This will be a strictly development topic.
For the sake of not making this thread 1000-pages long too quickly, please keep political or non-technological discussion to the minimum.
Continued work on fixing the Nested Proof Of Work design.
The borked v0.80 design of Infrastructure Blocks assumed that it is possible to merged-mine 2 type of blocks using the same basic consensus algorithm.
This old borked design is available here.
Well it turns out it’s not so simple. If it was, somebody would probably have thought of it before.
The problem here is that mining 2 types of blocks with 2 different type of rewards and mechanics creates conflicts during the block template creation mechanism, because all the contents of the block get hashed and verified by the network, not just some.
With Infrastructure Blocks we now have essentially 2 potential results of block hashing, which would mean the block hash has to be valid for 2 different types of content.
I will illustrate this with an image.
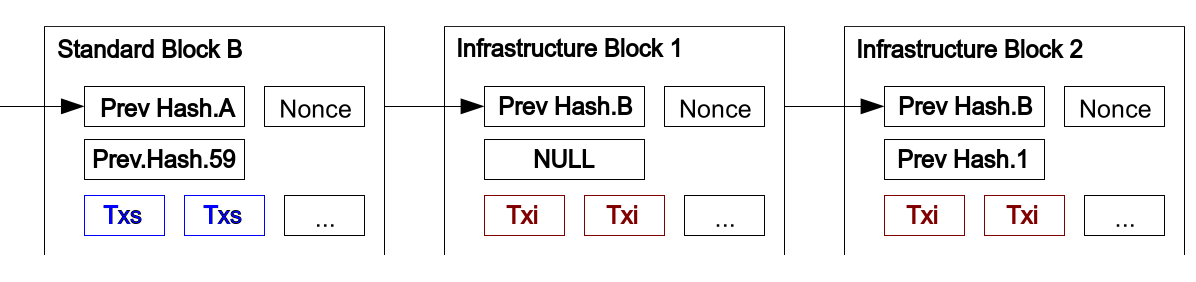
“Txs” are the standard transactions that get included into “normal” 10-minute blocks plus the coinbase payout transaction.
“Txi” are the extra-paid transactions that get included into the sub blocks, for extra fee, plus also the coinbase payout transaction, which is first.
These transactions are not the same transactions but completely different, which means that when they get hashed together with the rest of the block, it would result in a different block hash, whcih means two completely different blocks cannot result in the same block hash and the scheme is impossible to do.
The reason I did not notice this is that from the whitepaper it seemed like things can be hashed or not arbitrarily by the node and the hashing could be changed on the fly, depending on what kind of block we want to build, which is of course clearly nonsense. I did not check mining code and specification before, which resulted in this flawed design.
New re-design proposal.
I have devised a modification of the “merge/netsted” mining scheme that could work, it does have some potential significant drawbacks though. This time I will pull some feedback from the community before re-making the whitepaper, so that I waste less time on something that could ultimately not work at all.
I propose a “mirrored block scheme” where 2 variants of blocks get hashed separately (1 standard block and 1 corresponding infrastructure block) and then the 2 hashes get joined together by another hash round, thus forming a merkle tree structure.
The combined “mirror block” contains the data of 2 block candidates, but depending on whether block gets mined with difficulty D (normal difficulty) or Di (Infrastructure Block difficulty = D/60), different part of the block gets executed each time. Meaning,
- When the resulting block is mined with difficulty D, the “standard” mirror block gets executed and all “normal” transactions within it are processed
- When the resulting block is mined with difficulty Di, the “infrastructure” mirror block gets executed and all “infrastructure” transactions within it are processed
Following images illustrate the concept:
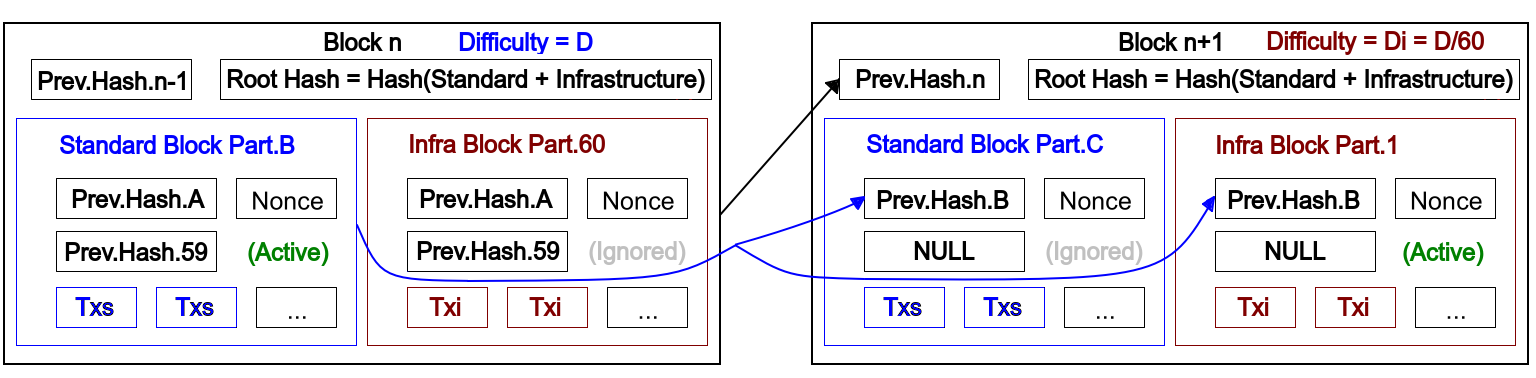
In the above example,
- Block n gets mined with difficulty D, meaning STANDARD block part is active and INFRASTRUCTURE block part is inactive.
