I had a hypothesis that difficulty could be used to estimate the price of BCH in MWh, which I spent some time researching, and here I will share my findings.
First, recall that:
- Block headers encode a 4-byte
compressed_targetwhich is a custom scientific notation:{3 byte mantissa}{1 byte exponent}where we obtain the int256targetby doing:mantissa * 2^((exponent - 3) * 8); - To be accepted by the network, block header hash must satisfy
block_hash <= target; - Chainwork contribution is the expected number of hashes given by
2^256 / (target + 1), and cumulative chainwork is used to resolve which is the “longest” chain; -
max_targetis that of genesis block, which hadcompressed_target = 0xffff001dand is the easiest PoW; - Difficulty is defined as
target / max_target; - Difficulty of 1 is then equivalent to chainwork of 4295032833, which is equal to 4.29 gigahashes.
We can think of hashes as a commodity extracted by the miners and then sold to blockchain network(s) in exchange for block reward.
We postulate that each block is a price point, where the full block reward (subsidy + fees) is exchanged for the hashes. The network is the buyer, and miners are the sellers.
If miners are over-producing, the DAA auto-corrects the purchase price by slowing down the blocks, and if they’re under-producing, the DAA auto-corrects the purchase price by speeding up the blocks. The DAA functions as an automatic market maker (AMM).
If that is so, we can define BCHGH price as (difficulty / (subsidy + fees)). Each block header & coinbase TX is then a native price oracle for BCHGH. We don’t need any external data in order to know this price, the blockchain itself records it.
But can we somehow link hashes to something in the real world? It is impossible to produce a hash without spending energy, so if we know the average amount of energy used to produce a hash then we could have some estimate. But the amount of energy changes with each new generation of ASICs.
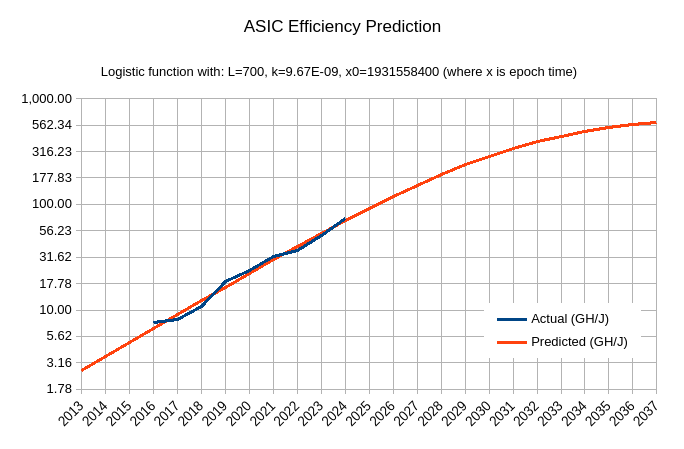
Thankfully, it looks like we can model the efficiency gains using the Logistic function. I fit one such curve on the data (source, fetched on 2024-11-08) and got:
-
asic_efficiency = 700 / (1 + e^(-9.67E-09 * (x - 1931558400))(unit: GH/J)
where:
- x is epoch time
- numerator 700 sets the asymptote, roughly corresponding to 0.5nm tech (further 10x improvement from current 5nm tech)
- factor of 9.67E-09 found such that the curve angle on log scale matches the angle of data points
- offset 1931558400 to fit the data points
With this, we can infer BCHMWH price using (difficulty / asic_efficiency) / (subsidy + fees).
Then, to better see whether this would map to external prices I pulled FRED global energy price index ($100/MWh in 2016) and then obtained inferred BCHUSD.
Let’s see how so inferred price matches real prices (coinmarketcap), for both BTC and BCH.
| BCHUSD | BTCUSD |
|---|---|
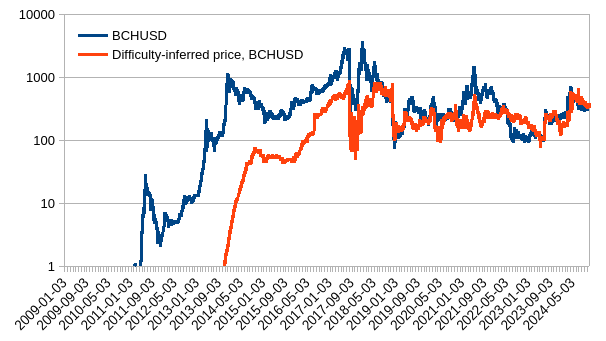 |
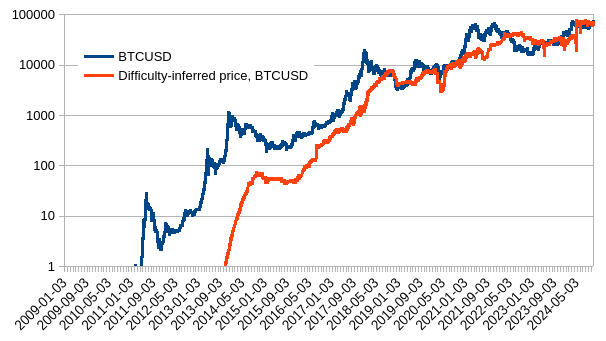 |
Not perfect, not bad. Before 2015, the mining market and ASIC development was still immature but value of block reward was enough to crowdfund rapid catching up with state of the art chip-making. Since it caught up, we can observe better correlation between inferred and actual.
