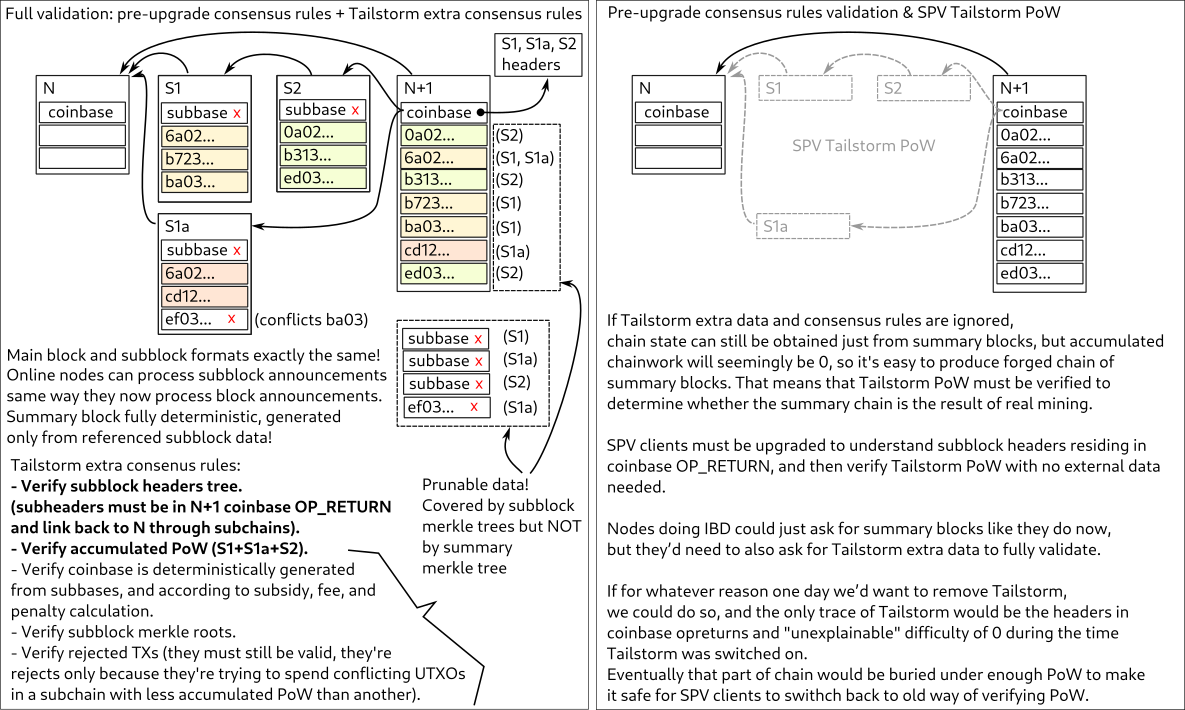
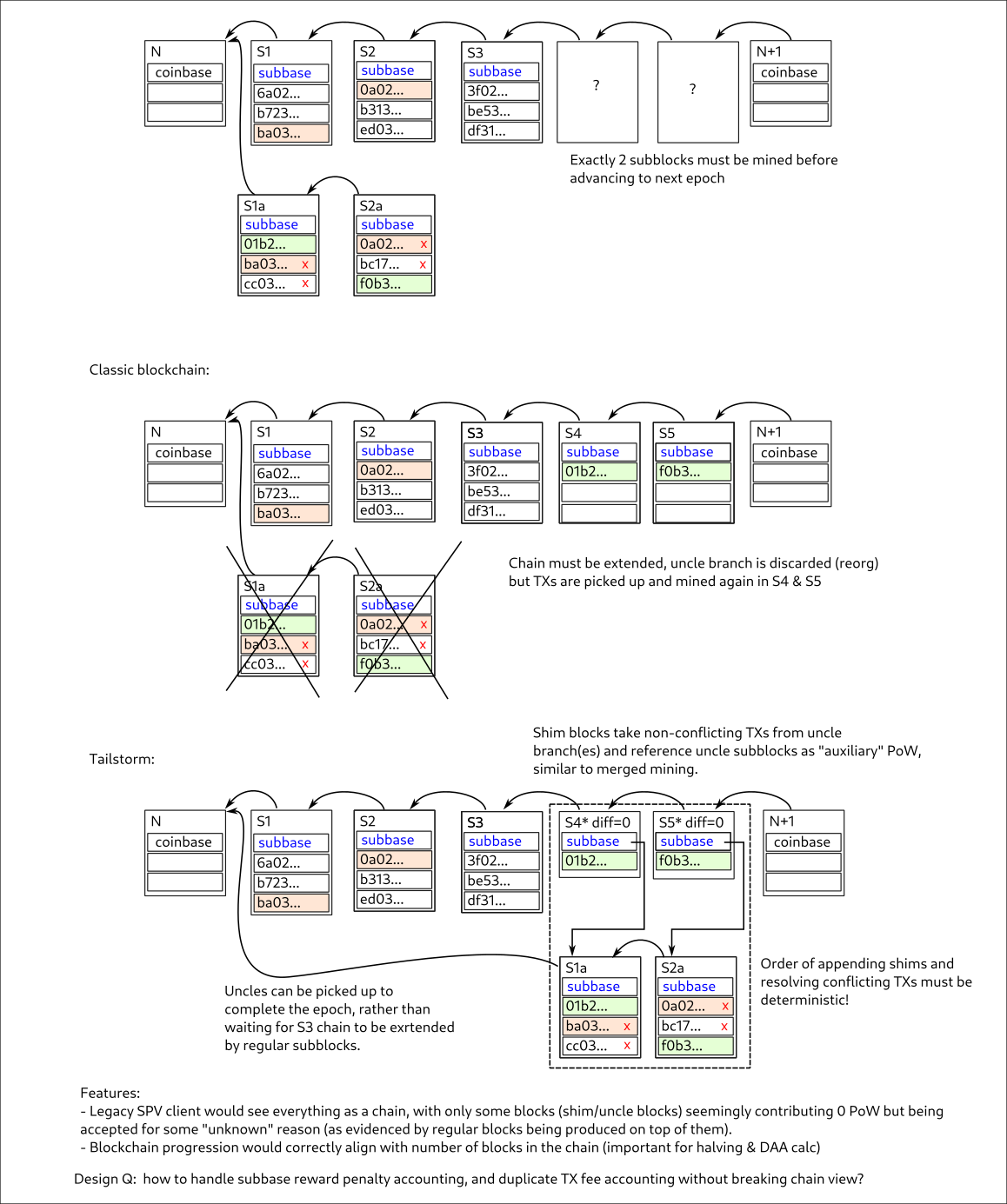
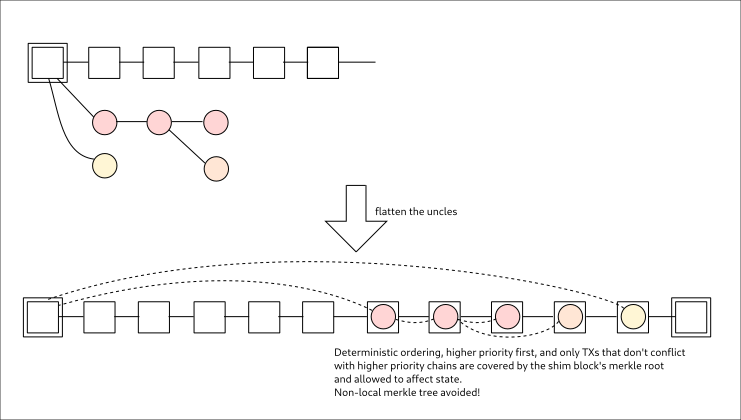
