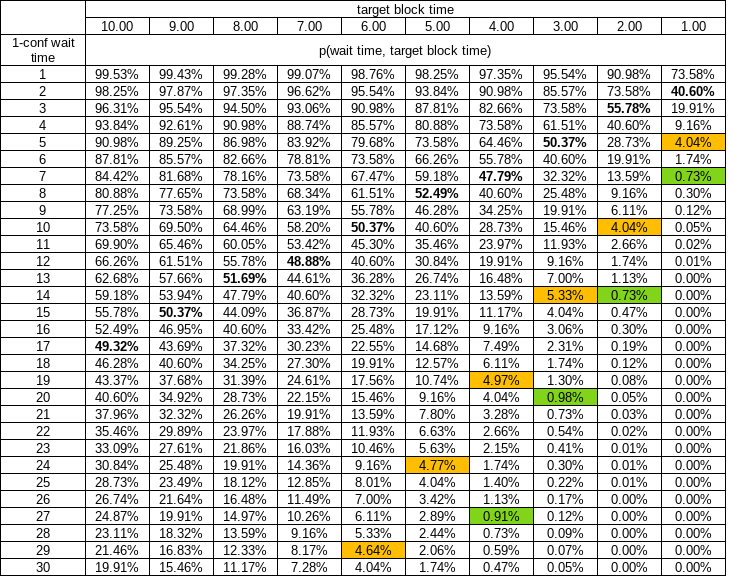
With a random process like PoW mining is, there’s a 14% chance you’ll have to wait more than 2 times the target (Poisson distribution) in order to get that 1-conf.
This is not really correct. It’s much worse than that: 40.6%. Russell O’Connor discusses this here.
The 14% is the probability that the time difference between two blocks is longer than 20 minutes. (The time between blocks has an exponential distribution with rate parameter 1/10 minutes).
That is not the probability that a user waits longer than 20 minutes for their first confirmation. A user is not equally likely to broadcast a transaction during a long block time and a short block time. They are much more likely to broadcast during a long block time because long block times cover longer periods. (We assume that transactions are confirmed in the next mined block and that the timing of a broadcast transaction and the timing of a block being mined are independent.)
The probability distribution of a user’s wait time to first confirmation is an Erlang distribution with shape parameter 2 and rate parameter 1/10 minutes. This is the same as a gamma distribution with shape parameter 2 and rate parameter 1/10 minutes.
This statement is also not correct: “With 2-minute blocks, however, there’d be only a 0.2% chance of having to wait more than 12 minutes for 1-conf!” The correct probability is about 1.7%. You can get this probability by inputting this statement in R: pgamma(12, shape = 2, rate = 1/2, lower.tail = FALSE).
IMHO, O’Connor’s explanation isn’t very detailed, but you can convince yourself that the user’s wait time is an Erlang(2, 1/10) distribution with a simulation. In R it would be:
set.seed(314)
exp_draws <- rexp(1e+07, rate = 1/10)
# Draw ten million block inter-arrival times
user_wait_index <- sample(length(exp_draws), size = 1e+06, replace = TRUE, prob = exp_draws)