Use of difficulty price oracle for minimum relay fee algorithm
What I really wanted to see is whether we could use difficulty to automatically set the minimum relay when new price highs are reached, in order to minimize the lag between price making highs and people coordinating a reduction of min. fee.
To not have to depend on external data, the idea to set the min. fee in watt-hours rather than sats or USD, and just use the ATH of BCHMWH to set the min. fee in sats.
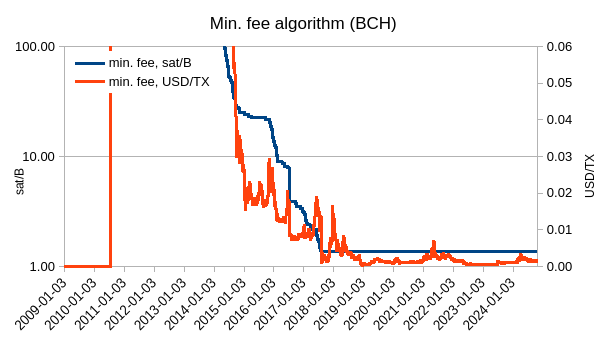
Here’s how that would look like for 0.1 Wh/byte
| BCH | BCH |
|---|---|
 |
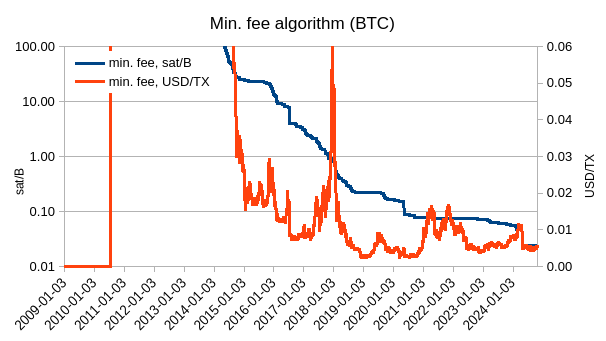 |
As we can see, setting it so would keep the min. fee under $0.01. BCH would have it lower because current price is about 10% of last ATH, while BTC is near its ATH.
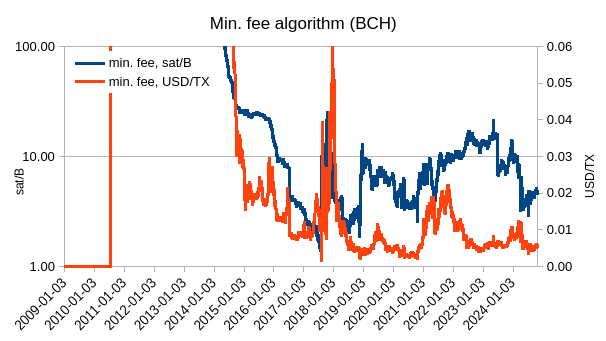
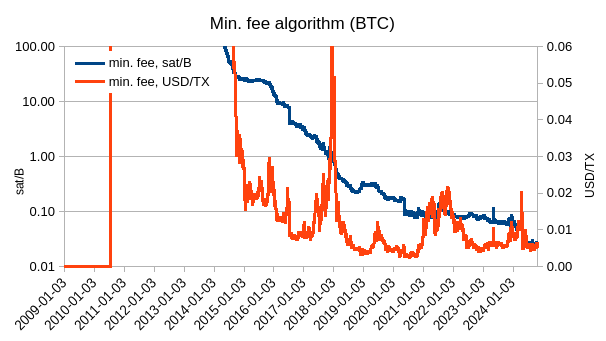
If we would not use ATH price but current price, then the min. fee would not only be going down with new ATHs but it would be freely floating and would look like this:
| BCH | BCH |
|---|---|
 |
 |