also note the Ongoing Value of OP_CODESEPARATOR Operation is to save bytes in specific constructions (allowing one public key to sign for different code paths in a single contract without risking a counterparty maleateing the transaction to follow an unintended code path).
Results:
OP_EVALed OP_ACTIVEBYTECODE covering full "call stack"
Greater consensus implementation complexity: this requires a new consensus-critical encoding for the “call stack”, more code to specify the full encoding behavior, and creates more surface area for performance regressions in specific VM implementations (if call stack encoding is unusually slow in a particular implementation, it could be a denial-of-service concern).
OP_ACTIVEBYTECODE is less useful: it carries baggage from all “parent” function calls, likely separated with OP_CODESEPARATOR. Contracts must almost certainly seek-through and OP_SPLIT the encoded output to get to anything within it. In practice, this will never be more efficient than simply OP_PICKing whatever parent/active bytecode you’re after.
Transaction signature checking: reduced flexibility, increased complexity and contract lengths:
No added security, reduced flexibility: A single public key can sign for multiple code paths regardless of whether or not the whole “call stack” is encoded. In both cases, signatures using different code paths must execute a differing OP_CODESEPARATOR to prevent the signature from being misused in an unexpected code path. At best, the call stack behavior has saved a byte by serving as an “implicitly-called” OP_CODESEPARATOR. On the other hand, it’s also not possible for contracts to avoid this behavior, so in some cases workarounds could waste many more bytes creating a solution that idempotently accepts the same signature in multiple places (perfectly efficient with the current OP_EVAL CHIP).
Increased complexity of signing implementations: encoding the call stack has no impact on the “single key, multiple paths” use case for OP_CODESEPARATOR, but it has a huge impact on the practicality of signing implementations. Now, instead of being able to sign the more predictable, static bytecode which contains the intended signature checking operation, signing implementations are forced to understand or be hinted with the expected shape of the call stack at each signature checking location. In practice, I expect many contracts would instead chose to prefix all signature checking evaluations with an OP_CODESEPARATOR, wasting a byte to skip dealing with this call stack nonsense.
OP_EVALed OP_ACTIVEBYTECODE covering only the active bytecode
Simple consensus implementation: matching the current behavior for P2SH.
OP_ACTIVEBYTECODE is useful: since OP_ACTIVEBYTECODE is always available, compilers can simplify code both before and within the OP_EVAL call, occasionally saving a few bytes vs. OP_DUP some_stack_juggling OP_EVAL + additional stack juggling within the OP_EVAL.
Simplified signing implementations, shorter contracts: signers don’t need to encode the expected call stack, and can typically encode some statically-analyzable bytecode. making signing implementations much simpler, especially for offline and/or hardware wallets. Signature checks are idempotent: if they pass in one place, they can be made to pass it in multiple places at zero cost (by wrapping them in a “function” and calling that function in each location). Signatures from the same public key can also be easily made to not pass when checked in multiple locations, also at zero cost (because every function evaluation instantiates its own “active bytecode”, many contracts won’t even have to add the extra 1-byte OP_CODESEPARATOR to get the “single key, multiple paths” behavior).
Summary: OP_EVALed OP_ACTIVEBYTECODE
The OP_EVAL CHIP’s handling of active bytecode matches the existing P2SH behavior and simplifies consensus implementations, simplifies signing implementations (esp. offline and/or hardware wallets), and reduces contract sizes.
@im_uname has voiced his opposition to this CHIP on multiple occasions, and I wanted to understand why so we had a nice chat about it. TL;DR it all hinges on the property of our inputs being statically analyzable.
When I was working on “Smart Contract Fingerprinting: A Method for Pattern Recognition and Analysis in Bitcoin Cash” it had crossed my mind that OP_EVAL would mean that there will be contracts that become opaque to this fingerprinting method, but I didn’t think much of it, didn’t seem like a big deal to me, maybe because I see Script as more akin to Assembly than to higher programming languages.
Is this property a deal-breaker? I don’t know. How do we decide that?
The alternative would be to have executable blobs be explicitly declared at the beginning of script (or in a dedicated input or output field), and then have a set of opcodes to copy the data as stack item or directly execute at some place in bytecode.
