Is 16K the best target? Even x86 is well below 2000 right now. How about reserving 0xf0 through 0xff to leave space for 4000 two-byte opcodes?
I still expect we’ll never need more than 255. We’re not building a typical ISA – for example, a huge number of x86 instructions are really just slightly more performant ways of doing something already possible with existing instructions.
That sort of thing doesn’t apply to us: programmers on our ISA might have an adversarial relationship with the “computer”, and even if well-intentioned contract authors want to speed up validation performance (e.g. to get reduced network fees) the cost of even measuring which operations they choose to use is far more expensive than any micro-optimizations they implement for non-crypto operations. And crypto operations are practically the only meaningful burden on validation speed, for all other operations, the 1 satoshi-per-instruction heuristic is basically ideal.
E.g. we’d need to be dealing with >10 MB programs for the tiny differences between instructions like OP_SWAP, OP_TUCK, OP_NIP, etc. to even be measurable. If people want autonomous contracts of 10MB complexity, they’ll be far more efficiently implemented as two-way-bridged sidechains than directly in the BCH VM. (This is the strategic difference between BCH and ETH – BCH doesn’t aim to have all the world’s decentralized applications running on the same VM. We trade ETHs simpler mental model for better scalability by only doing the money-movement parts.)
So what future opcodes could make sense in the BCH model? (Just solidifying thoughts here:)
Control Flow – estimate: 10
-
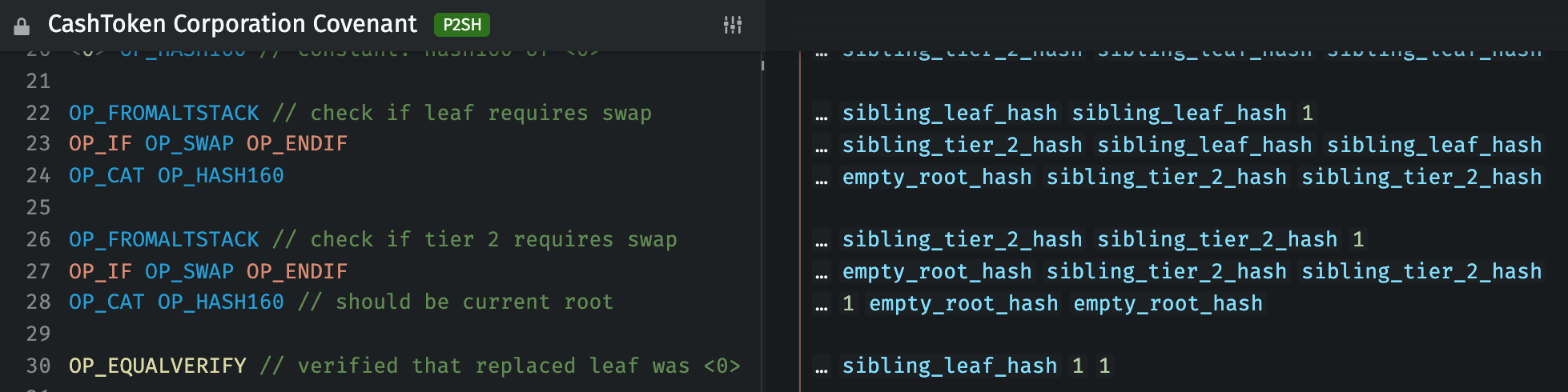
bounded loops – some operation where looped instructions still count toward the opcode limit, but e.g. merkle tree validation contracts don’t have to be filled with 8 duplicated copies of the merkle tree validation instructions. This would reduce contract byte size without affecting VM opcode limits. In CashTokens, OP_FROMALTSTACK OP_IF OP_SWAP OP_ENDIF OP_CAT OP_HASH160 is repeated for each layer of merkle tree depth:
