Edit:
All the below was just my process of rediscovering hash table lookups with Claude’s help, starting from BIP-37 and BIP-157, thinking of whether it’s possible to combine them.
Ha! So we basically arrived at “hash table lookup” via the scenic route through Bloom filters and set intersection theory.
The result of that research is this little section that I added to faster blocks CHIP:
Hash-Keyed Pub/Sub (Hypothetical)
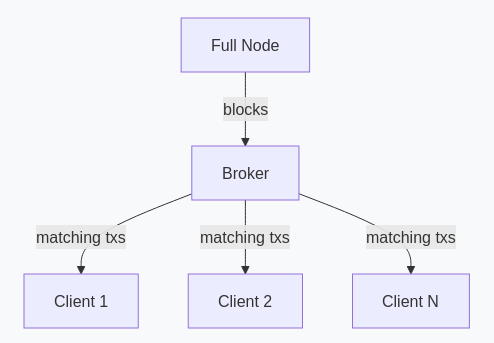
An alternative architecture addresses BIP-37’s scaling limitation: clients send 64-bit hashes of their addresses once, and the server maintains a reverse index for O(nb) routing per block, independent of client count.
Optionally, the server can publish per-block hash lists, allowing clients to verify routing completeness or operate in Neutrino-style pull mode.
With 1-minute blocks:
- Per-block work: 10x more blocks with 1/10th the transactions each; net work equivalent.
- Index size: unchanged (depends on subscribed addresses, not block structure).
- Client bandwidth: unchanged (receives same transactions regardless of block time).
- Merkle proofs: ~33% shorter due to shallower trees.
- Header chain: clients must sync 10x more headers (~42 MB/year); mitigation with header merkle proofs possible.
This architecture is not implemented in any production Bitcoin Cash wallet but demonstrates that faster blocks pose no obstacle to future light client designs.
It was discovered during research into BIP-37 and BIP-157/158 for this CHIP; see discussion on Bitcoin Cash Research.
This is the same pattern used by email servers, message queues, and search engines: build an index, route by lookup.
It is perhaps surprising that light wallet architectures have not adopted this approach, given that hash-indexed routing predates Bitcoin by decades.
/edit
I was curious about whether it’s possible to AND two Bloom filters (one computed on block elements, one computed on wallet elements) as a way to eliminate a block as NOT having any transactions of interest. But to have a good elimination rate we need huge filters. But we don’t need huge filters for element extraction. What if we can combine the best of both worlds?
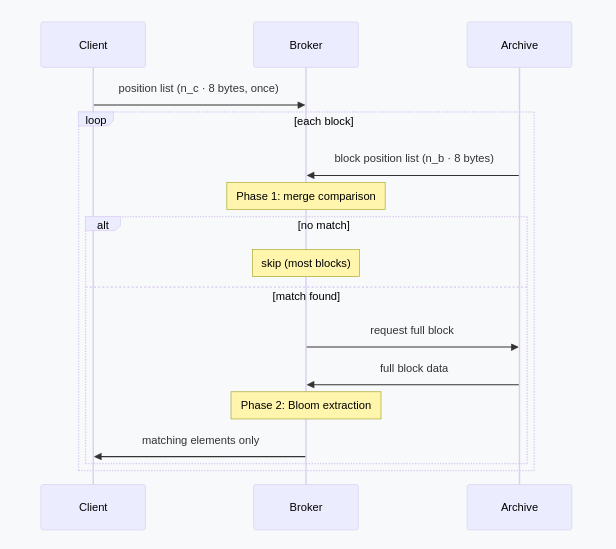
Position-List Pre-filtering for Bloom Filter Protocols
Abstract
We observe that BIP-37 style Bloom filters with arbitrarily large bit arrays can be represented as sorted position lists, where storage depends only on element count. This enables a two-phase filtering protocol: fast elimination via sorted merge comparison, followed by BIP-37 extraction on surviving blocks. The construction adds a near-free elimination layer using only integer comparisons.
1. Position Lists
A Bloom filter sets k bits per element in a bit array of size m. When m is large and elements are few, most bits are zero—storing the bit positions is more compact than storing the array.
For a set S of n elements with k hash functions hi: element → [0, 264), define the position list:
P(S) = sort( ⋃x ∈ S {h1(x), …, hk(x)} )
Storage is k · n · 8 bytes regardless of hash space size. Making m = 264 costs nothing extra while reducing collision probability to negligible levels.
2. Two-Phase Filtering
Setup: Server maintains a position list per block. Client sends a position list for their watch set.
Phase 1 — Elimination:
Compare sorted lists via merge. If no position matches, the block contains nothing relevant.
def has_overlap(block_pos, client_pos):
i, j = 0, 0
while i < len(block_pos) and j < len(client_pos):
if block_pos[i] == client_pos[j]:
return True
elif block_pos[i] < client_pos[j]:
i += 1
else:
j += 1
return False
Cost: O(nb + nc) integer comparisons. False positive rate is the probability that any of k · nb block positions lands in the set of k · nc client positions:
Pfp = 1 − (1 − k · nc / 264)k · nb ≈ (k · nc)(k · nb) / 264
For k = 3, nb = 160,000, nc = 1,000:
Pfp ≈ (3,000 × 480,000) / 264 ≈ 7.8 × 10−11
Most blocks are eliminated here. Only blocks with a matching position proceed to Phase 2.
Phase 2 — Extraction (on match):
This is standard BIP-37: fold client positions into a Bloom filter sized for practical transmission, then test block elements:
def extract_matches(block_elements, client_pos, bloom_size):
# Fold 64-bit positions into smaller filter
bloom = bytearray(bloom_size // 8)
for pos in client_pos:
bit = pos % bloom_size
bloom[bit // 8] |= 1 << (bit % 8)
# BIP-37 style: server tests each element
return [e for e in block_elements if test_bloom(bloom, e)]
The same client position list serves both phases—Phase 1 uses the raw 64-bit positions, Phase 2 folds them to a practical size.
3. Relationship to BIP-37
BIP-37 has the server test every transaction against a client-provided Bloom filter. This works but requires O(k · nb) hash operations per block unconditionally.
| Aspect | BIP-37 | This construction |
|---|---|---|
| Elimination | None | Position list merge |
| Extraction | Bloom filter | Same (folded positions) |
| Server cost per block | O(k · nb) hashes | O(nb + nc) comparisons |
| Server cost on match | — | O(k · nb) hashes |
| False positive source | Bloom filter size | Two stages: near-zero elimination, standard Bloom extraction |
The contribution is Phase 1 elimination, which makes BIP-37’s expensive test rare rather than universal. On a chain where clients match perhaps 1 in 10,000 blocks, almost all work becomes simple integer comparison.
4. Properties
| Property | Value |
|---|---|
| Server storage per block | k · nb · 8 bytes |
| Client subscription size | k · nc · 8 bytes |
| Elimination cost | O(nb + nc) comparisons |
| Extraction cost | O(k · nb) hash operations |
| False positive (elimination) | ≈ 10−10 for typical parameters |
| False positive (extraction) | Standard Bloom rate for folded size |
5. Conclusion
Position lists in a large hash space provide cheap elimination with near-perfect accuracy. When elimination fails, the same positions fold to a standard BIP-37 Bloom filter for element extraction. The construction requires no novel primitives—only sorted lists, merge comparison, and modular arithmetic. It can be viewed as adding an efficient pre-filter to the existing BIP-37 protocol.