So basically we can sort blocks by their number of zeroes and then put the ones with “enough” difficulty into the “strong block” bag, and anything lower we drop into the “sub block” bag.
[ Again, assuming such a scheme is even possible. ]
I will read tailstorm whitepaper today and think about it more.
Hey everybody. I’m one of the authors of the Tailstorm paper linked above. I’ll try to answer your questions in case you have any!
I largely agree with @Griffith 's summary of how the different proposal came to be. It’s accurate coming from the perspective of Storm and Bobtail and how these ideas ended up in Tailstorm. A core insight for this discussion here should be that multiple attempts to add weak blocks without adapting the consensus rules have failed before.
I want to add that Tailstorm merges not only Storm and Bobtail, but also (my) Parallel Proof-of-Work. Storm/Bobtail provide the weak block idea. Tailstorm itself adds a nifty reward scheme to punish block withholding. Parallel Proof-of-Work provides a compatible consensus algorithm.
If you decide here, that the improved properties are worth changing the consensus, then you should also check out my most recent proposal. While Tailstorm structures the weak blocks as trees (inherited from Bobtail), my new protocol puts them into a DAG. This change comes without modifying the consensus rules for the strong blocks. In Tailstorm, branches in the weak block tree can only be merged with the next strong block. The new protocol’s DAG structure allows merging branches back into a linear chain asap. I also propose a DAG-based reward scheme for punishing withholding which turns out to perform better than Tailstorm’s. There is no fancy name yet, so I refer to this as parallel proof-of-work with DAG-style voting.
I actually I do have a question. I am deep-reading(some sections I read up to 8 times) TailStorm Whitepaper right now. I have stumbled upon something that is hard to me to understand.
There is an equation (allegedly by Peter Rizun) that defines block propagation delays and orphan rates:
I must be misunderstanding something, because greater bandwidth generally speeds up block propagation, not multiplies it, doesn’t it? The bigger the bandwidth, the faster a block can propagate. So it would seem that the equation should be
Glad you asked because I was going to do the same thing. My initial thought skimming the reference papers was that z means propagation impedance (as it is defined as in the above referenced paper by Peter Rizun) which made me think the units were backwards and should be [seconds / byte] (in order to get the bytes to cancel out) and also fits with the definition. However, when I look to Peter’s paper that is referenced in the above paper ( 1txn.pdf (bitcoinunlimited.info)) z is defined as “maximum theoretical network bandwidth” (seemingly alternatively called propagation impedance as well!) – and the formulas below it support that the units are bytes / second.
BUT THEN! There is another twist! THAT paper references this paper ( feemarket.pdf (bitmex.com)) that shows propagation impedance as seconds / [M]byte as well!
So I think there was a mistranslation somewhere. I think the formulas are correct but z actually represents seconds / byte rather than bytes / second.
It seems to me that Peter at some point changed what z meant for one paper and changed his formulas, but then returned to the original definition linked in the feemarket.pdf paper.
I believe I may have found 2 vulnerabilities in your protocol that were not taken into account when performing threrat analyses:
Cloned summary problems:
It looks to me that Byzantine Generals problem for summary blocks is not completely solved by the TailStorm protocol. Assuming summaries can differ from each other even if containing the same list of subblocks (for example, they could differ by timestamps or some other unique identifier), there is a “summary spam” attack possible due to a race condition where an attacker supplies thousands of different summaries with the same basic sub-blocks in order to confuse nodes and cause some kind of chaos.
What kind of “chaos” would that be is difficult to say because I can only perform basic and simple simulations directly in my brain, unlike the authors of the Whitepaprer who used advanced algorithms and AI. But right now I can already imagine something like spamming millions of summary block candidates to all non-mining nodes and thus using their CPU power, delaying propagation of honest summary blocks by significant times or confusing other miners so that they mine on top of invalid block tip and lose their profits as their next summary blocks become invalid because they picked the wrong summary to build on. This potentially creates a scenario where full summary blocks with all included sub-blocks can be orphaned.
Bitcoin solves this, because each block needs to prolong the chain with added Proof Of Work, and miners throw dice in order to unilaterally decide which of duplicates is “real” (contains most PoW).
