QuantityOrFlags
The encoding is not standard. Please just reuse var-int as used in BCH already.
The reason VarInt is not used is because this number is a pushed CScript entity so it already has a size. Putting a VarInt in a script stack item specifies the size twice so it inefficient. VarInts also don’t appear in scripts. They are also complicated compared to what I specified which is basically just interpreting the number in standard little-endian format. This is very similar to what CScriptNum does except that CScriptNum has additional “minimal encoding” constraints. These minimal encoding constraints are not needed in Group prefixes because they are not malleable (do not appear in input scripts).
WRT using the lowest bit rather than the highest: Yes, it would use less room for the authorities. But use of authorities is rare compared to normal tx. And I think doing that would be a lot more confusing and likely buggy for normal use. Finally, there is a future use for some of those empty bits. In particular, they might define a maximum quantity of mint or melt that this authority can do. Doing this would be more rules though, so I think we should wait for a need to show up.
But I am willing to change this if the majority of the dev community wants it the more efficient, low bit way.
What about a 160 bit (ripe) based hash instead for the groupID?
It is generally agreed that P2SH is right on the edge with 160 bits due to the fact that for certain operations among multiple parties its security is actually 2^80 via wagner’s birthday attack. A similar attack is possible against groups where a group creator searches for a GrpId collision at difficulty 2^80 and then commits only one of the 2 transactions. This group could have a guaranteed limited supply via burning authorities. However, subsequently committing the 2nd transaction would recreate the authorities that the creator burned.
GroupIds will be highly compressible because they will be repeated a lot, especially when you consider that tokens will likely have exponential popularity (few tokens will constitute most of the transactions).
Group flag bits are part of the hash.
The group flag bits define the properties of the group which are not changeable. That would not be “fair” to holders. Also, its more efficient to do it this way.
confusing note
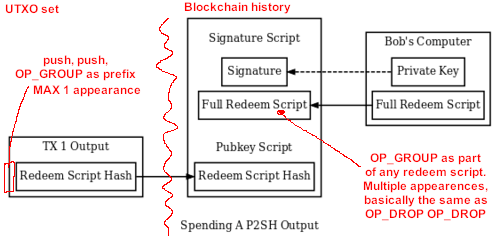
hmm yes I’m trying to say something obvious very pedantically. What I’m trying to say is that OP_GROUP only has group semantics if it comes first. But it can appear anywhere in the script and is just treated as a no-op that drops its 2 arguments. This makes implementation simple.
IsStandard Changes
What you are saying is the right way to implement it. OP_GROUP appearing anywhere except as the prefix is non-standard. You can’t quite drop it because it should be stored in the UTXO, etc… but basically you can skip executing it.
There was pressure years ago for the Group prefix to be interpretable as part of a normal script, since its in the “CScript”. Group could even be implemented as a soft fork by reusing one of the NO-OP instructions.
If no one cares about this anymore, then the most extensible way to do it is to make CScript be divided into an “attribute prefix” and then the actual script (if there is one). We could use a single leading opcode to identify such a “CAttributeScript”. There are other interesting attributes. For example, if there’s an opcode that pushes attribute N onto the stack then scripts that enforce constraints on other scripts could be much simpler to write since all the variable parts could be factored out into attributes. And really when you think about, P2SH is better conceived of as attribute: the hash of the script that will be supplied later. Its not a viable script which is why bitcoind needs to handle it specially.
But again I’d like to hear overwhelming support from the community for a change like that. Making OP_GROUP an executable opcode that just pops its args from the stack is the minimum-change path.
Subgroup ID
Note that the subgroup id is limited by the maximum stack size. I don’t have strong feelings about this or about what this number should be. But at a minimum, encoding another cryptographic hash makes sense since that hash can act as lookup-and-proof of some larger amount of data.
At the same time, I have always felt that we can solve data-on-blockchain problems by encouraging miners to charge more for data transactions (esp. now that double spend proofs exist), which is why I specced it this way.
So I’m happy with whatever BCHN as the majority hash power or the dev community at large chooses so long as its >= 32 bytes.