
Why? Do you think variance is due to us being minority hashrate? I’ve seen people say something like “oh variance is due to switch mining causing oscillations” and I wondered where do they get that from. It sounds plausible, but is it true? This is a good opportunity to address that question.
What I found is that it used to be true (with EDAA and CW-144 DAA), but it has not been true since introduction of ASERT DAA in 2020. Still, the common knowledge persisted - because it used to be true, even though it isn’t anymore.
Now it takes a big hashrate event (big price move on BCH or BTC, or halving, or big miner misconfiguration or error) to have noticeable impact on block times. Absent that, real block times are well aligned with the theoretical distribution for a random process targeting 10 minutes.
Let’s examine a few samplings of day’s worth of block times.
Extreme Swings With EDAA
We had EDAA for 106 days (2017-08-01 to 2017-11-13), and during the period:
- Average block time was 5.86 minutes (and variance was extreme due to huge hash volatility as miners were gaming the algorithm)
- BCH created 10,577 more blocks compered to ideal 10-min schedule
- Emission schedule was shifted by 73 days, minting 132k BCH ahead of schedule
The below figure (2017-10-12) illustrates the problems well:
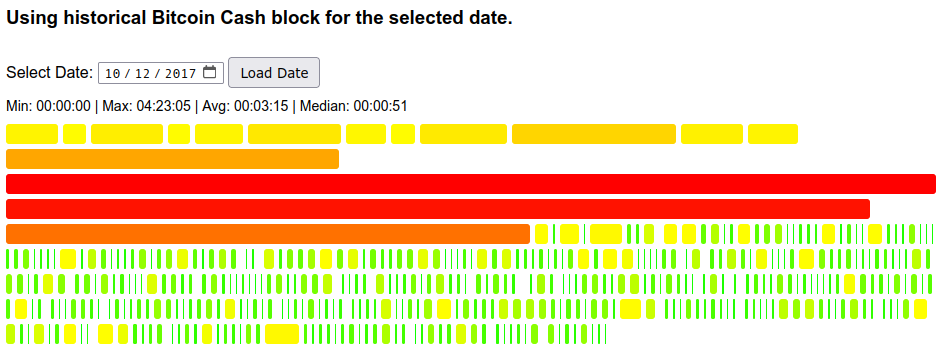
Oscillations With CW-144 DAA
We had CW-144 DAA from 2017-2020, and it maintained the average, but it had oscillations due to nature of simple moving average: of all blocks in the moving average window having equal impact, so when a slow block “enters” the sampling window it drops the difficulty, but then after 144 blocks it “exits” the sampling window and brings it back up - leading to oscillations and volatility in hashrate.