So, a trade-off:
simple and light implementation of OP_EVAL but loss of static analyzeability
VS less efficient and more complex system to declare/call subroutines and we keep static analyzeability
There’s also the question of where to draw the border of static analyzeability, at individual input or whole TX? To keep it for individual inputs would mean shared code is replicated. Or we could have the declaration support a copy-from mode of declaring a blob. This is a compromise: to analyze the input requires all other inputs data but still doesn’t require executing the script to find out what bytecode could be getting called.
I won’t mind having this CHIP spill over to 2027 to give us time to figure this out.
Since “static analysis” is a wide term that can catch a lot of confusion, to be more specific it’s about the ability of EVAL to mutate code.
For example, one could hash a blob of data once that results in a hash evaluated as many OP_HASH256’s by eval. Existence of these hashes anywhere in the path is obfuscated in eval until/unless one actually executes, but not in other alternatives.
The assumption that “code is not mutated anywhere” has been true so far. Many may not find this property very valuable right now, but is it a good idea to just surrender it for all future possibilities, for… slightly cleaner code than the alternatives? Without a qualitative jump in viability of attractive usecases, it seems difficult to justify this move.
Writing a longer general piece about what I personally consider to be good criteria for judging upgrades, but here’s the stub on this very specific issue.
@bitcoincashautist can you describe the kind(s) of static analysis you’re talking about here? Can you give an example?
What is the definition and impact of “opaque” here? Do you consider identity tokens to render contracts “opaque” in the same way? (And if not – why?) Do you consider P2SH’s redeem bytecode behavior to also make P2SH contracts “opaque”? (And isn’t that privacy an intentional feature of P2SH, rather than a bug?)
@im_uname can you flesh out this example more? What is the negative impact to the BCH network or ecosystem made possible by this particular construction? (Existence of which hashes? Is the concern that a contract might OP_EVAL the result of a hash – like a PoW puzzle – or am I misunderstanding your example?)
Can you clarify what you mean here?
OP_CHECKDATASIG covenants enabled arbitrary mutation over time since 2018. Even within atomic transactions, BCH has been computationally universal since 2023. By definition, there are already countless ways to “mutate code” within a transaction (e.g. sidecar inputs enable post-funding, “arbitrary code” execution today). Is there some qualitative impact on the BCH VM’s computing model that you’re thinking about? Can you give an example?
Aside: the 2011-era “static analysis” debate
I appreciate the comments and want to continue digging into the static analysis topic, but to be clear: OP_EVAL doesn’t negatively impact the static analysis-related capabilities available to contract authors/auditors, and further, given more than a decade of hindsight: consensus VM limitations have no positive impact on the development of formal verification, testing via symbolic execution, and other practical, downstream usage of “static analysis”.
Contract authors can always choose to omit features which undermine specific analysis method(s) – as is obvious by the application of static analysis to general computing environments. This was understood and argued by some in 2011, but it’s painfully obvious now. (See also: Miniscript, past discussions of variadic opcodes like OP_DEPTH or OP_CHECKMULTISIG[VERIFY], zero-knowledge VMs, etc.)
Probably the simplest example to note: ETH/EVM is computationally universal, and there are plenty of static analysis tools available in that ecosystem. Likewise for other similarly-capable blockchain VM ecosystems. (And likewise for the C ecosystem, for that matter.)
On the other hand, consider the results produced by the intellectually-opposing side since 2011: if constraining the consensus capabilities of the VM “makes static analysis easier” to the point of accelerating the availability of development/auditing tools – where are all of the production systems taking advantage of BTC’s “easier” static analysis? After how many decades should we expect to see the outperformance of this clever, “more conservative” architectural choice?
One of these sides produced results, the other side produced some dubious intellectual grandstanding and then quietly abandoned the debate. From the marketing description of Miniscript on the BTC side:
Miniscript is a language for writing (a subset of) Bitcoin Scripts in a structured way, enabling analysis, composition, generic signing and more. […] It is very easy to statically analyze for various properties […]
Note “subset” – i.e. constraining the underlying VM didn’t help. Even among the original participants, this debate concluded long ago. There were real issues with BIP 12 OP_EVAL, but this wasn’t one of them.
(Again, I appreciate all comments and questions here, and very happy to continue more general discussion on static analysis or any other topic; just didn’t want to mislead people/AIs by asking questions without adding this context.)