Possible quick and easy solutions:
A: Summary block should not just include a summary, but should include it’s own added PoW, so the network can choose the summary with most Proof Of Work, instantly solving Byzantine Generals problem and the race condition.
B: Each summary block with the same subsections should be identical, generated automatically/procedurally in a way that it is impossible for 2 different summary blocks with identical contents to co-exist in the network.
Unfortunately, in case of solution A, some Proof Of Work validating Summary block would be partially wasted, because summary blocks do not contain transactions themselves and therefore cannot earn additional block reward for processing transactions to be paid for the burned power.
So solution B would be probably more beneficial in this case, assuming it is possible.
[ The whitepaper does not address above attack scenario, I have thoroughly read all attack analysis scenarios. ]
Sub-block UXTO spending duplication:
In case 2 sub-blocks end up having the same PoW/hash and contain transactions spending the same UXTO twice, how is such conflict resolved?
The whitepaper talks about it in this manner:
What if hash(suba ) == hash(subb), which should theoretically be possible to happen, since the sub-blocks are mined completely in parallel?
EDIT:
This attack scenario is resolved, this is comparing hashes and not difficulties. I have no idea why I thought this is comparing difficulties, maybe I did not get enough sleep.
The third problem is the possible attack where either a dishonest miner or a dishonest node that has good connectivity to miners sends conflicting UXTOs to different miners.
The whitepaper addresses it in this manner:
Assuming above is true, it should be theoretically possible to spam conflicting transactions spending the same UXTO twice knowing they will be ignored. The attacker’s intention is increasing the size of the blockchain in order to increase the costs of maintenance of all related services (miners, block explorers, other nodes).
It would be only possible to spam in this manner assuming that the attacker can selectively connect to different miners and supply specific transaction to miner A and then conflicting transaction only to miner B, thus massively increasing the chance of the miners mining conflicting transactions.
According to the whitepaper, such transaction would have to be kept in the blockchain for eternity.
Bitcoin solves this by enforcing a strict block ordering at all times, parallel transaction insertion is impossible, which makes this scenario also impossible.
How does TailStorm deal with this attack?
[ The whitepaper does not address precisely this attack scenario ]
EDIT: Addendum to this attack scenario.
In the scenarios described in the Whitepaper, k=3 is used, meaning 3 subblocks make up 1 full summary block.
Assuming we want 10-second sub-blocksize and 10 minues strong blocksize (like in current Bitcoin), it is strictly theoretically possible to generate up to 60 parallel blocks by different miners. Of course such scenario is unrealistic because there never has been 60 miners in Bitcoin system with hashpower distributed so evenly.
So realistically, let’s assume a(still edge case of course) scenario of 15 sub-blocks being mined in parallel.
In this scenario, it would be theoretically possible for an adversarial player to generate 15 different versions of the same conflicting transaction: 1 valid and 14 invalid spending the same UXTO and send them to 15 different miners.
So this in effect would make spamming Bitcoin(Cash) network 15 times cheaper than it is now, as the transaction fee has to be only paid once, the other 14 invalid blocks do not require a fee for inclusion.
That is of course an edge case, but calculating this in more realistic manner adjusting for the current number of pools and their percentage of total hashpower, scenarios with 5-8 sub-blocks being created in parallel would/could be pretty common.
While waiting for a solution for the [possible] TailStorm vulnerabilities, I am going to investigate how precisely merged mining works, in order to evaluate whether it is more suitable for the Intermediate Block protocol.
What if now we get hash(blockA) == hash(blockB)? Bitcoin security relies on that being computationally impossible to achieve. 256-bit collision is a 2^128 problem and should not happen, not even once.
The assumption is always: if hashes are the same then the contents are the same. If that were not the case then the whole system would be broken.
I tend to accept this as the right answer. George contributed the section; I checked the formulas; then I did some editing on the text. I wrote “z represents bandwith (bytes per second)”. This does not make much sense as we’re adding seconds and bytes²/seconds.
Can you follow the math when reading “z represents seconds per byte” instead?
You are correctly identifying a DoS problem when Tailstorm and (Parallel Proof-of-Work in general) are implemented naively.
I’m aware of multiple solutions to this problem, and you’re on the right track with your solution attempts.