-
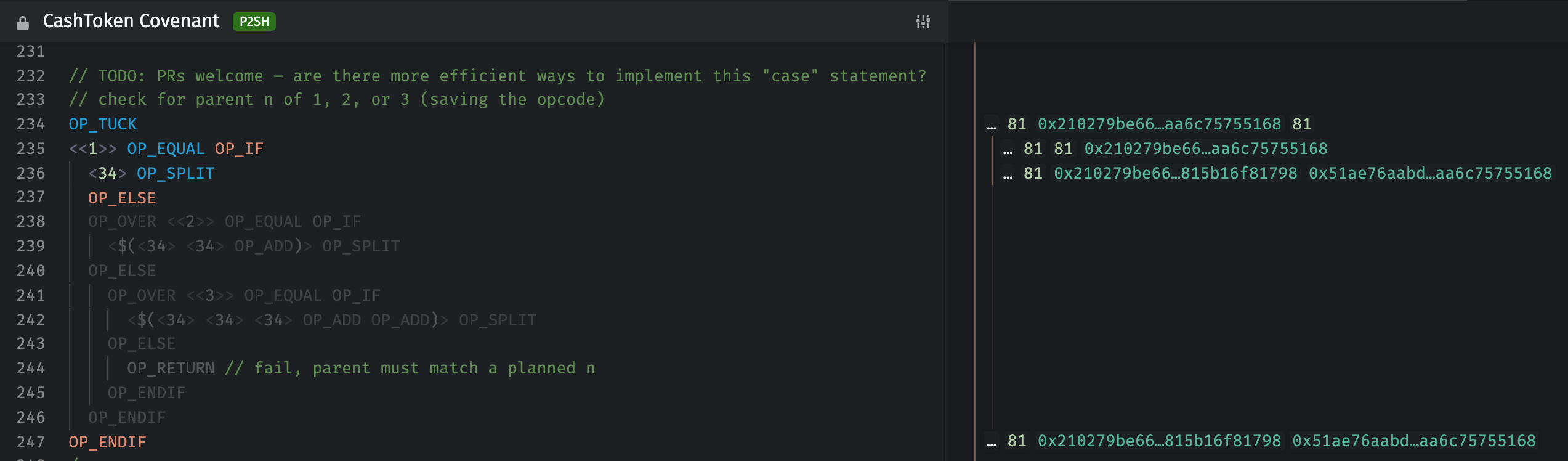
switches/matches – some construct for switching based on a value would save a lot of wasted OP_ELSE OP_OVER <value> OP_EQUAL OP_IF manipulations. You can see an “emulated” switch at line 232 of the CashToken Covenant:
Other control flow structures? I’ll shoot high and estimate 10 new opcodes.
Total: 10
Introspection – estimate: 13
Unless I’ve messed some VM state, there are exactly 13 “raw” VM state components (opcodes 189 through 201 in the draft spec).
Any other introspection opcodes would be producing computed results from these raw components, and I’d argue we should at least wait to implement any “VM computed” (aggregated, hashed, etc.) operations at least until they are extremely common in the wild. E.g. I’d prefer we implement “bounded loops” from above rather than add an aggregated OP_TOTALOUTPUTSVALUE.
I think it will be hard to justify non-raw introspection opcodes, so I’m just going to assume the base 13 here.
Total: 23
Formatting – estimate: 5
I’d define this category for operations like OP_BIN2NUM and OP_NUM2BIN. On the horizon, if we don’t implement some strategy like PMv3’s use of Script Number in the transaction format, we’ll need an OP_NUM2VARINT and OP_VARINT2NUM. (I would prefer that we change the transaction “packaging” rather than add complexity to the VM.)
Also, depending on how we solve for bigger integers, some people are advocating for a new larger number type in the VM. (I think we should just allow larger Script Numbers. We’re already stuck with Script Numbers, and fortunately they are signed and variable-width, so they can support whatever we need.) If we somehow ended up adding a new number type though, that would require an OP_NUM2WHATEVER and OP_WHATEVER2NUM.
