I am not saying that your entire way of reasoning is wrong.
In fact, in a perfect world where miners are active participants of the ecosystem, they take part on the discussion here, on GitLab and in other places developers work, your way of thinking would totally work (Also there would be no BCH, because miners would just HARD drop Core in 2017 and instead use Bitcoin Classic / Bitcoin Unlimited, we would have 256MB-blocksized BTC right now and live happily ever after).
However, the world is not a perfect place, we are still not developed enough as a civilization and humans are unfortunately just more complex animals, that follow either the herd or the alpha (or both). And miners are the most animalistic of us BCHers, for whatever reason.
In such imperfect place, your reasoning cannot possibly work, but it is not your fault. It’s evolution’s fault. It’s just too slow.
We developed our tech way too fast and we are not ready for it, clearly. So we have to do some workarounds.
Shortly after the release of Bitcoin Unlimited 1.0.0.0 Bitcoin.com’s mining pool mined a block with a size bigger than 1MB, which was immediately orphaned.
It will be hard to predict what it will look like even at 10 MB baseload Consider that Ethereum, with all its size, barely reached 9 MB every 10 minutes.
The algorithm can be bypassed or have its parameters updated using the same logic we can now use to update the flat EB. I now understand why you don’t see it as a hard-fork and why we were talking past each other before, because the updated limit doesn’t get tested on each block since it’s a <= rule and changing it’s parameter does not cause a hard-fork unless actually tested by hash-rate. From a Reddit discussion:
The nuance is in the difference between == rules (like for validating execution of opcodes, correctness of signatures etc) and <= rule (like for validating the blocksize limit, max stack item limit, etc).
If now we have a <= EB_1 rule, then later when we move the limit to some <= EB_2 it will be as if the EB_1 rule never existed, as if it was EB_2 rule all the time - nodes don’t need to introduce some if-then-else check at height N that switched from EB_1 to EB_2 in order to validate the chain from scratch - they just use EB_2 as if it was set at genesis.
The MTP activation code is only temporary, to ensure everyone moves from EB_1 to EB_2 at the same time, and can later be removed and we pretend it was EB_2 right from the start.
Algorithm’s activation (or later updating or deactivation) would work the same.
I remember that. BU software forgot to count some bytes and made a block that was too big. That was the last time their client was ever used to do mining, probably forever cementing the concept of “reference node” into the public consiousness.
Its a great exception tha proves the rule, I agree. A straight up bug and a silly Roger that believed more in a democratic software process than in good developers.
There is no real risk in activating the algorithm without a coordination event either. You can release it next BCHN update and miners can updat their nodes at their leasure because the limits imposed are not in conflict with the max blocksize mined.
Just like us releasing the 2MB Bitcoin Classic on the mainnet was not a hard fork event, contrary to what some Core devs claimed (they also claimed it for XT)
My take on this (as a “medium blocker” who has been following BCH from the beginning in 2017):
Miners should have nothing to do with the maximum block size. Large miners’ interest is to confirm as many transactions as possible. As we have seen with Ethereum, they will raise the blocksize limit until they can’t do it anymore. The max block size parameter comes from users, or more precisely merchants, who define what consensus rules are.
The idea of an algorithmic adjustment based on usage to handle rapid surges in tx throughput is a good idea. Such an algorithm should also be able to lower the variable max block size, in case of a censorship attack for instance. But IMO it still need an absolute max block size. As a node operator, I need to know what the “worst case scenario” might be, so I can plan and estimate the costs. More generally, I don’t want to see BCH follow the path of BSV, which was delisted from Blockchair due to its reckless decision to remove blocksize limit entirely.
Besides, 2024 is way too soon: this major upgrade needs a lot of discussions, and blocks are still very small today.
The idea of an algorithmic adjustment based on usage to handle rapid surges in tx throughput is a good idea
Note that in practice, “adjustment to handle rapid surges in throughput” doesn’t exist; an adjustment algorithm that increases blocksize limit rapidly wrecks operators the same way a really big cap/nocap does, because the limiting factor is CPU/RAM/software - all things responding very poorly to a rapid surge - as opposed to disk, which most people think of, that has a flat response to short term surges. The best one can do for rapid surges is to leave some reasonable headroom, then concede that really big surges will just have to be left capped. (The article touches on this briefly, no hours/days doublings)
As an operator you are going to be served alright by a slow-moving algorithm in planning out your investments. I’ve been mesmerized by the idea of a rapid-moving algorithm too for years until I tried to square it with real world operations, and realized it simply does not work for the important stuff.
