It’s assuming you’d do this, so dominant pool hash-rate wise still has its advantages. However, it would use the tie-breaker on blocks received from others, so pools with higher ping would still have a chance of winning races.
Wouldn’t expected ROI be negative? E.g. you had a valid block with no competition and you withheld it then in doing so you allowed someone else to mine a block that will flip yours with 50:50 chance.
What if we don’t give attackers the time? Independent researcher zawy was suggesting to enforce block timestamps to be monotonic (each block must advance at least by 1 second) AND have nodes have very strict future time limit (e.g. max. 6 seconds ahead of their local clock).
It has whole uncle branches, we could call it branch rate or something. Anyway, thanks for confirming that the branch rate is the same no matter what you do on a branching event (orphan or merge).
All these schemes rely on changing the impact of branching. We can’t remove branching at the lowest unit of PoW.
The mentioned papers make it clear that the ROI is positive for strong miners and \gamma = 0.5. It’s even positive for \gamma = 0 (no reordering possbile). I argue that your change achieves something similar to \gamma = 0.5. Whether this an improvement or not depends on whether you find \gamma = 0.5 a realistic network assumption.
Well, withholding gives the attacker more time to mine the next block. Your flip scenario applies if the attacker is unlucky and cannot mine a block in time. But if he is lucky, he now has a private chain of height n+1 while the defenders are still indecisive about height n. With the deterministic tie breaker they are decisive about height n, but this does not help with respect to the n+1 chain.
I support this. It does not add any barriers for implementing proper economic security through Avalanche down the line. An argument that seems to be missing in this debate, is that faster blocks increase censorship resistance since it’s easier for solo miners and small pools to find a block. As long as orphan rate is reasonable and you don’t centralize because of this.
Unsure if asking for my thoughts on something specific in this thread or the CHIP in general.
I do not want to rehash the discussion about the merits of tailstorm so i will focus on the issues i have with the implementation of the tick system outlined in the CHIP. To me it seems his chip seems like a giant trade-off between getting some features of tailstorm and having a tick system spread throughout the codebase vs implementing tailstorm itself and not needing the tick system.
I understand tailstorm itself is a decent amount of work to implement but it does not touch the external systems nearly as much as this tick system. A lot of the tailstorm changes are internal to the tailstorm protocol and would only be preset in the tailstorm section of the code.
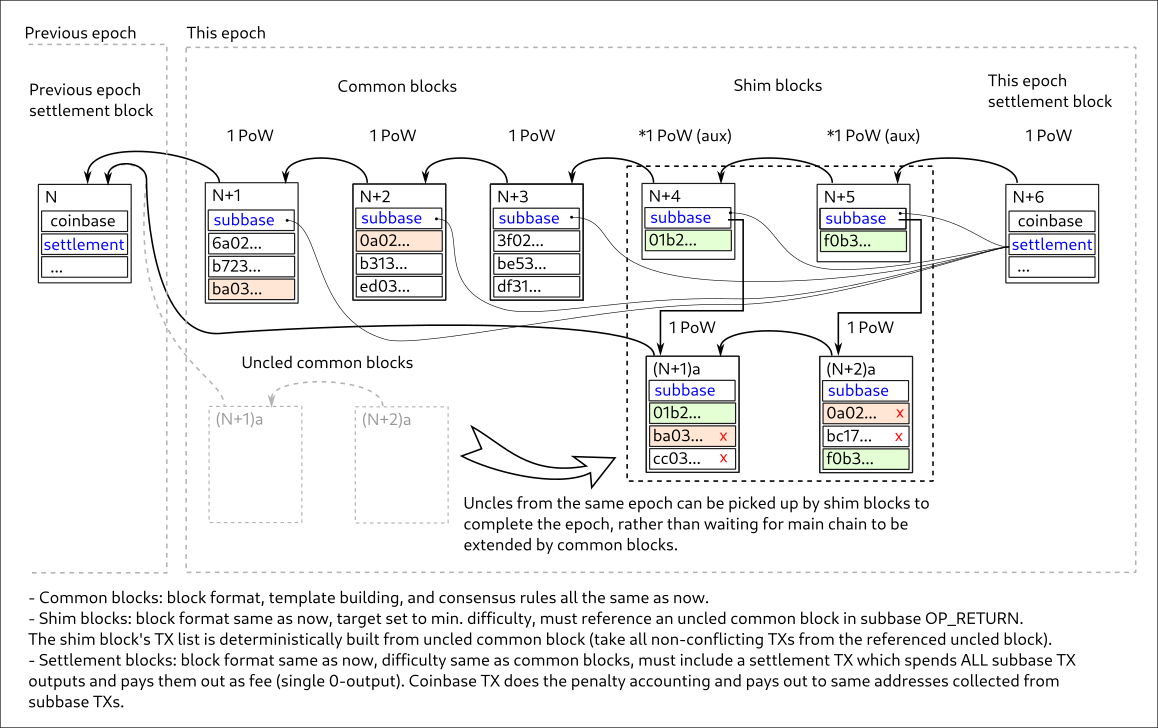
As noted in the technical description here, the tick system changes the subsidy schedule, DAA, ABLA, timekeeping in both script and the tx level, coinbase comments, sigchecks, blockheader rate, and rpcs. Tailstorm does not change most of those things in any significant way.