- Block n+1 gets mined with difficulty Di = D/60, meaning INFRASTRUCTURE block part is active and STANDARD block part is inactive.
Basically, both of the parts (standard/infra) are mined ensuring that block is always valid, regardless whether it is mined as “standard” or “infra”, but one part of it gets “discarded” or “ignored”, which means it can be easily pruned after X blocks, where X could be set to coinbase payout time (100 blocks) or more.
Standard mirror block part gets ignored on average 59 times every 10 minutes, and infrastructure mirror block part gets ignored 1 time per 10 minutes - at that time standard block part is the executed part.
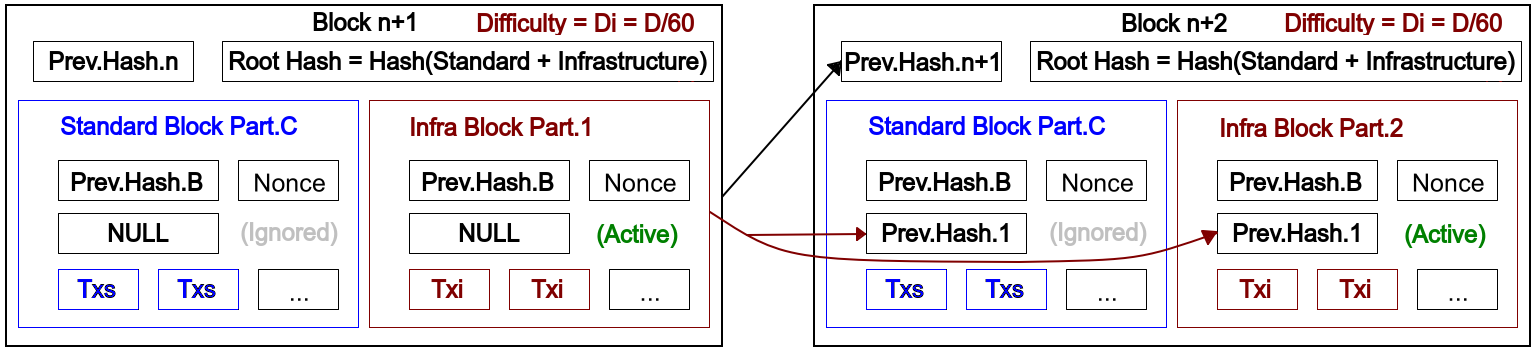
In the above example both blocks get mined with difficulty Di, resulting in both being effectively Infrastructure Blocks,
- In block n+1, INFRASTRUCTURE block part is active and STANDARD block part is inactive.
- In block n+2, the same
Downsides/tradeoffs and proposed solution to above problems
The obvious massive downside would be that the contents of the block candidate that is being built would have to be sent over the network 60 times every 10 minutes (= every 10 seconds), which means even if blocks reach gigabyte ranges, the whole block would have to be propagated in 10 seconds, which seems to be a significant issue at first.
However, it seems that there are multiple solutions to this problem, some of them already existing:
- Already existing: XTHINNER protocol.
Due to the existence of XTHINNER compression protocol, it could turn out that the block does not need to be broadcasted at all and in reality much less than 1% of block data will actually need to be communicated (previous tests show as high numbers as 99.54%). Source:
- Proposed: Progressive Incremental Block Compression.
During the creation of 59 blocks with difficulty Di every 10 seconds, the changes to consecutive standard block mirrored parts that are ignored/discarded are very small - because the block does not get executed in these 59 rounds. So it should be trivial to write differential algorithm that propagates only the changed parts to other miners (unless this is something that XTHINNER algorithm already does, then in such case we pretty much “have it” right now).
Such an algorithm would simply deliver to other miners the sub-hash (present in the merkle tree of the block) of previous mirrored block part and a “patch” that supplies new data that has changed in the last 10 seconds since it was mined. The miners can then use the data they already probably have and apply the patch, which saves all excess bandwidth.