
I had previously pondered the idea in few places:
- CHIP 2021-05 Targeted Virtual Machine Limits - #7 by bitcoincashautist
- and later in a Telegram chat:
bitcoincashautist, [10/25/24 8:37 AM]
I was just pondering my bytecode_patternizer and how I need to version it too because who knows maybe one day we declare 0x50 to be some special push op
bitcoincashautist, [10/25/24 8:37 AM]
I actually have an idea for it, make it into OP_PUSH_RAW_TRANSACTION
bitcoincashautist, [10/25/24 8:38 AM]
then the tx is decomposed and “loaded” into vm context and then you can use introspection opcodes on it
bitcoincashautist, [10/25/24 8:38 AM]
without need to manually use opsplit etc to parse it
Now it has come to my attention that Nexa has implemented OP_PARSE and will activate it in March 15th 2025.
This opcode automatically parses common types of script data (notably bytecode), extracting portions of that data and placing them on the stack.
This extracts data from buffers of data that is serialized in a specific format, as compared to OP_SPLIT which extracts data from buffers of any format by offset.One the the primary tasks of UTXO-family scripts is to constrain and verify properties of locking scripts. This is the only way to constrain the effects of a transaction. For example, let us suppose an author wants a spend clause that constrains an input to be only spent to a particular output. This example was chosen since it is simple yet an essential requirement of “vault” functionality and reversible payments. The author must write a script that accesses the output script and checks that its template hash and its args hash are equal to expected values. Today, to do so the author must use introspection to access the output script, and then write a small bytecode parser within bytecode itself to extract the template hash and args hash. While possible, this bytecode parser is a non-trivial piece of code. And without loops, the size of this code is proportional to the number of opcodes needed to be parsed to access the needed data. However, with OP_PARSE, accessing these two fields can be done in a single instruction.
My motivation is the same, to make it possible to have Script-validated refund transactions.
If we’d get bounded loops in 2026, that would make it possible to parse a wide range of transactions, but still - not all.
Problem: all transactions have same size limits, so you still can’t verify and parse too-big transactions because you have to replicate it in full as input script in the input doing the parsing. Not being able to parse some TXs would leave ugly edge cases for contracts. Also, if you try to do it multiple times you’d get proof amplification, which Jason’s PMv3 proposal had demonstrated:
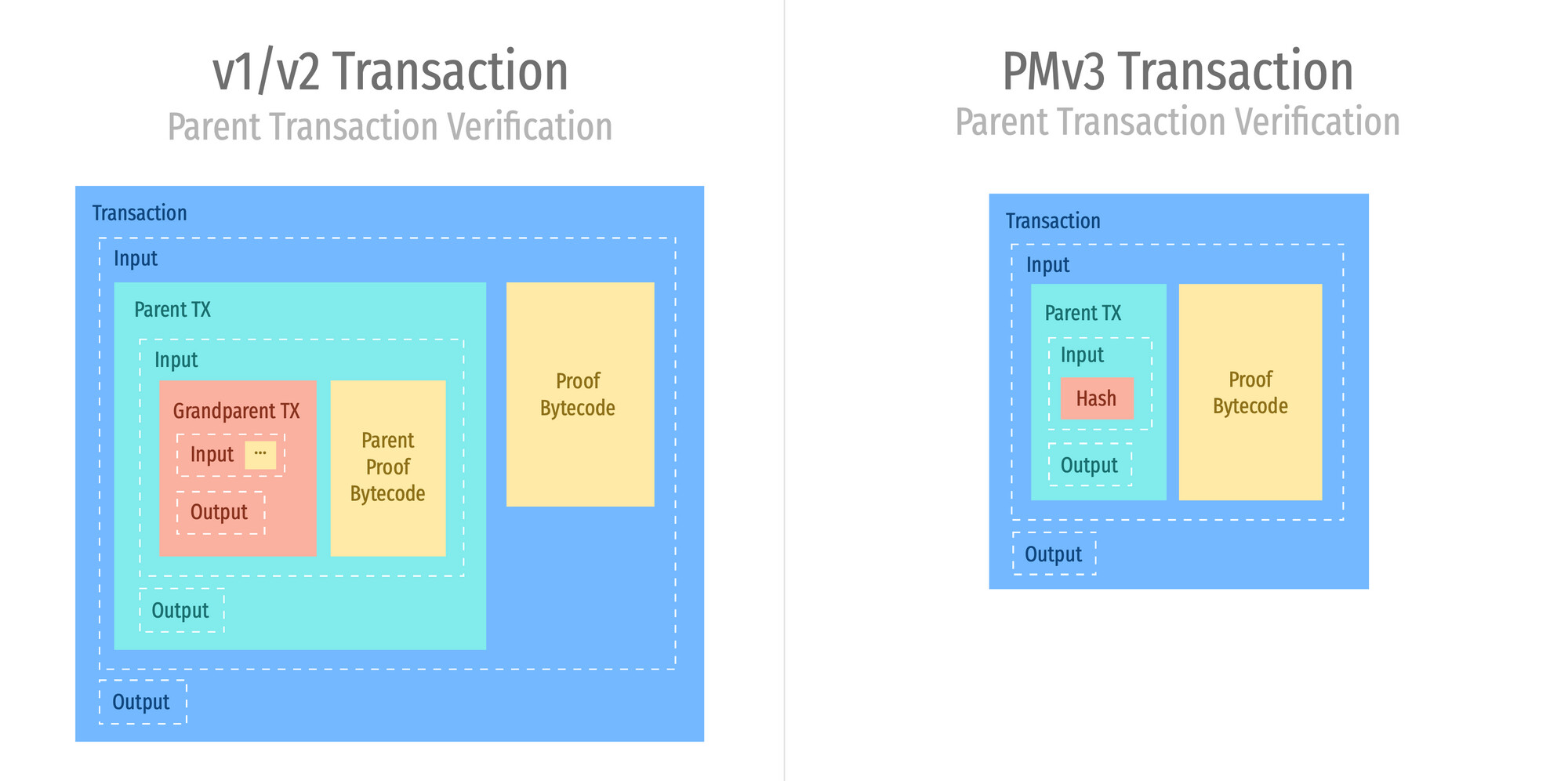
Could we fix this? The special push op would have to refer to a data structure outside the TX but committed somewhere in the block. This means something SegWit-like or PMv3-like or TXIDEM-like. In any case - the pushed raw TX data must not be part of TXID preimage.