DAA, ABLA, timekeeping, sigchecks, and block header rates - All of these are unchanged in tailstorm. They would only update every ~10 minutes when new summary blocks are published. Same as they do now for bitcoin blocks.
coinbase comments - i do not think these would change at all either but i would have to check the bch tailstorm testnet code to be sure.
subsidy schedule - This would remain the same at the summary block level in terms of blocks mined. no shortfall that would cause it to end sooner. The total amount paid out might be slightly less than the 21M target, but the last block that pays a subsidy is the same.
rpcs - yeah, additional rpcs would be needed.
As for future proofing… Because there is no need to store all full subblocks after a summary block is formed, changing K should always be a backwards compatible change keeping the calculations that involve K relatively clean. add in some if statements relevant to the fork, post fork remove the if statements and only use the new value. eliminating the need for annoying calculations like this one tick = H_a * 600 + (H_b - H_a) * 60 + (height - H_b) * 30 every time there is a HF to tweak the tick rate
Idk. i find it preferable to keep the changes contained. I am not particularly a fan of the tick system for that reason. it touches too much.
Hey thanks for having a look at the CHIP! (note my orphan rate analysis is off a little, need to correct it)
What makes Tailstorm Tailstorm? Is it the uncle branch merging / reward system, or the faster-blocks-as-a-soft-fork aspect of it?
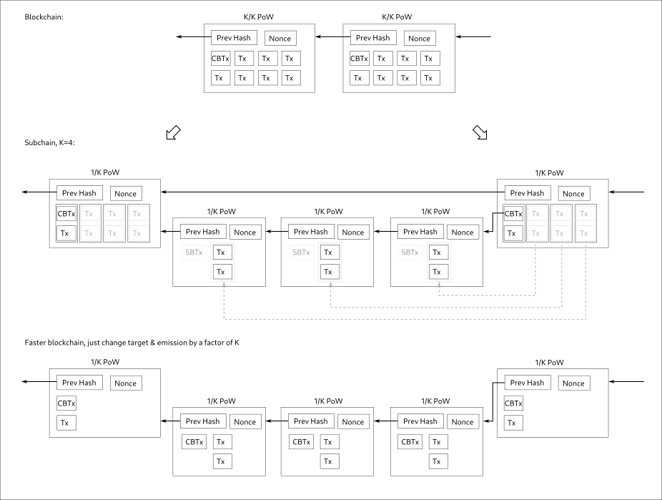
You could retrofit Tailstorm merging to this tick system, and we could just have faster blocks as “subchains” without the merging system. Basically we have 4 options:
So your preference is with the subdivision approach, got it! Uncle merging only affects consequences of branching rate. The inner/outer approach affects impact on downstream software and affected consensus rules. Let’s just assume we don’t want merging and focus on this aspect. Call it subchains.
I already made a comparison table here, but you made me realize there’s more to consider.
