
Where’s the best place for me to post a draft executive summary for review and feedback (assuming that would be helpful)?
1 Like
It definitely would! Anywhere you like, you could just open an issue in the CHIP’s repo: Issues · ac-0353f40e / Excessive Blocksize Adjustment Algorithm for Bitcoin Cash · GitLab
and we can work it out there, and later add it to the CHIP as a section!
1 Like
done
requesting feedback
1 Like
By the way, about 18 months ago I was cooking up a set of omnibus improvements that I wanted to pursue, chief among them, tackling the block size limit once and for all. That was around the time I learned of the work that @bitcoincashautist was doing. I didn’t really agree at the time with their approach, but didn’t think it would be productive to produce a counter approach; and then a bunch of life-stuff hit and I realized it would all have to be back-burnered.
Anyway, I had in mind to package and market this set of omnibus enhancements as “BCH: Bitcoin Untethered.” I figured that Tether was going to become an increasingly toxic asset, increasingly tied to BTC through the Blockstream/Bitfinex partnership, and thought it might be clever to play on this double-entendre of “untethering” meaning “unbinding us from the static block size limit” as well as implying “not beholden to Tether or Bitfinex.” I even paid out some BCH to crowdfund some images to go along with this (incomplete) marketing idea.
If this group’s champions want, I’ll offer up this stuff as part of a marketing campaign to rally consensus and also to attract attention from media. “Bitcoin Untethered” (for whatever its flaws) is surely a lot catchier than “Excessive Block-size Adjustment Algorithm (EBAA) Based on Weighted-target Exponential Moving Average (WTEMA)”

The runner-up image was also pretty good, I’ll see if I can find it.
1 Like

Thanks! First versions weren’t as good, anyone interested can observe many iterations under the dual-median thread, which spawned this CHIP:
The process of talking with everyone is what brought us here, there’s no way I could’ve come up with it in isolation, which is why I like to work out everything in public, because the feedback loop improves the design, and having all those discussions on Reddit was a lot of help!
I like it! Although I think it could be better to keep it in the drawer for UTXO commitments, which are the missing piece for syncing nodes to truly be “untethered” from the burden of having to download entire history.
I agree the title is not good, I inherited the excessiveblocksize name from the 2018 fork spec without giving it much thought, but I think it’d be better to rename it to simply:
“Blocksize Limit Adjustment Algorithm (BLAA) for Bitcoin Cash”, consistent with the more familiar name “blocksize limit” term, and naming scheme already used for Difficulty Adjustment Algorithm (DAA).
1 Like
I originally intended “Bitcoin Untethered” to refer to an omnibus program consisting of these items:
- Block size limit solution
- UTXO commitments
- Pruning enhancements
- SPV client enhancements
All centered around solving the scalability issues.
The idea was an omnibus package with a catchy name to focus attention on the core scalability issues.
So we can just say that this enhancement is just “Phase 1” of our larger commitment to scalability which we call “Bitcoin Untethered”
Or not 
(BTW, calling this “BLAA” is kinda asking for it, IMO. We gotta do better than that :))
1 Like
Having read this I think there’s been a misunderstanding of this post here: CHIP-2023-01 Excessive Block-size Adjustment Algorithm (EBAA) Based on Weighted-target Exponential Moving Average (WTEMA) for Bitcoin Cash - #23 by bitcoincashautist which argues that we don’t need additional min. and max. guards since algorithm as proposed already has the flat 32 MB as min., and a max. inherent to it and controlled by the choice of constants.
This CHIP expands on BIP101 by creating “min” and “max” guardrails that the block size limit cannot drop below or exceed. The “min” limit is intended to reflect worst-case expectations about the future capacity of the network, while the “max” is intended to reflect the expected future capacity of the network.
In that recent discussion on Reddit we considered the idea of absolutely scheduled min. / max. bounds, yes, but I’m not convinced they should be implemented. Jonathan was only proposing the min., and he understood that max. is not needed since the algorithm itself is bounded by an inherent max. (determined from the gamma constant) – it was me who accidentally introduced the idea by misinterpreting his idea of simply adjusting the algorithm’s parameter to something safer than I originally proposed. The algorithm to be proposed now will have a max. rate (2x/year) more generous than BIP101 (1.41x/year), however, unlike BIP101 it is conditioned on demand and it would be practically impossible to exceed the original BIP101 curve as it would require unprecedented network load spanning many years to have a chance of catching up with BIP101, and the time-to-catch-up will grow with time during any period of lower activity.
What about the min.? While Jonathan is advocating for it, there are others who’d not be comfortable with automatically moving it in an absolutely-scheduled manner, regardless of demand. Yes, cost of capex/opex is going down with time - but, why should we force people to upgrade their hardware according to a fixed schedule and ahead of there being a need for it? Why not just let them enjoy the benefit of having their costs reduced by advancements in hardware? Later, when “benefits” come in the form of network usage growing the economic value of the network - their costs would be more easily offset.
Once demand picks up, a dynamic floor will form organically form with the algorithm as proposed (as demonstrated above by Ethereum data back-tested against the algorithm - the blue line never dips even though it could, because the TX load keeps making higher lows).