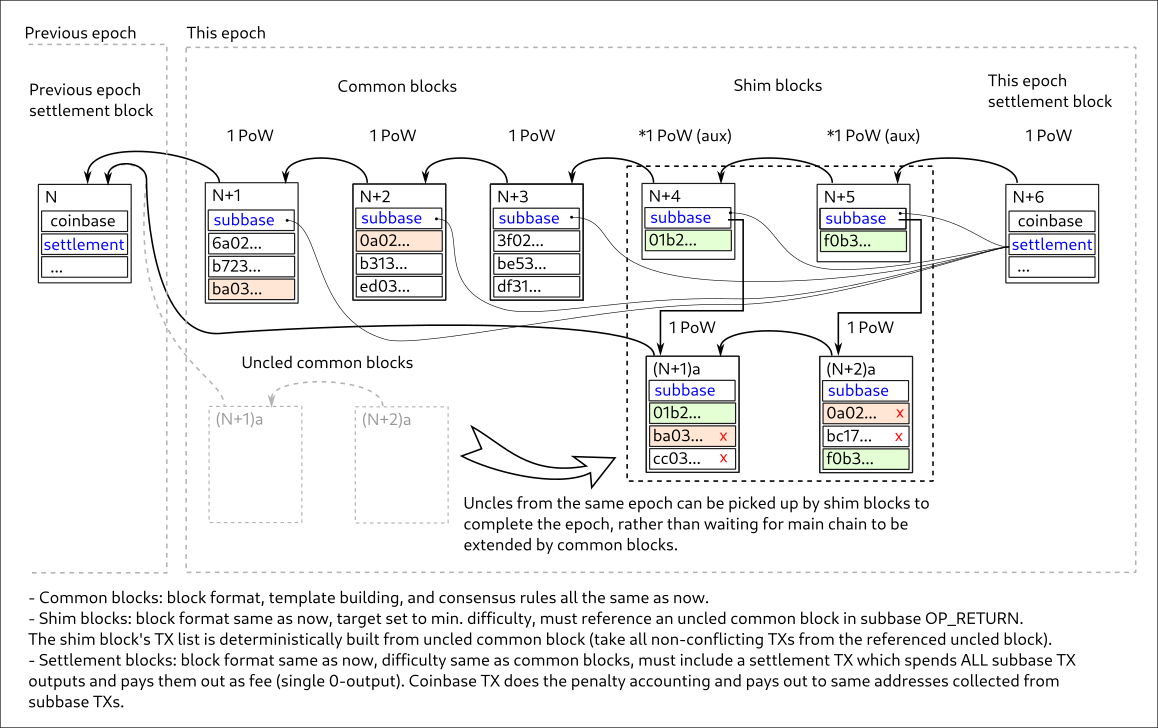
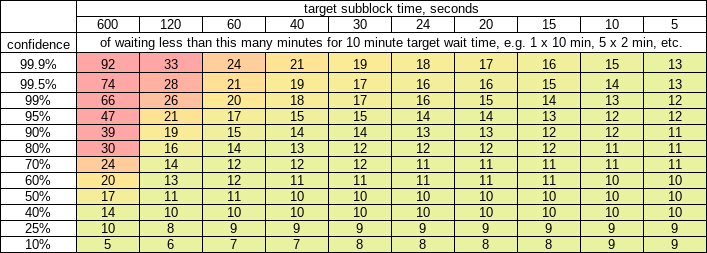
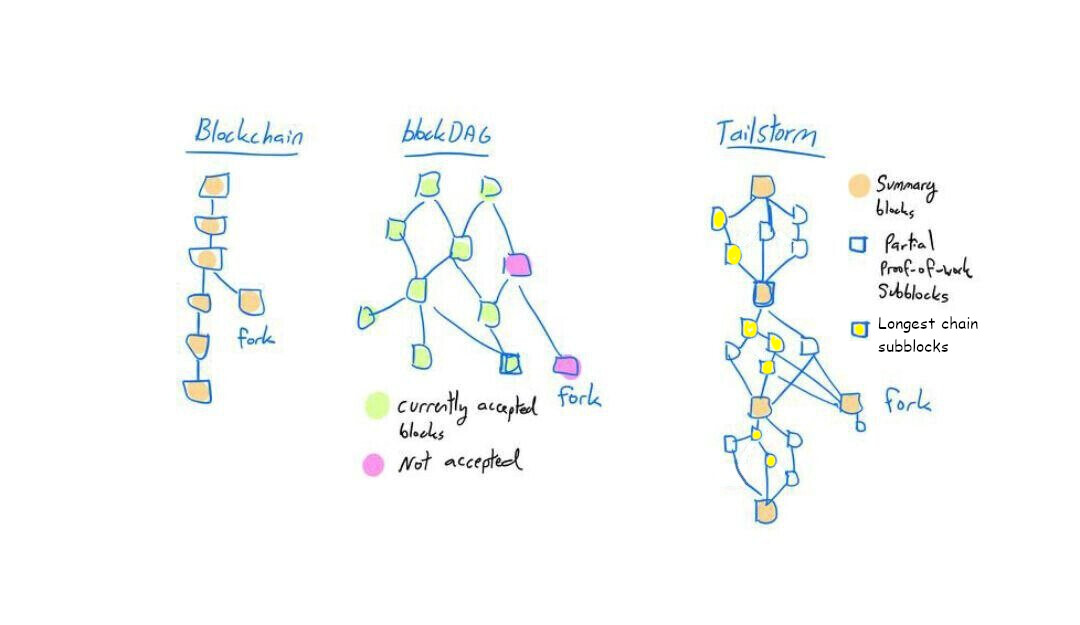
Not required, but they can and this is favored - because there’s benefit in choosing to extend the longest subchain rather than referencing the previous FB.