Does this mean that with original Tailstorm you don’t get the benefits of increased time granularity in contracts?
Those wanting to consider subconfs still need to switch to some new rpcs. Difference is opt-in vs breaking. Thankfully we can update RPCs ahead of faster blocks HF and encourage switching beforehand so the HF goes smooth. Example:
There’s another way to eliminate it: turn the block time into a state associated with each block like ABLA’s internal state. That would make it possible to have variable block time (like Kaspa and Nervos have), but I think there’s no need for that and has many unknowns on game mechanics.
Anyway, it’s a simple calculation easy to extend a bunch of times, we don’t expect to make more than a few adjustments.
Yes, and by implementing Avalanche we will remove the incentive for big miners to centralize because of high orphan rate. Because under Avalanche it will no longer be up to the miners which block they can build on.
This isn’t the status quo, though. They’re not centralizing because of high orphan rate because we don’t have high orphan rate, and 1-2% if switching to faster blocks will still not be high enough to have meaningful centralizing effect.
Tailstorm subblocks are not blocks. The blockchain is only updated when a summary block is published. You can use the depth of a subblock in the tree to calculate the probability that a tx will be included in the next block. for example, if you issue a tx right after a summary block is issued it should show up in the first subblock. every subblock after that increases the odds that your tx will be in the next summary block. under the current bitcoin model you have to wait for the next block to be mined to know if your tx got mined. i have the formula for that somewhere…
But subblocks themselves are not a new block in the blockchain. This is why it does not affect any of tx time stuff or other things i mentioned earlier.
I guess it is also worth mentioning that in the implementation of tailstorm we wrote that two subblocks with competing transactions (spent the same inputs in different ways) were not allowed in the same subblock tree. if two subblocks like this were mined then the node keeps track of two trees, three if there were 3 competing subblocks, and so on. Only one tree in this forest would become the next summary block. subblocks not in the tree that got completed to become a summary block were entirely discarded and they had no affect on the mining rewards the summary block paid.
And to just reiterate, faster blocks with tailstorm would theoretically see lower orphan rates than faster blocks without tailstorm, correct? The more subblocks the lower the orphan rate (though iirc there are diminishing returns (but the returns are less diminishing as you go to faster block times - i.e. as block times shorten, you benefit from a greater quantity of subblocks)).
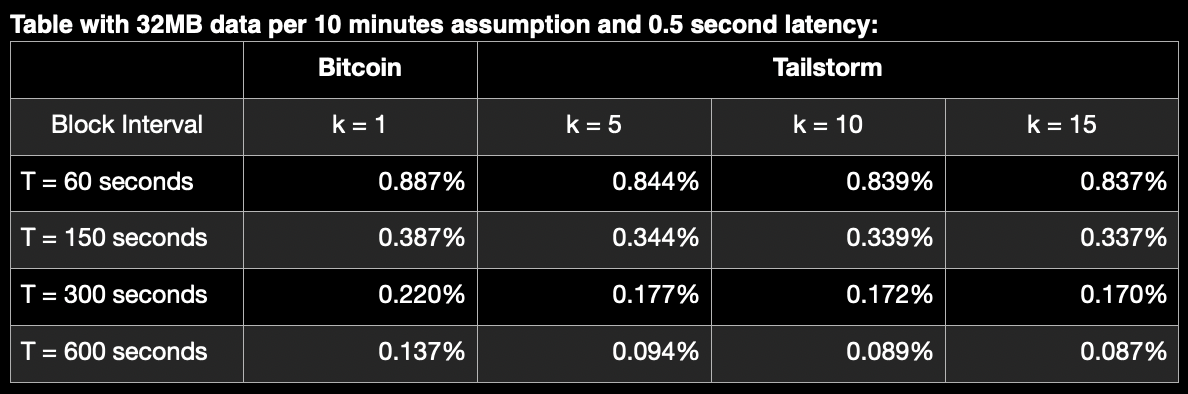
Yeah, just pulled up my old recalculation of orphan rates (original table had some flaw) and I believe what I stated here is accurate. Basically, as block times shorten, the delta between orphan rates, as subblock quantity increases, remains higher compared to the same subblock quantities with longer block times. But confirmation still would be helpful!
