After some more discussion on Telegram, I think it might be helpful for me to copy/paste some of the “most interesting” parts of the CashToken Demo here for start-to-end viewing (and mobile readers).
If you’re on a modern desktop browser, you can also jump right into the CashTokens template on Bitauth IDE:
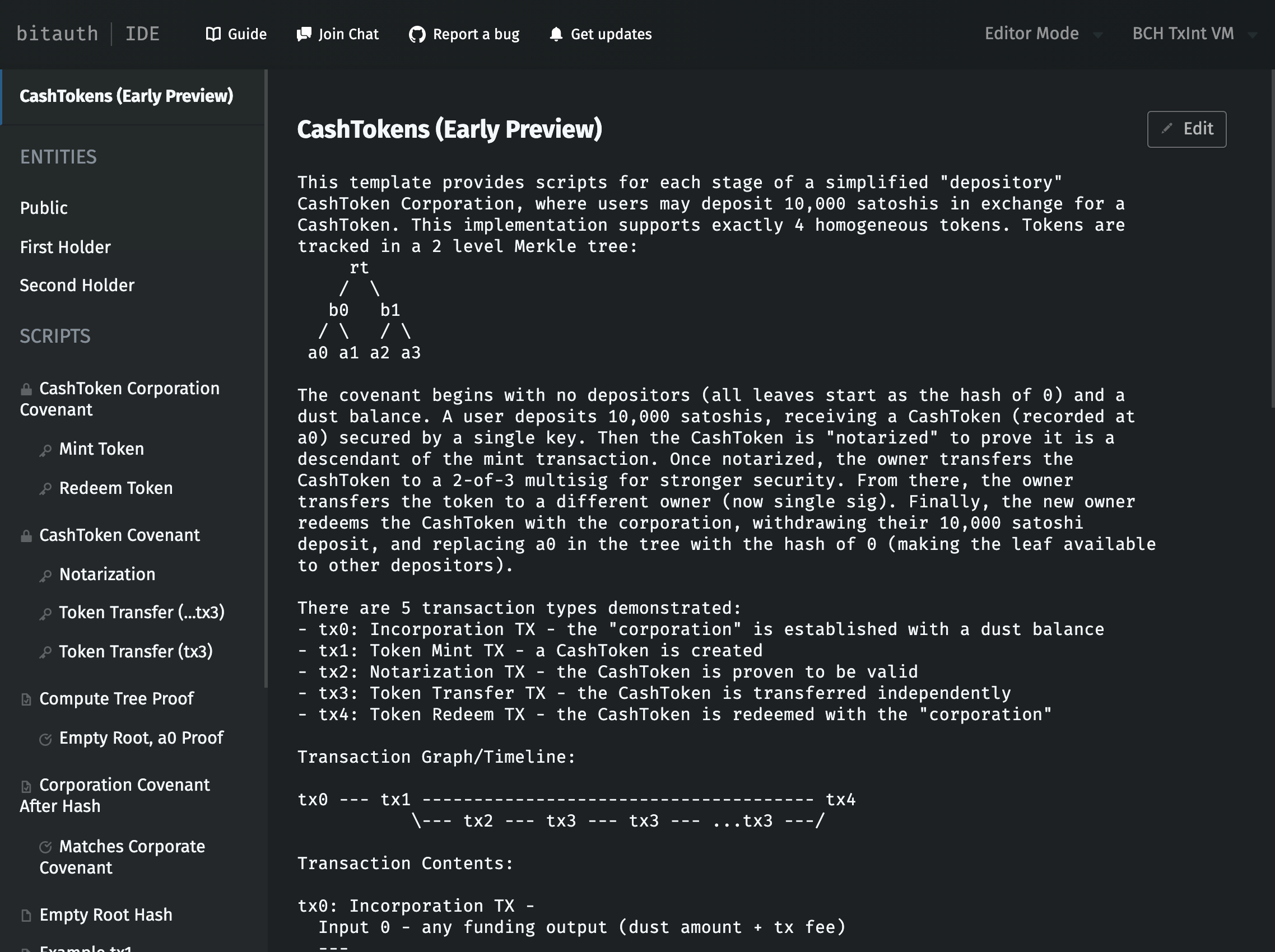
CashTokens Template Summary
This template provides scripts for each stage of a simplified "depository"
CashToken Corporation, where users may deposit 10,000 satoshis in exchange
for a CashToken. This implementation supports exactly 4 homogeneous tokens.