The below figure (2019-10-12) illustrates this effect well:
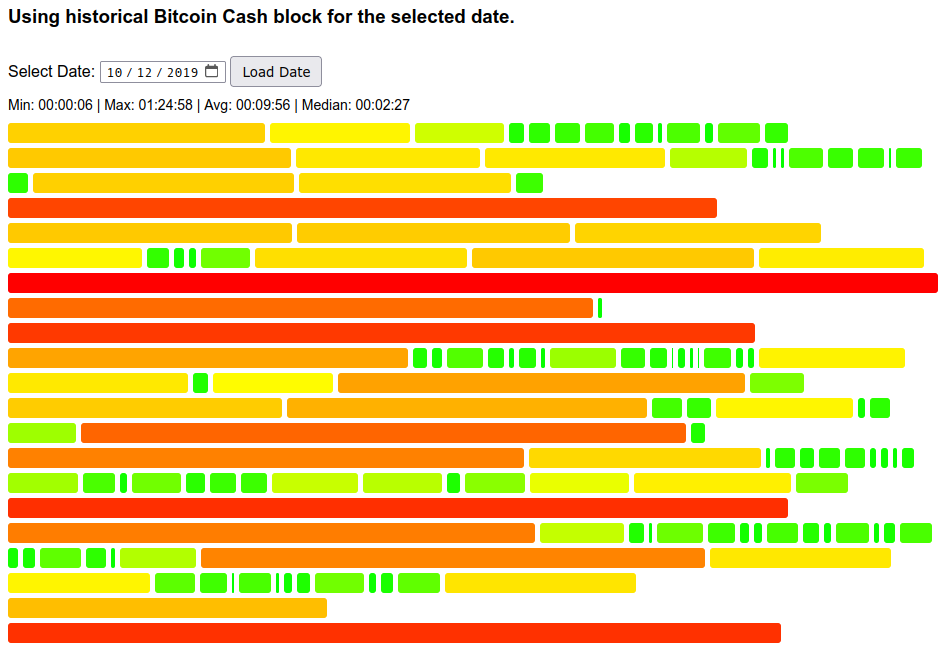
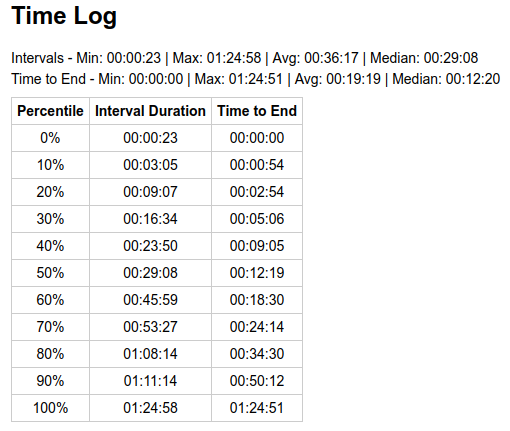
Packs of short blocks followed by packs of long blocks are pronounced. We can compare all the percentiles with calculated theoretical probabilities:
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | ||
| 0.7%* | 00:04 | |
| 10% | 01:03 | |
| 20% | 02:14 | |
| 30% | 03:34 | |
| 40% | 05:06 | |
| 50% | 06:56 | |
| 60% | 09:10 | |
| 70% | 12:02 | |
| 80% | 16:06 | |
| 90% | 23:02 | |
| 99.3%* | 49:37 |
* 1 block per day (1/144 = 0.7%)
Notice that the whole distribution of wait times is skewed far from the theoretical random process (median 1-conf wait of 12 minutes, while in a truly random process it is expected to be 7 minutes).
So yes, it definitely used to be true that DAA oscillations and miners switching were causing additional variance. Jonathan Toomim’s analysis goes more in depth on this.
Current Situation (ASERT)
Is that still the case, are we now experiencing additional variance or is it better aligned with expected theoretical distribution?
Steady State (ASERT)
Days with sideways price movement (2024-09-26) show variance expected of a random process:
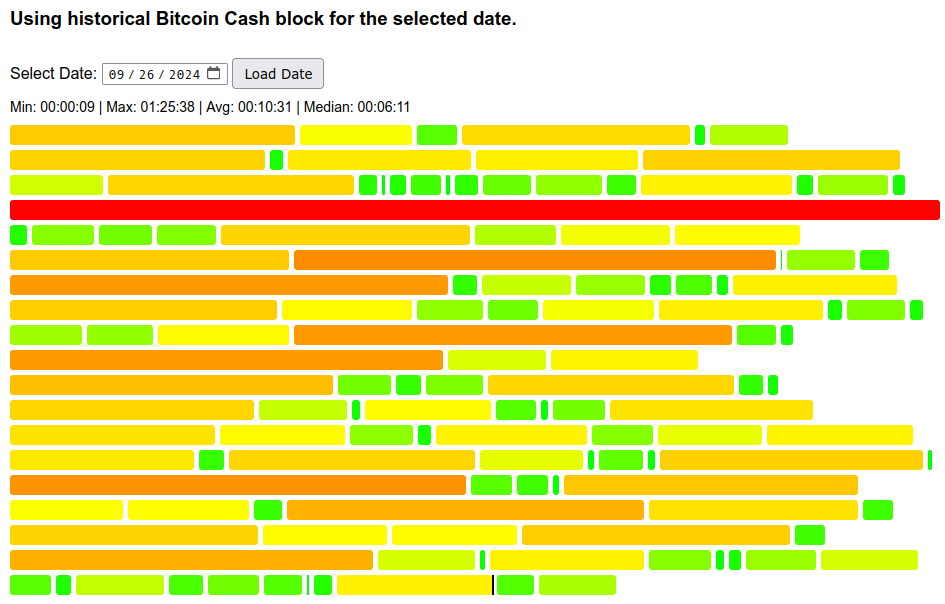
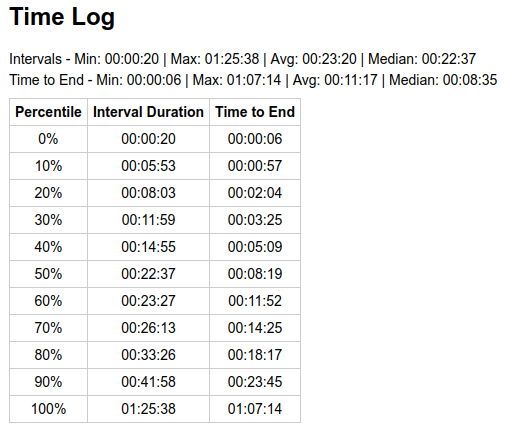
There’s still some discrepancy in percentiles when compared to above theoretical, because 1 day worth of blocks (144 blocks) is still a small sampling window, not enough to fully smooth out impact of luck, and some switch mining can still impact our block times. However, it is much less pronounced than just normal variance of a random process.
