I’ll try, the above was a clumsy way to say: right now a reorged block results in total loss of reward for the miner who found it, whereas with Tailstorm his block could be integrated alongside the longest subchain and he can still get paid for finding a winning nonce.
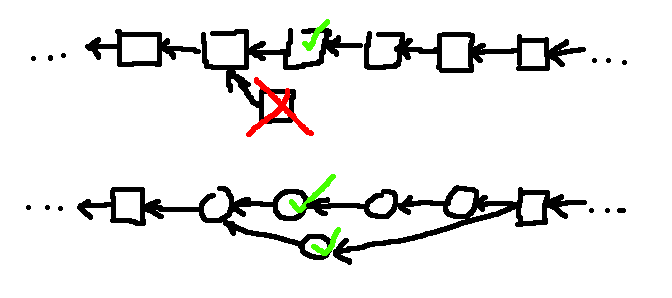
What if they mined their own block seconds before being notified of another block at the same height found by another miner? They have to make a choice: build on top of their own, or switch to building on top of the other one. All other miners have to pick a side, too. They use the 1st seen, right? But that’s subjective, not everyone has to see it the same.
Thanks for this, I want to avoid any misunderstandings, so we can best evaluate this. First we must correctly understand all the implications, costs/risks/benefits, then we can proceed to making judgements whether it would be worth it, and everyone would have to be convinced. For that to happen, everyone must first understand it.
It’s just my enthusiasm, because it looks so promising I can’t help myself from being excited by the possibility of improving BCH.
My node has logged some alternative tips (current best 856932): 848151, 839006, 834892, 833934, 832208, 826704. From that, current orphan rate is about 0.02%, which is nice. But our blocks are small right now. Wouldn’t orphan rates grow with block size?
That’s the whole argument against simple reducing block time, right? With 200 MB blocks maybe we’d hit 1%, but if we’d reduce block time then at same TPS (but say, with 50MB x 4 for 2.5-min blocks) we could be looking at what 2, 3, 10%?
Hold on, I think there could be some misunderstanding here. Isn’t that the same as now? You need to have the parent block’s TXs if you want to be sure you’re extending a valid block. Same here, you need to validate the parent (sub)block if you want to build on top of it, as if we just have simple block time reduction. But, while you validate the latest subblock, you can just mine on top of the previous one in parallel, and if you find a block, it can still be integrated and you get the reward for contributing PoW.
Maybe you mean the scenario where there are 2 competing subblocks with almost the same set of TXs in each. After all, if everyone’s mining off public mempool, their block header is expected to commit to almost same set of TXs, right? So they both announce their blocks, and how do nodes currently deal with storing the orphaned block, isn’t there some deduplication method? All you have to do is store a list of TXs, right? The orphaned blocks are not part of permanent blockchain records, they’re just local to nodes that happened to see them. Tailstorm would integrate them into permanent blockchain records.
So, when time comes to merge these 2 blocks (enough accumulated PoW for a summary block), how do we deduplicate? That’s why I said +2byte/TX, but it would depend on chosen subdivision because a single TX can appear in any number of subblocks (worst case fully parallel, where some TXs are replicated K times). With +2 bytes and using a bitfield you could subdivide up to K=15 (you need the last bit for rejected conflicting TXs).
Why would it mean that? If subblock tip has been updated he can’t include the TXs already included in the parent subblock, but if he mined a parallel block then he could include the same TXs and even a conflicting TX, and the individual TX conflicts would be resolved based on subchain length, when they later get merged in the summary block.
They can, imagine the small miner being the side-block in the above sketch. Even if his block was a subset of TXs found in the parallel block, his block would get merged and he’d get his fair share of rewards.
I’m not sure how fees are split in the summary when distributing rewards, another good Q emerged here.
Why? Can’t the extended block data be added and passed around in a non-breaking way? Non-upgraded software would just see plain old blocks every 10 minutes.


 But yeah, caution is warranted.
But yeah, caution is warranted.