Tokens are tracked in a 2 level Merkle tree:
rt
/ \
b0 b1
/ \ / \
a0 a1 a2 a3
The covenant begins with no depositors (all leaves start as the hash of 0) and a
dust balance. A user deposits 10,000 satoshis, receiving a CashToken (recorded
at a0) secured by a single key. Then the CashToken is "notarized" to prove it is
a descendant of the mint transaction. Once notarized, the owner transfers the
CashToken to a 2-of-3 multisig for stronger security. From there, the owner
transfers the token to a different owner (now single sig). Finally, the new owner
redeems the CashToken with the corporation, withdrawing their 10,000 satoshi
deposit, and replacing a0 in the tree with the hash of 0 (making the leaf available
to other depositors).
There are 5 transaction types demonstrated:
- tx0: Incorporation TX - the "corporation" is established with a dust balance
- tx1: Token Mint TX - a CashToken is created
- tx2: Notarization TX - the CashToken is proven to be valid
- tx3: Token Transfer TX - the CashToken is transferred independently
- tx4: Token Redeem TX - the CashToken is redeemed with the "corporation"
Transaction Graph/Timeline:
tx0 --- tx1 -------------------------------------- tx4
\--- tx2 --- tx3 --- tx3 --- ...tx3 ---/
Transaction Contents:
tx0: Incorporation TX -
Input 0 - any funding output (dust amount + tx fee)
---
Output 0 - Corporation Covenant (dust amount)
Output 1 - change output
tx1: Token Mint TX -
Input 0 - tx0 output 0
Input 1 - any funding output (10,000 satoshi deposit + tx fee)
---
Output 0 - Corporation Covenant
Output 1 - CashToken Covenant (Token ID is tx0 hash)
Output 2 - change output
[Token circulates separately from the corporation covenant]
tx2: Notarization TX
Input 0 - tx1 output 1
Input 1 - any funding output (tx fee)
---
Output 0 - CashToken covenant
Output 1 - change output
tx3: Token Transfer TX
Input 0 - tx2 output 0
Input 1 - any funding output (tx fee)
---
Output 0 - CashToken covenant
Output 1 - a change output
[Token is redeemed with the corporation covenant]
tx4: Token Redeem TX
Input 0 - tx1 output 0
Input 1 - tx3 output 0
Input 2 - any funding output (for fees)
---
Output 0 - Corporation covenant
Output 1 - a change output (+10,000 satoshi withdrawal)
---
Additional Notes
Indestructible Dust – Once created, this CashToken corporation
implementation cannot be destroyed. The covenant could be modified
to allow the final dust balance to be collected from the covenant if all
shares are unallocated, but the additional bytecode required over the
life of the covenant is likely to be more costly than the dust amount "saved"
when the covenant is abandoned. It's worth noting that any bitcoin user
can create an unlimited number of dust outputs at any time, so dust from
covenants is irrelevant from the perspective of the network.
Token Mint (Unlocks the Corporation Covenant)
/**
* To mint a token we must prove:
* - TX output 0 is the next covenant state where:
* - the new tree replaces an empty leaf (<0>) with the covenant outpoint TX hash
* - requires: new tree root, all opposite nodes, proof path
* - the new covenant UTXO has a value of 10,000 satoshis greater than before
* - TX output 1 is the expected token pattern
* - requires: m-of-n and public keys to use for the token
*
* rt
* / \
* b0 b1
* / \ / \
* a0 a1 a2 a3
*
* This example verifies that a0 is `0`, then replaces
* it with the outpoint TX hash.