The penalty system incentivizes mining on top of best known subtip in order to avoid the penalty. It also incentivizes against subblock witholding because then nobody will see your blocks and they’ll extend the other branch while you mine in secret, and if the public branch wins - you get hit by the penalty if your branch will be shorter.
Why, if the mempool policy stays the same, how would you even obtain a conflicting TX? If anything, it’s likely that subs will include duplicates, like the scenario im_uname laid out:
a quick top-of-my-head example:
block A1-A2 is the longest subchain.
block B1 competes with A1 and has a transaction T1 that doesn’t conflict with A1, yet doesn’t exist in A1-A2 either. it’s a branch, uncle, whatever.
I now want to mine A3. Can I mine T2 that spends from outputs of T1, if block B1 “contributes” transactions? I assume I’ll need to include T1 first so my block is internally consistent. If I include T1, did block B1 actually “contribute” anything?
To which I answered:
I see, good Q, yeah you’d have to include T1, or you’d have to extend the subchain that already has it
Yup. Not rejecting is the secret sauce of Tailstorm, it integrates blocks that would otherwise be orphaned: takes in their PoW contribution + any non-conflicting TXs, and there’s PoW-based dispute resolution for conflicts.
Re. time, they can lie, sure, but it has no effect here. Accumulated PoW settles the dispute just like now, not the reported time. In case of equal PoW (same competing subchain length) it’s a coin toss based on subhashA < subhashB.
No, because if you observe your TX is included in a fast-advancing subchain, you can have some confidence that it won’t be replaced by another subchain - just like now you can have confidence that a 2conf won’t be reorged by another tip.
Miners are incentivized to announce their subblocks ASAP, so let’s say K=60, and there are subtips:
-
- 30 blocks
-
- 15 blocks
-
- 14 blocks
the network needs just 1 more SB in order to announce a FB, and then everyone’s expected to start mining on top of it, else they risk their extra SB getting reorged.
If you have a TX in 1., then you can be pretty sure it will win over whichever tip produces the last SB.
If you have a TX in 2. or 3., there’s uncertainty, if 3. mines the last SB and it has a conflict then it’s a coin-toss. If 2. mines the last SB then it wins over any TX in 3. but NOT against 1.
If 2 SBs arrive simultaneously, the FB picks one of them, and shortly after some SBs in the next epoch start appearing so the network can have confidence which FB won.
You can’t mine a FB unless there’s a pick of SBs available that would accumulate (1-K) PoW.
At that moment, mining a SB would imply overproducing PoW and you risk the SB getting reorged by some other miner mining a FB and not picking your SB. There’s incentive to go for a FB as soon as enough SBs have been announced.
You could still go for an empty SB or FB, why not? Not sure it breaks header-first, I’m not ready to claim either yes/no at this moment.
You’d see higher number of branching / 10min, but not orphans / 10min. That’s the secret sauce. The would-be-orphans get merged, their miners get paid (and only get hit by 1/K penalty), so latency has less impact on their profit, so big pools get less of an advantage over small pools.
If small pools are trying to stay on main branch in order to avoid penalty, sometimes they’d manage, sometimes they wouldn’t, and then you’d have something like this:
-- F -- o -- o -- o --o -- o -- o -- o -- o -- o -- o -- o -- F -- o -- o --
\ o \ o \ o \ x
When they’re not late - they just extend the best tip. When they’re late, they branch off the best tip, but their subs later get picked up by the FB. Only if they’re late to the last sub would their sub get orphaned.
Their loss here would be (3 * 1/K) + 1/K = K.
Compare that to just reducing block time, you’d have this:
-- o -- o -- o -- o --o -- o -- o -- o -- o -- o -- o -- o -- o -- o -- o --
\ x \ x \ x \ x
Their loss here would be 4K.