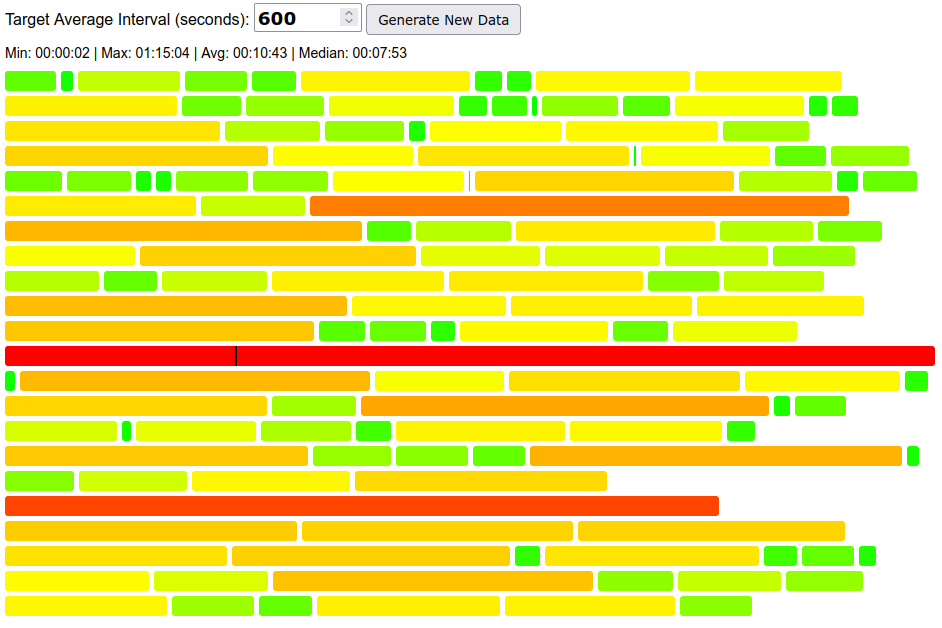
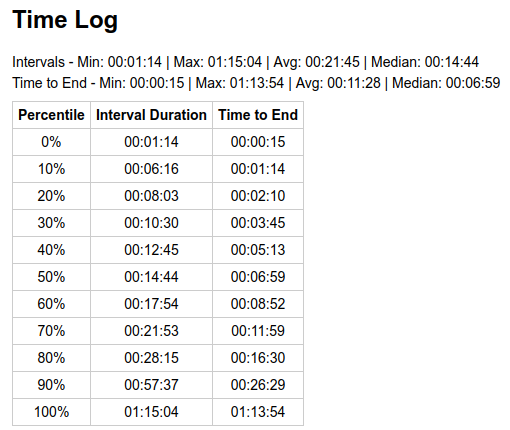
To confirm impact of luck, we can generate random data and observe interval distribution looks similar, and the percentiles table is affected by the particular sampling of ~144 blocks:
Upward Price Move (ASERT)
If the price goes up enough, the average block time is expected to be proportionally faster until DAA catches up - but the individual block times are still expected to be randomly distributed around the stretched average. See sample from 2025-05-22, it had a +9% price move and result was 9:10 average (-8%) for the day.