*/
<root_hash_after_mint> // rt
<sibling_tier_2_hash> // b1
<sibling_leaf_hash> // a1
<1> // tier 2 is left side (requires swap)
<1> // leaf is left side (requires swap)
<1> // enter branch: Mint Token
Corporation Covenant
<empty_root_hash> OP_TOALTSTACK
OP_IF
/**
* branch: Mint Token
*/
/**
* we need 2 copies of the "validation path":
* 1. confirm the leaf was empty
* 2. confirm the new root only changes that leaf
*/
OP_2DUP
OP_FROMALTSTACK OP_ROT OP_ROT // current_root_hash
OP_TOALTSTACK OP_TOALTSTACK
// First we confirm the leaf being updated was empty:
<4> OP_PICK // sibling_tier_2_hash
<4> OP_PICK // sibling_leaf_hash
<0> OP_HASH160 // constant: hash160 of <0>
OP_FROMALTSTACK // check if leaf requires swap
OP_IF OP_SWAP OP_ENDIF
OP_CAT OP_HASH160
OP_FROMALTSTACK // check if tier 2 requires swap
OP_IF OP_SWAP OP_ENDIF
OP_CAT OP_HASH160 // should be current root
OP_EQUALVERIFY // verified that replaced leaf was <0>
// Now we confirm that the new leaf uses outpoint TX hash
OP_TOALTSTACK OP_TOALTSTACK
OP_OUTPOINTTXHASH
OP_HASH160
OP_FROMALTSTACK // check if leaf requires swap
OP_IF OP_SWAP OP_ENDIF
OP_CAT OP_HASH160
OP_FROMALTSTACK // check if tier 2 requires swap
OP_IF OP_SWAP OP_ENDIF
OP_CAT OP_HASH160 // verified new root
OP_DUP OP_TOALTSTACK // save for later use
OP_EQUALVERIFY // new root is correct
// require that output 0 is 10_000 satoshis larger than last value
OP_UTXOVALUE
<10_000> OP_ADD
<0> OP_OUTPUTVALUE
OP_EQUALVERIFY // covenant has been paid properly
// require that the correct covenant script is used
<OP_PUSHBYTES_20>
OP_FROMALTSTACK // root_hash_after_mint
OP_UTXOBYTECODE // get this covenant's bytecode
/**
* OP_SPLIT is often unsafe for user input, but this input
* comes from the VM/previous contract.
*/
<21> OP_SPLIT OP_NIP // trim off previous root hash push
OP_CAT OP_CAT
OP_HASH160
<OP_EQUAL> <OP_HASH160> <OP_PUSHBYTES_20> OP_2SWAP
OP_CAT OP_CAT OP_CAT
// require that output 0 is the new covenant bytecode
<0> OP_OUTPUTBYTECODE
OP_EQUALVERIFY // TX pays to the updated covenant
// require that output 1 is a cashtoken UTXO
<1> OP_OUTPUTBYTECODE
<0xaabbccddee> // TODO: push expected cashtoken bytecode
/**
* We get the Token ID from the last covenant TX ID. This:
* 1) prevents tokens from being created to impersonate existing tokens
* 2) saves bytecode space (vs. pushing an ID)
* 3) avoid bugs in wallet implementations (validating at contract-level)
*/
// TODO: use <0> OP_OUTPOINTTXHASH to get the Token ID, concat into CashToken covenant
OP_EQUAL
OP_ELSE
/**
* branch: Redeem Token
* TODO: leaving out of first draft, see notes in unlocking script
*/
OP_ENDIF
Notarization (Unlocks Token Covenant)
/**
* This is the initial "Notarization" spend. It can only
* be successful if the parent (mint) transaction includes
* the outpoint TX hash referenced by the CashToken
* covenant (in its 0th output).
*
* To prove that this notarization step has been
* completed successfully, future spends need only
* prove that the covenant has previously been
* successfully spent.
*
* This implementation does not offer a way to transfer
* the token to a new set of holders during the notarization
* step. Rather, the notarization transaction must lock funds
* in a covenant with the same signing requirements as those
* specified in the mint transaction. This is a feature:
* notarization can be safely performed by anyone, making
* CashTokens slightly easier to implement in some types of
* wallets (and reducing the size of the covenant by saving
* on validation bytecode).
*/
<example_tx1> // TODO: switch to `<parent_mint_tx>`, fix scenario generation error (using `example_tx1` for `bytecode.parent_mint_tx`)
<0> <0>
Token Transfer (Also Unlocks Token Covenant)
/**
* This script is use to transfer a notarized CashToken between
* wallets. This implementation supports multisig wallets of
* up to 3 keys.
*
* Counterintuitively, the token transfer branch of this contract
* does not place any limitations on the outputs to which a token
* is spent. Instead, only its parent and grandparent transactions
* are validated to ensure the tokens lineage. However, because
* this covenant is impossible to spend without the proper
* "proof-of-lineage", if any transfer does not properly continue
* the covenant, the token is burned.