If the algorithm is slow enough, then a hard cap would be obsolete; it’ll either be small enough that the algorithm cease to be useful, or large enough the algorithm will take months/years to get there in worst case anyway, which leaves plenty of room for an operator to see it coming.
Again, please think in slow-moving terms, not fast-moving terms. The considerations are quite different.
Looking at the consecutive iterations of @bitcoincashautist’s algorithm, I would risk a thesis that the “worst case scenario” is the algorithm will require minor tweaks along the way, but it will not cause any kind of disaster.
The math (actually the simulations) looks rock solid to me and I see no reason why we should not implement it, right now.
Even if activated in '24, it wouldn’t necessarily mean the limit would actually get moved beyond 32 MB any time soon, it would be more like a commitment to automatically respond to actual growth later - when it actually comes, not before.
Consider these features of the proposed algorithm:
It wouldn’t move at all if all miners would have their self-limit under 10.67 MB (most have it at 8 MB now)
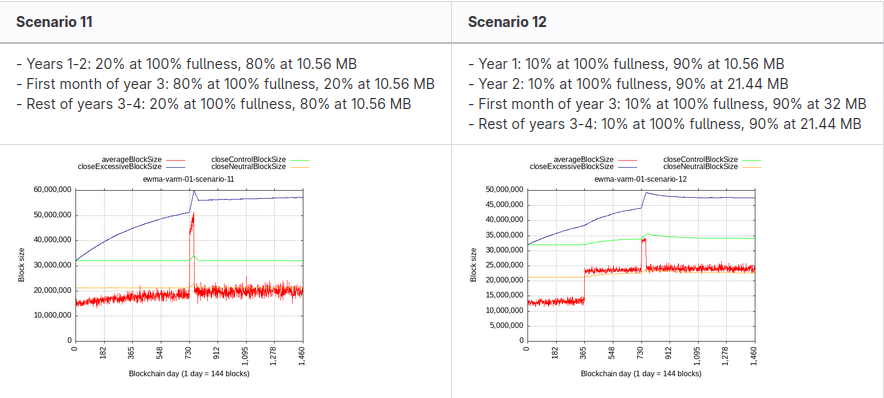
If some 20% hash-rate defected and started pumping at max., they could only push the limit to 58 MB, and it would take years to get there if other 80% kept their self-limit at 10.67 MB or below.
Temporary burst, like 80% hash-rate mining full, could make a jump from 50 to 60 in 1 month, but as soon as TX load goes down, so does the limit decay back to equilibrium.
Notice that the green line doesn’t move at all except for the 80% burst case. It actually takes more than 50% hash-rate to continuously move the baseline (as in scenario 12, where the majority bumps it up).
Keep in mind the time scale, each grid-line is half a year.
How much discussion would count as “a lot”? In recent BCH history the discussions have been going on since 2020, and in the meantime BU actually deployed @im_uname’s dual-median proposal for their new cryptocurrency, which can serve as validation of general approach. My proposal is an improvement over the median-based approach in that it achieves same 50:50 stability (takes more than 50% hash-rate to keep pushing it up indefinitely) but it’s smoother, is actually based on a robust “control function” used in many other industries, has less lag, and is better behaved in corner cases, please see here how it compares vs median-based.
Yes, if it’s user-made transactions paying enough fees to counter reorg risk, in which case it’s evidence of healthy network growth, right? The transactions have to come from somewhere, someone has to actually make them, right? If it’s real users making those TX-es and paying at least 1sat / byte then do we agree we should find a way to move the limit to avoid killing growth like in '15? The algorithm will do the part of moving the limit for us, even though it cannot magically do all the lifting work that is required to bring the actual adoption and prepare the network infrastructure for sustainable throughput at increased transaction numbers.