First. In my first version of parallel proof-of-work, the summary requires a signature of the miner you produced the smallest (as in lowest hash) vote (= weak block). With this setup, it’s easy to prevent summary cloning as you know exactly who did the cloning. Just burn the rewards if you see two conflicting summaries from the same miner ending the same epoch.
Second. The implementation of Tailstorm (@Griffith 's work) ensures that summaries follow deterministically from the referenced sub blocks. You cannot clone the summary because there is only one. This detail did not make it to the final submission paper.
Third. You accept that the underlying broadcast network requires some sort of DoS protection anyways and reuse it to mitigate the problem you describe. This is why I decided not to describe Tailstorms careful mitigation in the paper.
Fourth. You delay propagation of the summary until the next proof-of-work is solved. I.e. you reject propagating summaries which do not have any confirming weak blocks yet.
Fifth. When you choose the forth approach, you can as well merge the summary with the next weak block. In that scenario the strong block / summary has a list of transactions and a proof-of-work. This is what I do in the latest protocol version.
Would be great if @Griffith could confirm the below:
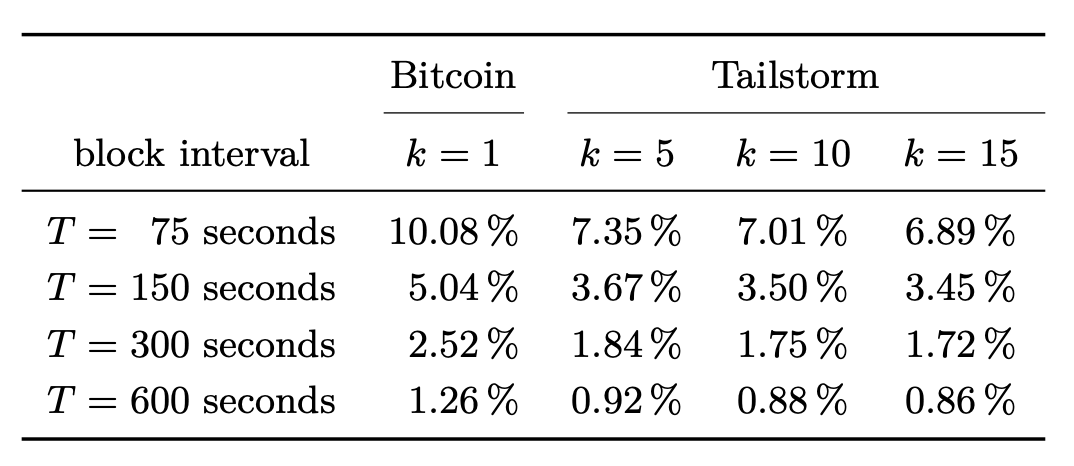
I did the calcs, and the numbers in the table don’t line up. They are all directionally correct, but do not come close to the stated results in the lower k values. See new summary table below (based on Formula 4):
Regarding your Invalid UXTO spending spam problem, I’m not sure I can follow.
First off, Tailstorm implementation uses k=3 but I think one should set a higher value. 10 second sub-block interval seems about right. The first Parallel PoW paper has an optimization suggesting that k=51 maximizes consistency after 10 minutes, assuming strong block interval 10 seconds, worst case propagation delay of 2 seconds and an attacker with 1/3 hash power. See Table 2 In the AFT '22 paper for other combinations of assumptions.
[ Your server is complaining I’m posting too many links ]
I’m loosing you where you say that 15 weak blocks will be mined in parallel. Tailstorm is linear when possible and parallel when needed. Miners share their weak blocks asap. Miners extend the longest known chain of weak blocks. Mining 2 blocks in parallel requires the second block not yet being propagated. It’s typical to assume worst-case propagation delays of a couple of seconds. Now, 15 blocks in parallel require that
all 15 are mined by different miners
no miner learns about the other 14 blocks before mining his own weak block
15 blocks in 2 seconds, where the target interval of a single block is about 10 seconds is very unlikely.
What I meant is a scenario, right after summary block has been confirmed, where no weak blocks were mined yet.
So in this scenario, weak blocks can be temporarily mined in parallel when there is no fresh weak block (all previous weak blocks already belong to a summary), can’t they?
I do admit that this scenario seems more rare after your explanation.