*
* This means it is always possible to "burn" the token in one final
* transaction – in this authentication template, the token should
* be burned/redeemed back into the parent corporation covenant
* (which itself then validates that the token's lineage was
* unbroken). With this strategy, the parent covenant can validate
* the authenticity of tokens.
*/
[...]
Token Covenant
/**
* This script is the key to the inductive proof. It's
* designed to be unspendable unless:
* 1. Its parent was the mint transaction funded by the transaction
* hash claimed (requires full parent transaction), or
* 2. It was previously spent successfully – the parent's 0th input's
* UTXO used this covenant, i.e. the parent's 0th-input-parent's
* 0th output uses this covenant. (Valiated by checking the full
* parent and grandparent transactions.)
*
* With these limitations, if a user can move the CashToken,
* we know the CashToken has the lineage it claims.
*/
/**
* By "baking-in" the code branch selection, we prevent the
* CashToken from being unecessarily notarized multiple times.
*/
<is_notarized>
// mint parent hash: the outpoint TX hash in the 0th output of the mint transaction
<tx0_hash>
OP_TOALTSTACK // tx0_hash
OP_TOALTSTACK // is_notarized
<1> // threshold (m)
// push n public keys (up to 3)
// TODO: convert to variable
<first_holder_key.public_key>
<1> // count (n)
/**
* Though this is only checked by the transfer branch,
* it drops all ownership-related items from the stack
* more efficiently than can be done with manual dropping
* operations.
*
* Note, notarizations could be restricted to token owners by
* replacing this with OP_CHECKMULTISIGVERIFY.
*/
OP_CHECKMULTISIG
// in both branches, verify the full parent transaction is provided
OP_DUP
OP_HASH256
OP_OUTPOINTTXHASH
OP_DROP OP_DROP // debug: switch comment to skip check
// OP_EQUALVERIFY // verfied provided transaction is parent
OP_FROMALTSTACK // is_notarized
OP_NOTIF
/**
* Notarization branch:
* Prove that this transaction's parent is the claimed token mint transaction,
* i.e. its 0th input spends from the claimed token ID (outpoint TX hash).
*
* Note, this branch can be executed by any interested observer (doesn't
* require access to any private keys), so it must be carefully validated
* to avoid griefing.
*/
OP_DROP // drop failed multisig check
<4> OP_SPLIT OP_NIP // remove and discard tx version
<1> OP_SPLIT OP_SWAP // get first byte of tx input count
/**
* Between 0 and 127, Script Numbers and VarInts are compatible.
*
* 127 (`0xfc`) is the largest integer which can be represented
* by the Script Number format in a single byte (0x80 begins
* the range negative 0 through 127).
*/
<2> OP_EQUALVERIFY // require exactly 2 inputs (covenant + fee funding)
<32> OP_SPLIT OP_DROP // get 0th outpoint tx hash, drop everything else
OP_FROMALTSTACK // tx0_hash
OP_EQUALVERIFY // Token ID verified: parent transaction spends from claimed outpoint tx hash
/**
* Verify the transaction's 0th output is re-assigned
* the updated covenant.
*/
OP_UTXOVALUE
<0> OP_OUTPUTVALUE
OP_EQUALVERIFY // require output value to be the same
<OP_HASH160 OP_PUSHBYTES_20>
<OP_1> OP_UTXOBYTECODE
<1> OP_SPLIT OP_NIP OP_CAT // remove is_notarized of OP_0, replace with OP_1
OP_HASH160 <OP_EQUAL>
OP_CAT OP_CAT // expected P2SH bytecode
<0> OP_OUTPUTBYTECODE
OP_EQUAL // 0th output bytecode is correct
/**
* TODO: further optimization: after notarization, can we prune the
* notarization branch?
* Requires other changes to validation in both convenants.
*/
OP_ELSE
/**
* Transfer branch:
* Prove that the outpoint tx spends from this same covenant. Then
* prove that this transaction is signed by the required private key(s).
*
* Note: to save space, this branch doesn't validate the locking bytecode
* to which the transaction pays, making it possible for wallets to burn
* the CashToken (intentionally or due to a bug). This is unlikely to
* be a problem in practice because CashTokens can only be moved by
* wallets which support the CashToken covenant template (no
* backwards-compatibility with wallet which might unintentionally
* burn tokens).