If it’s some miner trying to mess with us and stuff his own TX-es, then he will pay a cost in block propagation and he’d have limited impact if he has <50% hash-rate, and he’d have to maintain that regime of mining as long as he wants to be “stretching” our limit - and when he loses steam, the algorithm would fall back down to baseload of actual user’s transactions.
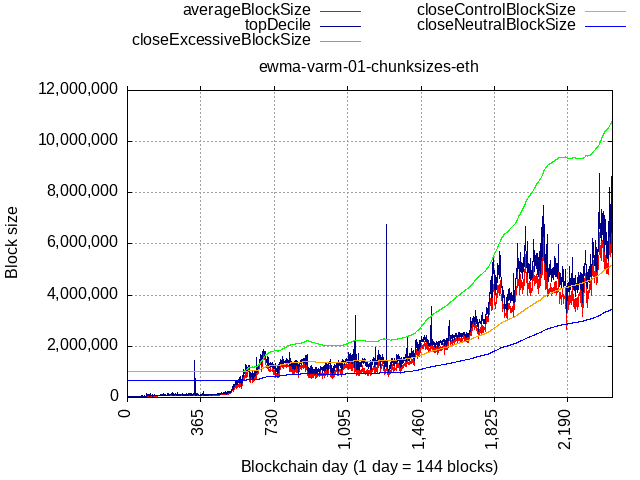
I thought their block size was limited by other factors, like validation time & gas prices, specific to EVM architecture? Anyway, here’s how my proposed algo would’ve responded to actual Ethereum “chunks” (chunk = sum of 50 blocks bytes, so I can directly compare with our 10-min blocks).
The algorithm would always provide some headroom, about 2x above what’s actually getting mined, and has some reserve speed to give more breathing space if limit starts getting hit too often, but it’s all rate-limited, extreme load won’t magically move the limit by 10x in a week and shock everyone, users would have to suck it up a little - have the TX load spread across multiple blocks and give the algorithm time to adjust to new reality, e.g. imagine a burst of 1sat/byte TXes, those would have to wait a few blocks, while maybe just 1.1sat/byte would be enough to get in the next one for normal users, and mempool would clear once the limit expands to accommodate the rate of incoming TX-es, or the TX load drops down.
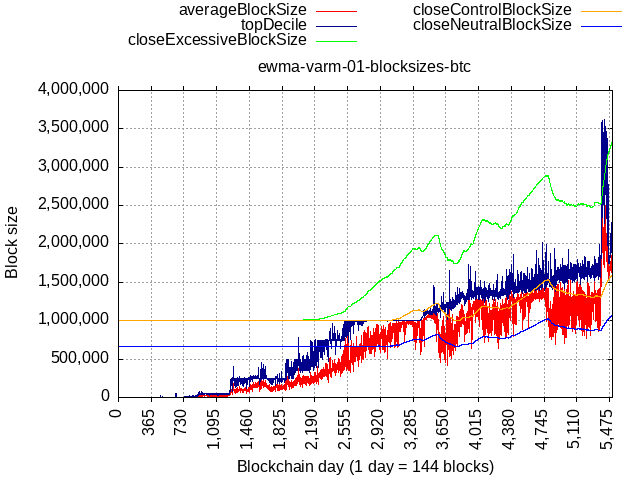
Back-testing against BTC shows this, sudden jump due to ordinals would cause them to temporarily hit the limit (1 or 2 out of 10 blocks would hit the limit) until new equilibrium is found (at about 3.4 MB for BTC).
Here I have to disagree. Having an absolute limit would not achieve the objective of the move to algorithm: close the social attack vector, what when we get to the limit? What if we get stuck there forever? The main motivation for the change is not technical, technically we could just bump it up “manually” every year, but it’s easier said than done - because that has a “meta cost” in coordinating and agreeing on the next bump - and it leaves us open to adversaries poisoning the well and causing a dead-lock, like it happened in '15. This proposal would change the “meta game” so that “doing nothing” means the network can still continue to grow in response to utilization, while “doing something” would be required to prevent the network from growing. The “meta cost” would have to be paid to hamper growth, instead of having to be paid to allow growth to continue, making the network more resistant to social capture.
