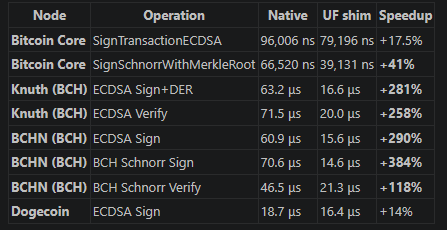
Hi everyone,
I would like to introduce UltrafastSecp256k1 , an open-source secp256k1 cryptographic execution engine I have been developing.
The project started as a performance-focused secp256k1 implementation, but over time it evolved into something broader: a multi-backend cryptographic engine with CPU, GPU, audit, and application-level pipelines built into one repository.
The main idea is simple:
secp256k1 should not only be correct and secure; it should also be fast enough to make privacy and wallet features practical for everyday users.
What the project provides
UltrafastSecp256k1 includes:
- CPU fast-path secp256k1 operations
- CPU constant-time paths for secret-bearing operations
- CUDA backend
- OpenCL backend
- Metal backend
- C ABI
- batch ECDSA / Schnorr verification
- ECDH
- BIP-340-related primitives
- BIP-352-style scanning pipelines
- FROST partial verification
- MuSig2/FROST-related infrastructure
- ZK/DLEQ/witness-oriented primitives
- benchmark tooling
- reproducible audit and assurance infrastructure
The goal is not merely to optimize one primitive in isolation. The goal is to provide a full execution layer that builders can use to assemble higher-level wallet, privacy, and indexing systems.
In short:
primitives are included, pipelines are ready, and verification is built in.
Why this matters for BCH
Bitcoin Cash has a strong focus on practical payments, low fees, and user-facing applications. Many privacy and wallet features become difficult not because the cryptography is impossible, but because the required scanning, indexing, or verification work becomes too expensive for normal devices.
This is especially true for privacy-oriented reusable payment schemes, stealth-address-like designs, and wallet-side scanning models.
If a wallet must scan many outputs or compute many elliptic-curve operations, the user experience can degrade quickly. On desktop this may be tolerable. On mobile, it can become painful.
My work focuses on reducing that friction.
Local-first, GPU-optional design
A key design principle is:
GPU acceleration should be an option, not a dependency.
The engine supports GPU acceleration where available, but I am also working on CPU-side scan optimizations so that normal devices can remain useful without relying on a remote accelerator.
The intended model is:
- CPU mode for maximum portability and local-first wallet behavior
- local GPU mode for desktops or laptops with OpenCL/CUDA/Metal support
- remote accelerator mode only when a user or service explicitly wants fast catch-up or high-volume indexing
- hybrid mode where recent blocks are scanned locally first, while large historical backlogs can be accelerated separately
This avoids turning privacy features into server dependencies.
CPU PreSer mode
One of the current optimization directions is what I call CPU PreSer .
The idea is to split a scan pipeline into two stages:
- an expensive stage that computes and serializes shared-secret material
- a cheaper online matching stage that uses the pre-serialized material
This allows wallets to cache, pipeline, or reuse work instead of treating every scan as a fully fresh computation.
For normal wallet usage, the user usually does not need to scan months or years of history every time the app opens. Most of the time, the wallet only needs to catch up a small number of recent blocks.
This means a practical architecture can be:
- local CPU scan for daily use
- local GPU acceleration if available
- optional accelerated catch-up only when the wallet has been offline for a long time
That model is much more compatible with user sovereignty than assuming every wallet needs a permanent remote scanning server.
Why I am posting here
I am interested in feedback from BCH developers on three questions:
- Which BCH wallet or application use cases would benefit most from a faster secp256k1 execution engine?
- Are there BCH-native privacy or reusable address designs where this kind of scan acceleration would be useful?
- What assumptions or risks should be considered before integrating such an engine into BCH wallets or infrastructure?
I am not asking anyone to trust the project blindly. The repository is open, the benchmarks are reproducible, and the audit pipeline is designed to be extended by others.
The most useful feedback would be adversarial:
- which assumption looks weak?
- which benchmark is missing?
- which integration mode is unrealistic?
- which BCH use case should be tested first?
My goal is to make this useful infrastructure, not just a performance claim.