I think both of those would be bad ideas, but I’m probably also missing some useful new possibilities like OP_REVERSEBYTES, so maybe it’s safest to estimate another ~5 opcodes for future formatting operations.
Total: 27
New Crypto – estimate by 2040: 8
We should note that Bitcoin Cash has been around for 12 years already, and hasn’t yet added any completely new crypto algorithms, and certainly none as opcodes. I think a very high estimate for this is up to 4 opcodes per 10 years. (And that’s only if we ultimately wanted to support things like incremental hashing with separate INIT, UPDATE, DIGEST operations. I’d personally prefer that hashing be non-incremental.)
Total by 2040: 35
Math – estimate: 10
This is the category I’m least sure about.
If we added support for very large integers, it would be possible to implement some crypto systems with standard math operations (assuming we figured out how to limit abuse – that gets very messy). I’m not sure what other operations this might require, but I also don’t expect we’ll want to do this, since it blurs the lines between the “expensive operations” (which right now are only the crypto operations) and “cheap operations” (all the other current non-crypto operations). We’d have to reevaluate a lot about DOS limit and fee estimation.
When on-chain IPO/ICOs start happening (selling shares for covenants and covenant-based sidechains), we’ll probably have use for exponentiation and logarithms. (Though a lot of those applications can probably make do with bounded loops and OP_ADD, OP_SUB, OP_MUL, OP_DIV, OP_MOD, etc. If we add native operations, that could be 2 to maybe 6 opcodes?
Looking at the Math operations available in JavaScript, we can reasonably emulate the rounding-related methods (round, ceil, floor), but I’ll add 1 to the max estimate anyways.
Then all that’s left is trigonometric functions – anyone have an idea of how those might be useful in the BCH VM? (Are there any market maker or security-pricing algorithms that require trig functions?) I’ll add 3 because  .
.
Total: 45
Have I missed anything? Is there some category of computation that could apply to transaction validation which we haven’t explored yet?
If not, I think we’re still well-within the 66 remaining undefined opcodes (OP_UNKNOWN189 through OP_UNKNOWN255), and that’s without recycling any previously defined opcodes.
Also, we’ll always be able to use OP_NOP opcodes as two-byte expansion opcodes, e.g. OP_NOP4 through OP_NOP10 would give us 255 more operations each, so 1,785 two-byte opcodes without even needing to reserve any range outside the OP_NOPs. (We could fit x86.  )
)
In the sprit of YAGNI, I’m fairly convinced we would regret jumping ahead to two-byte opcodes in the near future.

 ) so I had missed that many of these state elements really should accept and number from which to select and input or output (I had just missed the idea entirely until
) so I had missed that many of these state elements really should accept and number from which to select and input or output (I had just missed the idea entirely until  )
)


 I share Tom’s wonder at your insistence on these points. Tom’s proposal is to reserve some space (and I agree it doesn’t have to be that many but I could easily make arguments for designs that would benefit from it) for future expansion that we know we cannot anticipate. Crypto is like in the 1977 era of the PC revolution now. It’s wild west. We’re on freaking v1 of the tx protocol structure. That’s not going to be the case by the end of this decade. The things we will be addressing in 5 years will shock and amaze each and every one of us. Here’s an opportunity to be conservative and protect our ability to expand with pretty much zero downside. In my experience you never pass up such an opportunity.
I share Tom’s wonder at your insistence on these points. Tom’s proposal is to reserve some space (and I agree it doesn’t have to be that many but I could easily make arguments for designs that would benefit from it) for future expansion that we know we cannot anticipate. Crypto is like in the 1977 era of the PC revolution now. It’s wild west. We’re on freaking v1 of the tx protocol structure. That’s not going to be the case by the end of this decade. The things we will be addressing in 5 years will shock and amaze each and every one of us. Here’s an opportunity to be conservative and protect our ability to expand with pretty much zero downside. In my experience you never pass up such an opportunity.