Hm, now that I’m thinking about this, I should create a new table that actually lowers the blocksize as the block interval shortens. That would give an even clearer picture. I believe the above is actually keeping 32MB blocks even at the shorter intervals. Let me do this and post a new table.
Interesting! So when I update for block size diminishing returns does come back at faster block times. Which actually makes sense.
Now, these are high orphan rate maxes but this is also assuming a latency of 5 seconds (per the tailstorm paper). I can update for a more realistic one if requested.
@bitcoincashautist Is there a reason you are using the orphan rate cap calc you have in the CHIP vs the one used in the tailstorm paper? The tailstorm paper formula was derived from Peter Rizzun’s orphan rate calc ( Peter R. Rizun. Subchains: A technique to scale bitcoin and improve the user experience. Ledger, 1:38–52, 2016.), which provide the below orphan rates at different block times (I adapted one to represent 1min blocks).
There are notably lower orphan rate limits. Tho perhaps I’m missing something.
Also, this paper might be a great reference for other things if you haven’t already looked (1.3 MB)
I think the CHIP uses basically the same formula as k=1, just a bit rearranged, and different latency and bandwidth (or impedance, if you will, which is 1/bandwidth) estimates.
Is it, though? I’m not certain, as I recall from reading the paper because of the parallel PoW mechanism, there might actually be less overall waste. But, I could absolutely be wrong here and as I’m not an expert, I’ll drop that here haha
The other benefits of tailstorm are irrelevant here so I’ll look back and mention on another chain.
Also, none of this CHIP would prevent tailstorm from being implemented in the future, if deemed necessary, so again, mostly irrelevant discussion for here beyond orphan rates.





 (1.3 MB)
(1.3 MB)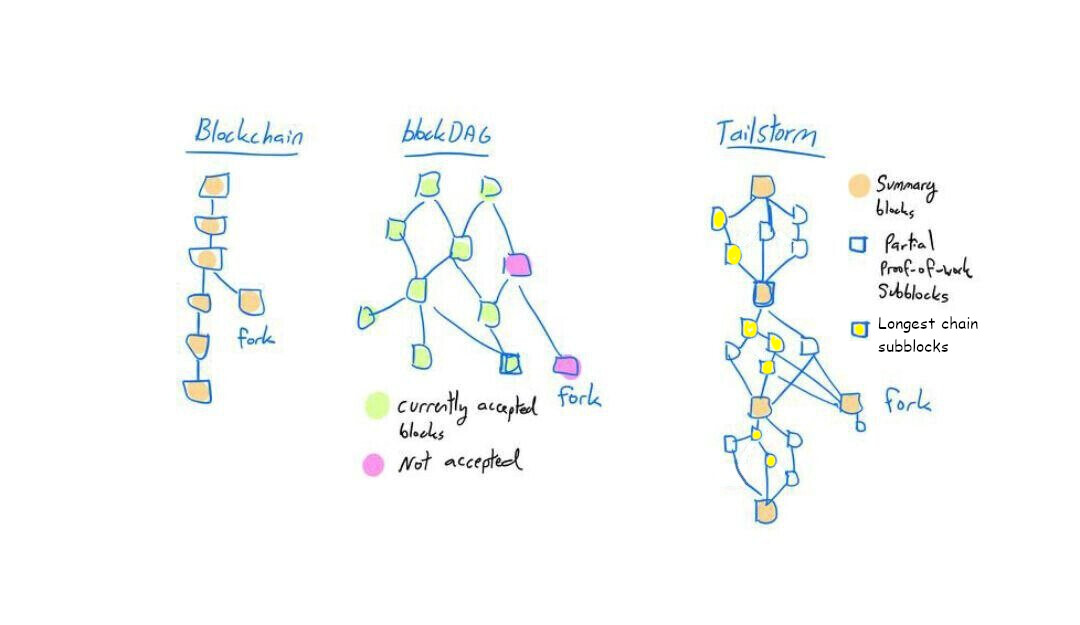{kind=link}
{kind=link}
{kind=link}