You could plan 1-2 years ahead based on current network conditions, since the mathematical properties of the algorithm make it easy to model whatever “what if?”. Like, we did some tests for 256 MB on scalenet already, but with the algo initialized at 32 MB minimum it would likely take a few years to bring the limit to 256 MB. By the time it actually gets there, people would likely be already doing 512 MB tests to stay ahead, right? Remember BIP-101 - well, 75% blocks would have to be consistently full in order to move the limit at BIP-101 rates (x2 every 2 yrs). Here’s the full set of simulations.
Please let me know if you want me to run some particular simulation to see how the algorithm would respond.
None of us do. Which is also why we don’t want to just bump it to 256 MB “to be ready for VISA-scale” or w/e - because putting the cart before the horse, having too much underutilized space, would leave us open for abuse in the meantime and could actually hamper organic adoption by increasing cost of participation before economic activity justifies it - see here for the full argument.
Just as a note - if anyone sees contrary positions / reasonable alternatives that are not in the CHIP, they should be, so please send a link to BCA. I expect this CHIP to be one of the largest ever written, not for technical reasons but for ensuring that it’s really iterated through and been deeply considered vs. all alternatives.
@im_uname@bitcoincashautist All right, I didn’t realize how slow the adjustment was! This sounds better. Thanks for the (detailed) answers!
I would still prefer to keep a hard blocksize cap that could be raised or lowered, like every 10 years or so. I hear about the risk of a Schelling-point “social attack”, i.e. refusing to increase the limit despite good technical reasons to do so, but that’s how Bitcoin works. The idea is to ensure that the network is decentralized enough to secure low-value (“cash”) transactions; we don’t know what the good blocksize is for this. It could be 256MB, 1GB, 10GB, 100GB or 1TB, idk.
I hadn’t heard about this before yesterday, except for the im_uname proposal. Not on Reddit, not on Twitter, not on BCH Podcast Youtube channel. I bet most BCH users haven’t heard about this either. It needs to reach non-developers, before it gets to the protocol, otherwise people are trusting you blindly and that’s not a good thing. Look at what happened with Taproot upgrade and Ordinals on BTC: a lot of people got upset because they didn’t know this kind of things could be done with Taproot.
This topic has been extensively discussed. If I remember correctly, the first iteration of @bitcoincashautist’s algorithm has 3 years?
Also this matter has been discussed in one form or another since at least 2016, even back in BTC days. It’s not new and it did not appear out-of-nowhere.
And I am pretty sure it has been discussed here, on bitcoincashresearch for at least a year and half.
I do admit we do have a communication problem though.
There is basically no in-the-middle person that takes part in daily developer discusssions and then translates the issues to the public.
That said, I am currently personally up-to-date with the opinions of the community and with the considerations about multiple topics and I am certain that there is no signifiant opposition against this idea that would make any sense (excluding known trolls of course).
Sure, happy to answer! It’s seen a few iterations but underlying function has been the same through the iterations - the EWMA, I didn’t even realize that the first versions were actually EWMA-based haha, I kinda re-discovered it. Older version had a fixed %fullness target and it is thanks to @emergent_reasons that I found a way to have the elastic multiplier: he was concerned that we may not want too much headroom when we get to bigger sizes, and so the current version applies an elastic multiplier to the baseline EWMA so headroom can get reduced if bigger sizes would have less variance in some future steady-state, which is how we got to the current version.
How about we let it run and then re-evaluate every 1 year or so? How many times did we re-evaluate the DAA? What’s a bigger risk long-term:
a) refusing to increase the limit despite good technical reasons to do so
b) refusing to add a fixed boundary to algo’s limit (or just update the algo’s params to slow it down more, while leaving it boundless) despite hypothetical in-the-future good technical reasons to do so
Algo’s parameters could be re-evaluated, without a need for a hard boundary. Just because we set it up in a certain way for '24, doesn’t mean it has to be like that forever, we can re-evaluate as we go on just the same as we could re-evaluate whatever hard limit we had so far. Difference is between re-evaluating the limit VS re-evaluating the limit’s max. rate of change.
Before arriving to 1TB we’ll have arrived to 100GB, before arriving to 100GB we’ll have arrived to 10GB, before arriving to 10GB, we’ll have arrived to 1GB, before arriving to 256MB, we’ll have arrived to 32MB.