*
* By not forward-validating outputs, we elliminate the need for each
* CashToken covenant to be capable of correctly "identifying" its
* parent covenant during redeem transactions. (Instead, we verify the
* lineage of the token by checking its parent and grandparent.)
*/
OP_VERIFY // Signature validation must have been successful
// Owner has authorized transfer, now prove lineage:
// get parent tx's outpoint tx hash, then verify we have the grandparent
<4> OP_SPLIT OP_NIP // remove and discard tx version (no validation)
<1> OP_SPLIT OP_SWAP // get first byte of tx input count
<0x02> OP_EQUALVERIFY // require exactly 2 inputs
<32> OP_SPLIT // get parent outpoint tx hash
<4> OP_SPLIT OP_DROP // get parent outpoint index, drop everything else
OP_BIN2NUM
<0> OP_EQUALVERIFY // must be grandparent's 0th output (grandparent may be 1th for mint)
OP_TOALTSTACK // parent outpoint tx hash
// validate and concat grandparent back together, confirming it used this covenant
<
0x02000000 // always require version 2
0x02 // always require exactly 2 inputs
>
OP_SWAP // top is grandparent input 0 outpoint (hash + index)
OP_SIZE <36> OP_EQUALVERIFY // require grandparent input 0 outpoint to be 36 bytes
OP_CAT
OP_SWAP // top is grandparent input 0 bytecode
OP_SIZE
OP_DUP
<4> OP_ROLL OP_EQUALVERIFY // provided bytecode is expected size
OP_NUM2VARINT // serialize length
OP_SWAP
OP_CAT
OP_CAT // grandparent TX up to input 1
OP_SWAP // top is grandparent input 1 outpoint (hash + index)
OP_SIZE <36> OP_EQUALVERIFY // require grandparent input 1 outpoint to be 36 bytes
OP_CAT
OP_SWAP // top is grandparent input 1 bytecode
OP_SIZE
OP_DUP
<4> OP_ROLL OP_EQUALVERIFY // provided bytecode is expected size
OP_NUM2VARINT // serialize length
OP_SWAP
OP_CAT
OP_CAT // grandparent TX through inputs
// start building grandparent outputs
OP_SWAP // top is grandparent is_notarized
<0> OP_EQUAL
OP_IF
/**
* Grandparent is not notarized (mint transaction), the 1th output is the covenant.
*/
<3> OP_CAT // require exatly 3 outputs in mint transaction
OP_SWAP // top is 0th output satoshi value
OP_SIZE <8> OP_EQUALVERIFY // satoshi value must be 8 bytes
OP_CAT
<$(<23> OP_NUM2VARINT)> // length of corporate covenant bytecode (P2SH)
OP_CAT
OP_SWAP
OP_SIZE <23> OP_EQUALVERIFY // corporate covenant bytecode must be P2SH length
OP_CAT
// end of 0th output
OP_ELSE
/**
* Grandparent is notarized, the 0th output is the covenant.
*/
<0x02> OP_CAT // require exactly 2 outputs in transfer transactions
OP_ENDIF
OP_SWAP // top is grandparent's cashtoken covenant value
OP_DUP
/**
* To support heterogenous tokens, this covenant prevents the
* satoshi value of the token from changing during transfers.
*
* However, we can't simply verify the "next" satoshi value is the
* same as the "current" value - eventually, the token will be
* redeemed with the corporation covenant, and the covenant's
* expected balance at that time can't necesssarily be predicted.
*
* Instead, we only verify backwards by comparing the token output
* values of the grandparent and current transaction. With this
* limitation, we can know the token's value can't be modified
* until the redeem transaction, where the parent covenant can
* read the value before it is destroyed.
*/
OP_UTXOVALUE <8> OP_NUM2BIN
OP_EQUALVERIFY // disallow token value from being modified
OP_CAT
< <23> OP_HASH160 > OP_CAT // length of cashtoken covenant bytecode (P2SH)
// begin transforming parent bytecode into grandparent bytecode for validation
<OP_0> // is_notarized for mint transactions
OP_UTXOBYTECODE // get parent bytecode
<1> OP_SPLIT OP_NIP OP_CAT // replace is_notarized with OP_0
<36> OP_SPLIT // preserve token ID (OP_0 + OP_PUSHBYTES_32 + 32 bytes + OP_TOALTSTACK + OP_TOALTSTACK)
<1> OP_SPLIT OP_NIP // remove parent threshold pushing opcode (<<m>>)
<3> OP_ROLL // add grandparent_threshold pushing opcode
OP_SWAP // top is parent bytecode after removed m push
<4> OP_ROLL // get parent public key count opcode
// TODO: PRs welcome – are there more efficient ways to implement this "case" statement?
// check for parent n of 1, 2, or 3 (saving the opcode)
OP_TUCK
<<1>> OP_EQUAL OP_IF
<34> OP_SPLIT
OP_ELSE
OP_OVER <<2>> OP_EQUAL OP_IF
<$(<34> <34> OP_ADD)> OP_SPLIT
OP_ELSE
OP_OVER <<3>> OP_EQUAL OP_IF
<$(<34> <34> <34> OP_ADD OP_ADD)> OP_SPLIT
OP_ELSE
OP_RETURN // fail, parent must match a planned n
OP_ENDIF
OP_ENDIF
OP_ENDIF
/**
* TODO: SECURITY: do we need to validate these bytes? (E.g. in the
* corporation covenant, they must be validated.) Can a malicious
* grandparent transaction use different opcodes in these bytes to
* defraud future token holders?
*/
OP_NIP // drop the removed parent public key pushes
OP_NIP // drop the parent public key count opcode
<1> OP_SPLIT OP_NIP // drop parent n opcode from bytecode
<4> OP_ROLL // pick grandparent public key count opcode
// TODO: PRs welcome – there are definitely more efficient ways to implement this one
OP_DUP
<<1>> OP_EQUAL OP_IF
<OP_PUSHBYTES_33> <6> OP_ROLL OP_SIZE <33> OP_EQUALVERIFY
OP_CAT
OP_ELSE
OP_DUP <<2>> OP_EQUAL OP_IF
<OP_PUSHBYTES_33> <6> OP_ROLL OP_SIZE <33> OP_EQUALVERIFY
OP_CAT
<OP_PUSHBYTES_33> <7> OP_ROLL OP_SIZE <33> OP_EQUALVERIFY
OP_CAT OP_CAT
OP_ELSE
OP_DUP <<3>> OP_EQUAL OP_IF
<OP_PUSHBYTES_33> <6> OP_ROLL OP_SIZE <33> OP_EQUALVERIFY
OP_CAT
<OP_PUSHBYTES_33> <7> OP_ROLL OP_SIZE <33> OP_EQUALVERIFY
OP_CAT OP_CAT
<OP_PUSHBYTES_33> <7> OP_ROLL OP_SIZE <33> OP_EQUALVERIFY
OP_CAT OP_CAT
OP_ELSE
OP_RETURN // fail, grandparent must match a planned n
OP_ENDIF
OP_ENDIF
OP_ENDIF
OP_SWAP OP_CAT // concat grandparent n opcode after public key pushes
OP_SWAP
OP_CAT OP_CAT OP_CAT // reconstructed grandparent redeem bytecode
OP_HASH160 // get redeem script hash
OP_CAT
<OP_EQUAL> OP_CAT
OP_SWAP // top is remaining TX serialization
// no need to verify remaining grandparent outputs
OP_CAT // full grandparent transaction
OP_HASH256 // grandparent transaction hash
OP_FROMALTSTACK // outpoint tx hash from parent
OP_DROP OP_DROP <1> // debug: switch comment to skip check
// OP_EQUAL // verify grandparent is parent outpoint tx
// (don't bother dropping the mint parent hash left on altstack)
OP_ENDIF
Again, these are just the most important parts.
As you can see, I’ve made comments documenting many design decisions and noting various security and usability concerns. You can read a more thorough intro on the CashToken Demo Gist.
If you’re on a supported browser, you can also jump right into the CashTokens template on Bitauth IDE to experiment with the full evaluation traces.
PMv3’s “hashed witnesses” allow scripts like the above Token Covenant to “compress” their parent transaction’s witness data (by hashing it), avoiding the uncontrolled growth in transaction sizes which currently prevents covenants from introspecting parent transactions. The second change proposed by PMv3 allows scripts to parse the integer format used in these parent transactions by making them compatible with the existing Script Number format. (Which also happens to save ~5% in transaction sizes.)