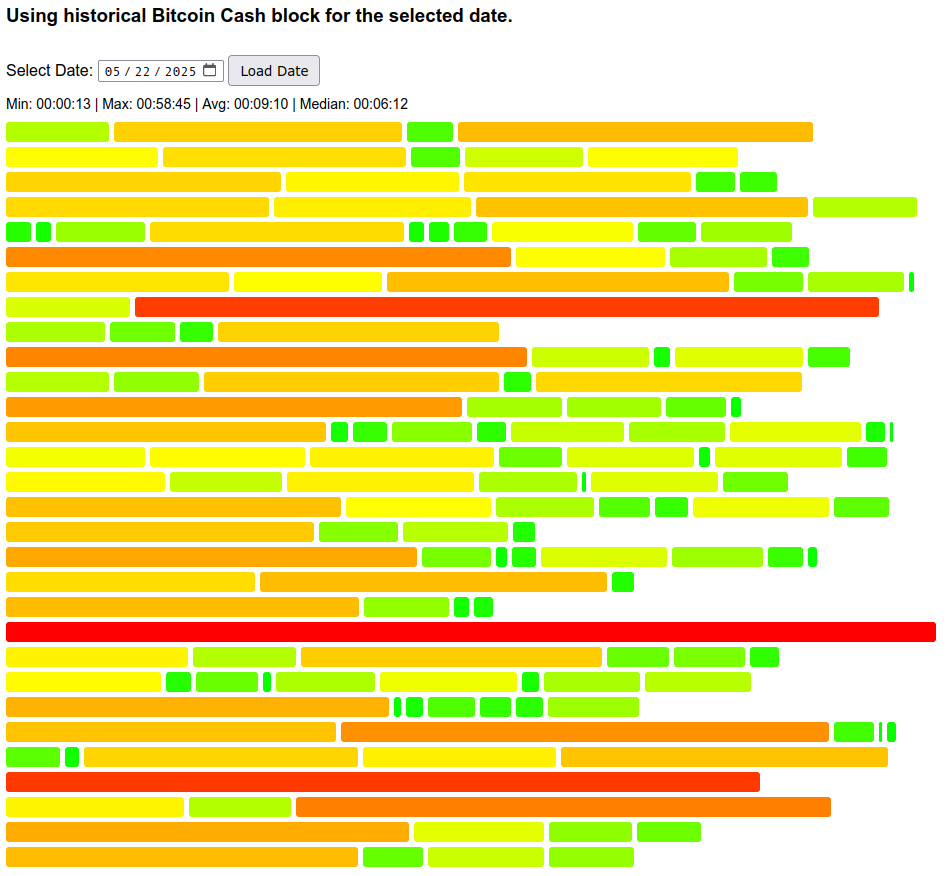
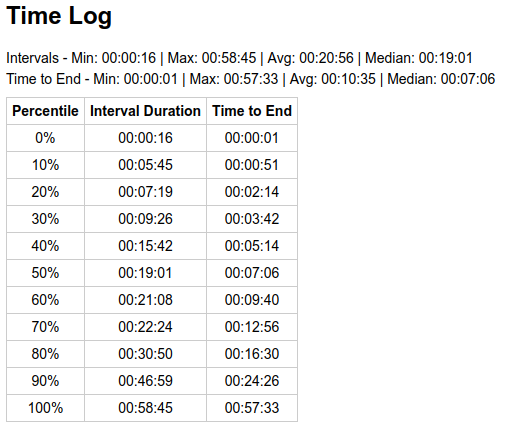
We still had an outlier of 58 minutes, and if you pick a random point on the timeline for that day - you get a distribution where there’s 20% chance of waiting >16 minutes, and 10% chance of waiting >24 minutes. This is close to theoretical:
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | (case 550s average) | |
| 0.7%* | 00:04 | 00:04 |
| 10% | 01:03 | 00:58 |
| 20% | 02:14 | 02:03 |
| 30% | 03:34 | 03:16 |
| 40% | 05:06 | 04:41 |
| 50% | 06:56 | 06:21 |
| 60% | 09:10 | 08:24 |
| 70% | 12:02 | 11:02 |
| 80% | 16:06 | 14:45 |
| 90% | 23:02 | 21:06 |
| 99.3%* | 49:37 | 45:29 |
* 1 block per day (1/144 = 0.7%)
Downward Price Move (ASERT)
We can observe the same in a downward price move (2025-02-03). The price moved -15% over 2 days, and block time average for the 2nd day was +22% off target.