It can’t surprise us because the algo is rate-limited and conditional on actual utilization because the rate of adjustment is proportional to how much of the current space actually gets used: so going from 32MB to 256MB would likely take more than 2 yrs in the most optimistic rate-of-adoption scenario. Going from 256MB to 1GB would be 4x and likely take more than that since it’s harder to fill 256MB than it is to fill 32MB - someone has to be making all those TX-es to maintain the baseload.
We can evaluate yearly whether the next 4x from wherever we are now is feasible or not - and plan next scheduled upgrade accordingly.
We don’t, but the relay policy determines the minimum fee, and then users can either load the network with their TX-es or not, to which miners would respond by building the blocks, to which algo would respond by slowly making room for more. If nobody makes the TX-es, the algo doesn’t move (or it even moves down).
So, algo is fundamentally driven by the negotiation between users, nodes, and miners, and it is totally agnostic of fee / TX - it will be whatever is negotiated by the network - leave it to the market & min. fee relay policy.
Instead of debating block size limit, which is consensus-sensitive and comes with a bigger “meta cost” to change, we could be debating min. fee relay policy if we want to increase / decrease TX load which has smaller “meta cost”.
The fixed emission rate is also an adoption rate limiter.
As demand for new coins exceeds the limiter, the price begins to rise exponentially. The rising price forces us down the demand curve.
Demand is thus always kept in check by the exigencies of the exchange market. There simply cannot be a sudden planetwide onchain rush because the very nature of the fixed emission rate means the demand is always throttled. The exponential nature of the price curve is very effective at throttling demand. We’ve seen it repeatedly throughout Bitcoin’s history.
So: given BCH’s proven ability to absorb the world’s onchain demand through the mid-future and given the built in onboarding rate limiter, I’d say it’s arguable that onchain scaling for P2P cash transactions is already solved.
I’ve been regularly sharing the progress on the main BCH Telegram group and on the BCR forum here, and I’ve shared progress on BCH Podcast Telegram group, too, and on my Twitter, too. It’s been picked up by Xolos’s podcast too and it sparked a discussion on reddit. Haven’t been as much active on r/btc since all the buzz is on Tg and Twitter, but I guess some like yourself still use r/btc as a main source, but even there I had some good talks about the proposal. The CHIP references some good discussions:
I would eagerly donate to a flipstarter for implementation of an algorithmically adjusted maxblocksize (based on usage) as default in a full node with or before the 2024 network upgrade.
I like the latest version because it is aimed at the right part of the system. It is close to being an information tool. With the idea of “hey, if you stay in this range, its safe”.
The fact is that it responds to the market, including miners choices, it does not dictate a choice. Miners continue to decide what block they want to mine, even if that decision is to just follow a default.
I see his proposal as filling in one of the parts needed to have better communication in the future. It can’t fulfill everything as communication is inherently a human endeavor. For instance the deployment time-delay issue is near impossible to cover without actively picking up the phone. Miners will still need to communicate with big stakeholders about their limits. That can not be automated. Assumptions may prove costly.
To me this is worth a try as it helps avoid some stupid problems. It is ok to try and fail since it won’t take a protocol upgrade to decide something else may work better. We won’t lock ourselves into a prison just to avoid another.
In the end it is bringing a smile to my face that the proposal I made last winter is practically identical in ideology and approach. The coordination I glossed over is partly filled in by BCAs proposal and miners in his proposal are forced to take the responsibility of assessing what the technical capabilities are of their setup whereas my proposal puts that on the software maintainers. But there is room for both and more ways to try and solve this social issue.
I don’t know the exact dates, but I have been seeding automatic blocksize increase mentions into the podcast for months now. It has been more extensively discussed in Episode 88 (coming out today on Youtube, been available on Twitch already this week), but it was already discussed on Episode 83 on the 3rd of June, and I am positive I have made references to the possibility of an upcoming algorithm and discussion many times before that too on previous episodes.

 Consider that Ethereum, with all its size, barely reached 9 MB every 10 minutes.
Consider that Ethereum, with all its size, barely reached 9 MB every 10 minutes.

 What’s a bigger risk long-term:
What’s a bigger risk long-term: