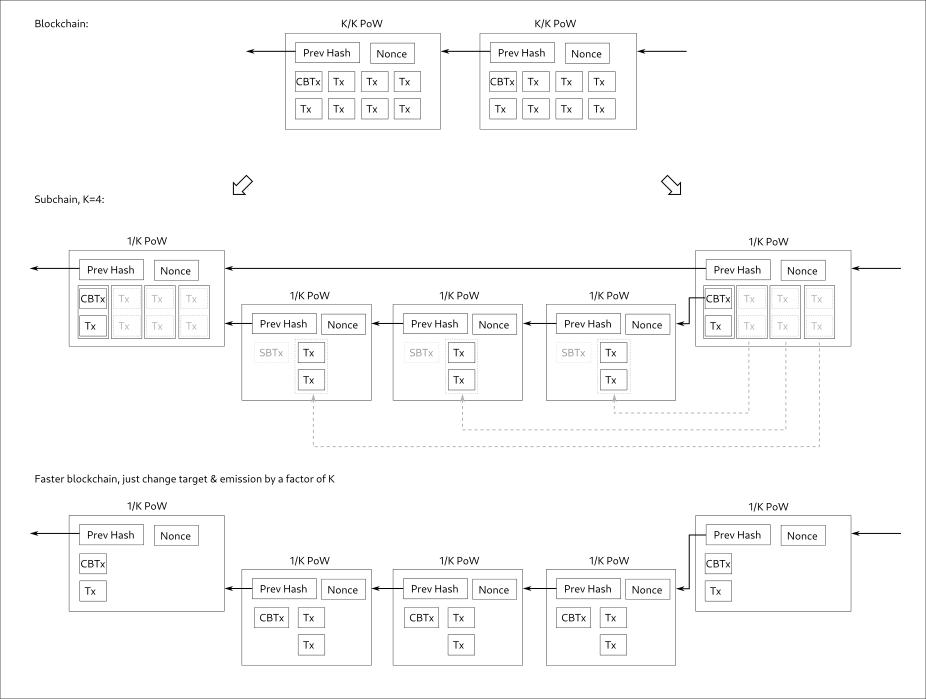
That’d be the only immediate advantage. However, nodes could extend their API with subchain confirmations, so users who’d opt-in to read it could get more granularity. It’d be like opt-in faster blocks from userspace PoV.
This looking like a SF is just a natural consequence of it being non-breaking to non-node software. It would still be a hard fork because:
- We’d HF the difficulty jump from K to 1/K. To do this as a SF would require intentionally slowing down mining for the transition so difficulty would adjust “by itself”, and it would be a very ugly thing to do. So, still a HF.
- Maybe we’d change the TXID list order for settlement block merkle root, not sure of the trade-offs here, definitely a point to grind out, the options I see:
- Keep full TXID list in CTOR order when merging subblock TXID lists. Slows down blocktemplate generation by the time it takes to insert the last subblock’s TXIDs.
- Keep them in subblock order and just merge the individual subblock lists (K x CTOR sorted lists), so you can reuse bigger parts of subblock trees when merging their lists.
- Just merge them into an unbalanced tree (compute new merkle root over subblock merkle roots, rather than individual TXs).
Just to make something clear, the above subchain idea is NOT Tailstorm. What really makes Tailstorm Tailstorm is allowing every Kth (sub)block to reference multiple parents + the consensus rules for the incentive & conflict-resolution scheme.
With the above subchain idea, it’s the same “longest chain wins, losers lose everything” race as now, it is still fully serial mining, orphans simply get discarded, no merging, no multiple subchains or parallel blocks.
Nice thing is that the above subchain idea is forward-compatible, and it could be later extended to become Tailstorm.
Sorry but all that looks like it would break way more things and for less benefits, but I’m not sure I understand your ideas right, let’s confirm.
First, a note on pool mining, just so we’re on the same page: When pools distribute the work, a lot of work will be based off same block template (it will get updated as new TXs come in, but work distributed between updates will commit to same TXs). Miners send back lower target wins as proof they’re not slacking off and they’re really grinding to find the real win, but such work can’t be accumulated to win a block, because someone must hit the real, full difficulty, win. Eventually 1 miner will get lucky and win it, and his reward will be redistributed to others. He could try cheat by skipping the pool and announcing his win by himself, but he can’t hide such practice for long, because the lesser PoWs serve the purpose of proving his hashrate, and if he doesn’t win blocks as expected based on his proven hash the pool would notice that he suspiciously has a lower win rate than expected.
Now, if I understand right, you’re proposing to have PoW be accumulated from these lesser target wins - but for that to work they’d all have to be based off same block template, else how would you later determine exactly which set of TXs the so accumulated PoW is confirming?
I think it would work to reduce variance only if all miners joined the same pool so they all work on the same block template so the work never resets, because each reset increases variance. Adding 1 TX resets the progress of lesser PoWs. Like, if you want less variance you’d have to spend maybe first 30 seconds to collect TXs, then lock it and mine for 10min while ignoring any new TXs.
Also, you’d lose the advantage of having subblock confirmations.
And the cost of implementing it would be a breaking change: from legacy SPV PoV, the difficulty target would have to be 1 because of:
SPV clients would have to be upgraded in order to see the extra stuff (sub nonces) and verify PoW, and that would add to their overheads, although the same trick I proposed above could be used to lighten those overheads: you just keep the last 100 blocks worth of this extra data, and keep the rest of header chain light.