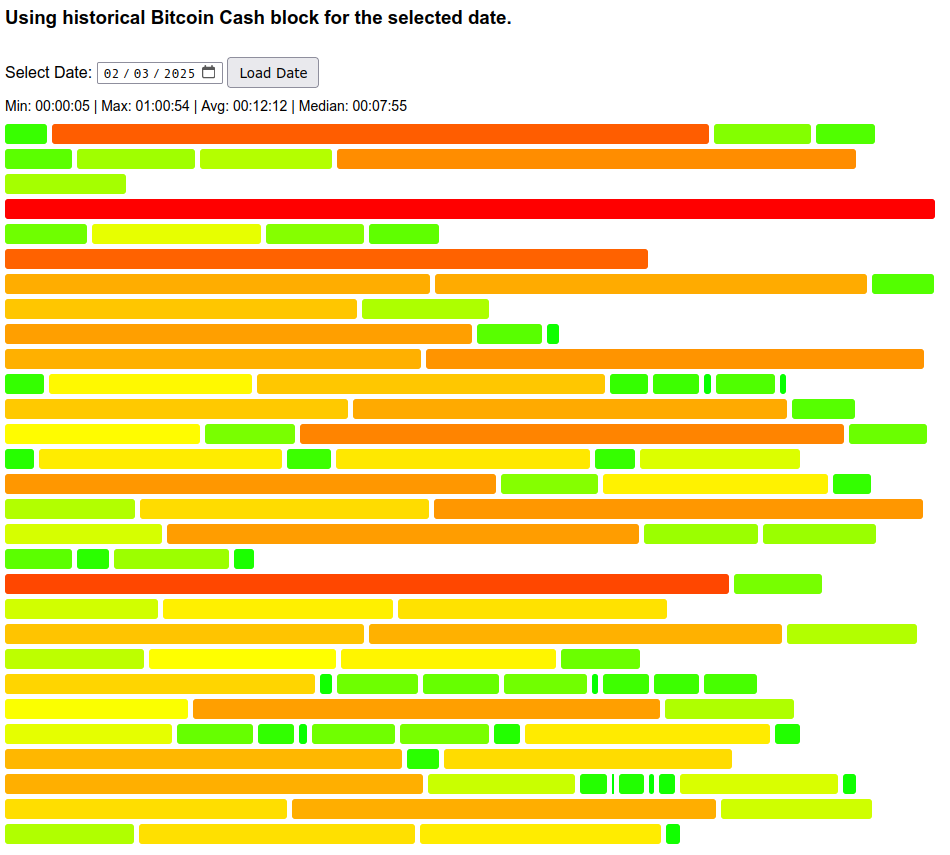
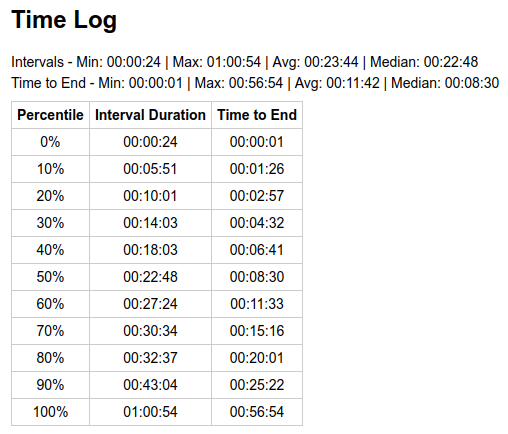
The distribution of individual times was still aligned well with theoretical for the matching average.
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | (case 732s average) | |
| 0.7%* | 00:04 | 00:05 |
| 10% | 01:03 | 01:17 |
| 20% | 02:14 | 02:43 |
| 30% | 03:34 | 04:21 |
| 40% | 05:06 | 06:14 |
| 50% | 06:56 | 08:27 |
| 60% | 09:10 | 11:11 |
| 70% | 12:02 | 14:41 |
| 80% | 16:06 | 19:38 |
| 90% | 23:02 | 28:05 |
| 99.3%* | 49:37 | 60:32 |
* 1 block per day (1/144 = 0.7%)
Block Reward Halving (ASERT)
What about halving? It should have impact equivalent to a 50% price drop.