# Draw one million indexes from the exp_draws vector. prob = exp_draws means
# that the probability of selecting each index is proportional to the inter-arrival time.
user_waits <- exp_draws[user_wait_index]
# Create the user_waits vector by selecting the appropriate exp_draws elements
prop.table(table(user_waits >= 20))
# The proportion of user_waits that are longer than 20 minutes:
# FALSE TRUE
# 0.593514 0.406486
ks.test(user_waits, pgamma, shape = 2, rate = 1/10)
# Kolmogorov-Smirnov test fails to reject the null hypothesis that the
# user_waits empirical distribution is the same as a gamma(2, 1/10) (i.e. Erlang(2, 1/10))
# Asymptotic one-sample Kolmogorov-Smirnov test
# data: user_waits
# D = 0.00074215, p-value = 0.6404
# alternative hypothesis: two-sided
# Make a histogram of user_waits and compare it to the
# probability density function of gamma(2, 1/10)
hist(user_waits, breaks = 200, probability = TRUE)
lines(seq(0, max(user_waits), by = 0.01),
dgamma(seq(0, max(user_waits), by = 0.01), shape = 2, rate = 1/10),
col = "red")
legend("topright", legend = c("Histogram", "PDF of gamma(2, 1/10)"),
lty = 1, col = c("black", "red"))
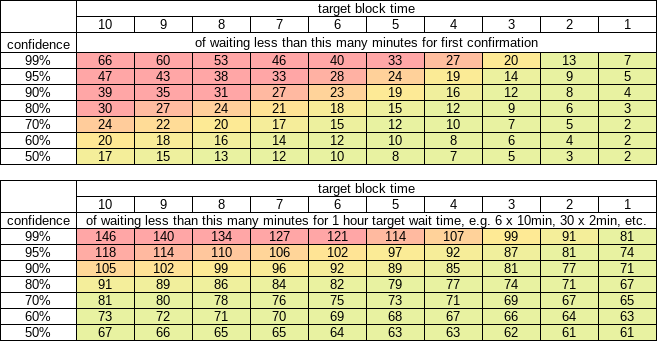
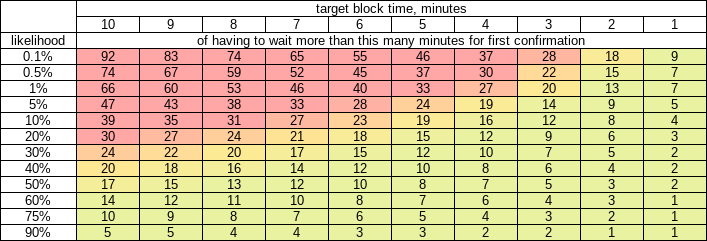
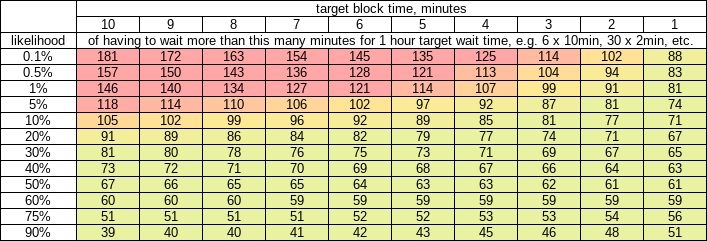
I’m not 100% sure about this, but I think your table also is incorrect. Let x be the number of confirmations and y be the average block time. We use the Erlang distribution again because the shape parameter is the number of events that we are waiting to occur. We add 1 to the shape parameter to factor in the probability that the user broadcasted their transaction during an “unluckily” long block time interval (similar reasoning as before). The distribution of the waiting time would be Erlang(x + 1, 1/y).
When the user is “expecting” a certain number of confirmations in 60 minutes, it would be 6 with the current 10 minute block time and 30 with a 2 minute block time. The distribution of waiting times for a user waiting for 6 blocks with a 10 minute average block time would be Erlang(6 + 1, 1/10). For 30 blocks with a 2 minute block time it would be Erlang(30 + 1, 1/2).
If my conjecture is correct, to fill in the table you would input pgamma(c(70, 80, 90, 100), shape = 6 + 1, rate = 1/10, lower.tail = FALSE) in R for the first column and pgamma(c(70, 80, 90, 100), shape = 30 + 1, rate = 1/2, lower.tail = FALSE). That would give you:
| expected to wait |
actually having to wait more than |
probability with 10-minute blocks |
probability with 2-minute blocks |
| 60 |
70 |
45.0% |
22.7% |
| 60 |
80 |
31.3% |
6.2% |
| 60 |
90 |
20.7% |
1.2% |
| 60 |
100 |
13.0% |
0.16% |

 can be done! no doubt about it, but the UX is different with BCH … the UX you described CANNOT work during an in-person POS, as the wait is indeterminate – whereas the payment options offered by Bitrefill (aside from BTC which is probably just there for decoration) can ALL be fulfilled in less than 2mins (on average)
can be done! no doubt about it, but the UX is different with BCH … the UX you described CANNOT work during an in-person POS, as the wait is indeterminate – whereas the payment options offered by Bitrefill (aside from BTC which is probably just there for decoration) can ALL be fulfilled in less than 2mins (on average)
 )
)