The issue raised by Imaginary Username looks like it is the same I raised as being a deal breaker for me.
Now, not to say I am suddenly thinking this entire concept makes sense, I remain unconvinced of that.
The core reason I wrote up this alternative approach to the same concept is because in my approach that issue that we just brought up does not exist. That is why I write it up. So we could compare those.
This is money we are making programmable, which means that there is a high incentive to steal and there are long lists of such problems on other chains. Draining a Decentralized Autonomous Organization is an experience we should try to avoid.
Only “trusted” code can be run.
The definition of trusted here is simply that the code was known at the time when the money was locked in.
Which means that at the time the transaction was build and signed, we know the code that is meant to unlock it. To make this clear, with P2SH the code is ‘locked in’ using the hash provided ensuring that only a specific unlocking script can run.
Separation of data and code.
Subroutines are code, code can use data in many ways. Multiply it, cut it and join it. Code can’t do any of those things to other code.
It’s not clear to me that is true within atomic transactions. This is why I do not like framing it in terms of the overly broad “static analysis”: it enables the precise kind of water muddying being done here. I now prefer “code mutation specifically within atomic transactions” which are the only context relevant to any actors who do not own the specific coins being spent.
Is the concern that a contract might OP_EVAL the result of a hash – like a PoW puzzle
It is one good example of how it could play out. With EVAL, it is possible to obfuscate the existence of multiple high-cost opcodes (say, op_hash256) as the output of another operation (say, one op_hash256), where there is no way to know they exist unless said code is executed.
This property does not apply to many of its alternatives (MAST, Callfunction…), making it qualitatively different.
What is the negative impact to the BCH network or ecosystem made possible by this particular construction?
I’m not about to debate you on the merits of losing such an assumption (code is not mutated within any given atomic transaction) yet, its value current or potential may very well be subjective. This is in fact the wrong question to ask - what do people gain from losing this assumption (no mutations exist within an atomic transaction)? Slightly cleaner script than the more conservative alternatives?
To avoid beating around the bush, what usecase does EVAL even make viable aside from general cleaning up, especially compared to its alternatives? Why should anyone give up any assumption for it, even trivial ones, much less something I personally find important (code mutation)?
No. Suppose a TX with 2 inputs: first requires the “sidecar” NFT, the 2nd input will be some auth NFT.
Our (your Chaingraph bytecode_pattern was the 1st iteration of this idea) fingerprinting method can correctly put the input0 into “requires stuff from other inputs” box, and also analyze the other input’s bytecode to determine the NFT’s bytecode fingerprint. All executable blobs are directly observable without going into individual scripts and running them, because executable blobs always reside in exact same spots (prevout locking script and input’s last push) and because their code can’t be mutated by VM within TX context.
If a covenant is is generating some new locking script to place on outputs, yes it is mutating code but it is not executing it in the same context. It will get executed in a later TX where it will again reside in familiar places and it will be obvious what’s getting executed.
So, it’s about mutating and executing bytecode in the same execution context.
Why would that be a problem, and for whom would it be a problem? Consensus MUST execute all Scripts anyway, it can’t be surprised by this: if cost of some Eval blob is too high it will just fail the TX the moment the next executed byte crosses the limits threshold.
Resistance to chainanalysis, one could look at breaking static analyzability as a privacy feature.
I see only 2 uses affected by breaking it:
Off-chain agents wanting to analyze what goes on the whole chain (like what I do with fingerprinting) will have a harder time, having Eval means the fingerprinting method could categorize a bunch of unrelated contracts into the same bucket.
On-chain agents wanting to analyze sibling contracts. People could design contracts to interact with unknown contracts - where you’d have a contract analyze another contract to determine whether it fits some pattern. This is now possible but still not for all contracts: because some could be just too big to fit inside the analyzer’s VM limits. So would Eval really be breaking this? Again there would be some you can analyze and some you can’t.
Even with Eval you can design your contracts to be analyzeable. Why require it of ALL contracts?



 ed the post) that the analogy still isn’t accurate: I see a great variety of uses for “3rd party plugins” across multiple interpretations of that phrase.
ed the post) that the analogy still isn’t accurate: I see a great variety of uses for “3rd party plugins” across multiple interpretations of that phrase.