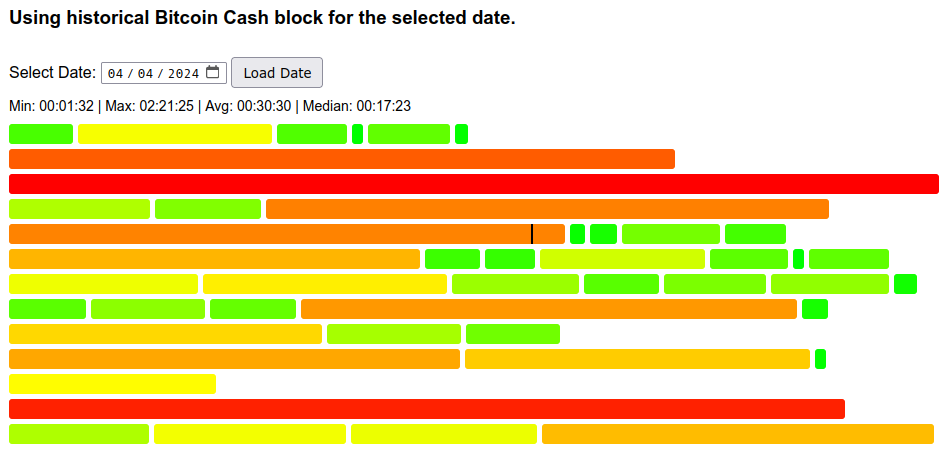
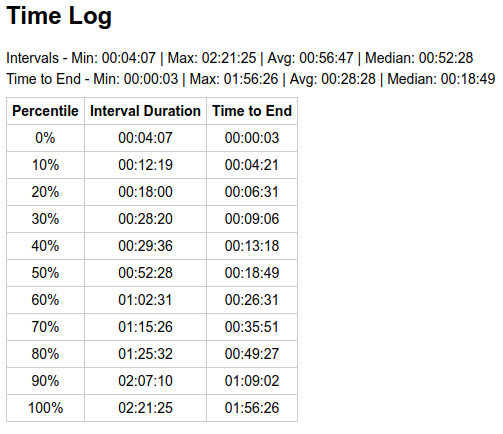
Looks like, on the 1st day, it was more pronounced than anticipated, indicating miners played it safe and removed (or moved to BTC) more hashpower than 50%. The distribution of individual times was still aligned well with theoretical for the matching average, despite the small sample size (47 blocks for that day).
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | (case 1830s average) | |
| 0.7% | 00:04 | 00:13 |
| 10% | 01:03 | 03:13 |
| 20% | 02:14 | 06:48 |
| 30% | 03:34 | 10:53 |
| 40% | 05:06 | 15:35 |
| 50% | 06:56 | 21:08 |
| 60% | 09:10 | 27:57 |
| 70% | 12:02 | 36:43 |
| 80% | 16:06 | 49:05 |
| 90% | 23:02 | 70:14 |
| 99.3% | 49:37 | 151:20 |
* 1 block per day (1/144 = 0.7%)
I think this is the only case where our share in total sha256d haspower would matter. Thankfully such events only happen once every 4 years. 
What Does This Mean for The CHIP?
Nice thing is that extremes scale with target block time, what is now 0.5 to 30min range (90% of waits) could become 0.05 to 3min by reducing the target/average time to 1min, and impact of the next halving would be increased to 0.15 to 9min waits for a day or two (assuming 1/3 hashpower drop like last time).
Impact due to price/hashrate volatility would be barely noticeable, since a 20% move would have just 12 seconds impact on the average (as opposed to 2 minutes now).


 and you are getting into the main problem here. 1 min block is not needed within BCH wallets, exception is DeFi and AMM in DEXs however with Exchanges , payments processor and even some services like Mullvad etc… its very much needed right now
and you are getting into the main problem here. 1 min block is not needed within BCH wallets, exception is DeFi and AMM in DEXs however with Exchanges , payments processor and even some services like Mullvad etc… its very much needed right now