Yeah, talked with @MathieuG just now, how about simply “CHIP: Adaptive Blocksize Limit Algorithm for Bitcoin Cash”
BTW, the old median proposal from BitPay was called “adaptive”, and this CHIP is much similar to it in spirit.
Oh yeah, I love this idea, I’m gonna use it as such! It becomes a sort of a roadmap:
- Bitcoin Untethered - Phase 1: Adaptive Blocksize Limit Algorithm
- Bitcoin Untethered - Phase 2: Fast-sync Commitments
2 Likes
Yes, I thought that the current state of the art was described by the graphic I included in my draft summary.
What are the concerns that the others have?
A flat min implies a world where software and hardware no longer improve, and produces a (theoretical) vector where participants game the system to keep the limit at 32MB. A constantly growing min implies a social contract that says that we expect the network to gain at least a minimum amount of capacity every year if only due to the bare minimum of hardware / software improvements.
Your argument seems like it’s moved us a little backward from where we were. There is elegance and simplicity in the min/max/delta (or gamma) approach suggested by the graphic in the summary:
- The limit cannot ever go lower than min, regardless of delta
- The limit cannot ever go higher than max, regardless of delta
- We can adjust delta without having to worry about corresponding effects on min or max
What if we decide that the limit should adjust faster or slower, but we don’t want to change min or max? What if we decide that we want to change min, without changing max or delta? This is all a lot easier to refine and understand if these are called out independently.
1 Like
Ok, how’s this: I will implement the boundaries and produce an accurate graphic both with/without the boundaries, and then we’ll be able to make better arguments.
Here’s another way to think about it.
I think we can all agree that our vision for BCH looks something like “a billion users, GB+ blocks, with time to get there and remain sufficiently decentralized.” In other words, our goals exceed our current capabilities, and we should all expect to keep innovating and expanding capacity because we are all working towards that goal. It’s the social contract stuff. Baking even the possibility that the limit can get stuck at 32MB doesn’t send the right message in that regard, and creates the possibility for future conflict. By setting a growing min, we are telling the network that we plan to always grow, if only a little.
Maybe the min grows very very slowly, IDK. But allowing it to be flat feels wrong, IMO.
Late edit: and while i agree that “marketability” should come second to technical concerns, one option allows us to at least tell people in a year “the block size limit is now 40MB” even if demand doesn’t show up, while the other option would require us to explain why we are still limited to 32MB. While I understand that this is a naive argument, it’s nevertheless reflective of how the ecosystem thinks.
2 Likes
I might be about to ask the dumbest question anyone has asked so far in this thread but…
I have read the current proposal on gitlab (commit 741e88f876a003a6c87d6ed21fb74b8410ea421e) which includes maximum and minimum guardrails on the algorithm.
Is the maximum guardrail limit itself considered unsafe? if the algorithm were hovering close to but still below the maximum for some reason, would this be considered bad?
2 Likes
None of latest (few months) iterations of @bitcoincashautist’s algorithm can be really considered bad.
It’s just good, very good or great I would say.
Nothing “bad” would immediately happen outright if we implemented any of the versions. We would still get a lot of time for fixes (a year at least) even in the fastest possible growth scenario.
In general as Jessquit said, this discussion can be bikeshedded to infinity (I have still have bad memories nightmares from Core years), so we should just focus on what can we get into the consensus now so it is ready for 2024 and discuss perfecting the algo improvements for the 2025 upgrade.
Once it’s “in”, then we can bikeshed possible improvements for another year.
1 Like
Hey Griffith, nice to see you again!
Wdym, where did you see that in that commit? The current proposal doesn’t have the 2 fixed-schedule “guardrail” curves, it only has the flat 32 MB as the flat floor, and the algorithm itself has a natural boundary since it reaches max. rate (2x/yr) at 100% full 100% of the time, which would be faster than BIP101 curve, however, consider what it would take to intercept it:
Cycle:
- 8 months 100% full, 100% of the time (max. rate)
- 4 months 100% full, 33% of the time (falling down)
The gap widens with time because during dips in activity, the fixed-schedule curve races on anyway and increases the distance.
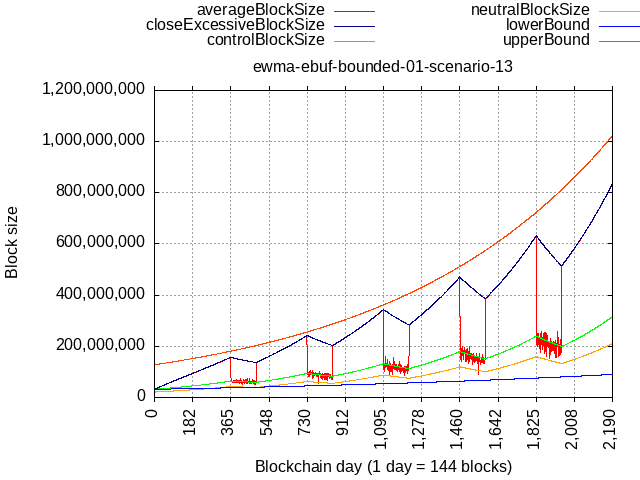
If we reduce the gap duration to 3 months, i.e. a cycle of:
- 9 months 100% full, 100% of the time (max. rate)
- 3 months 100% full, 33% of the time (falling down
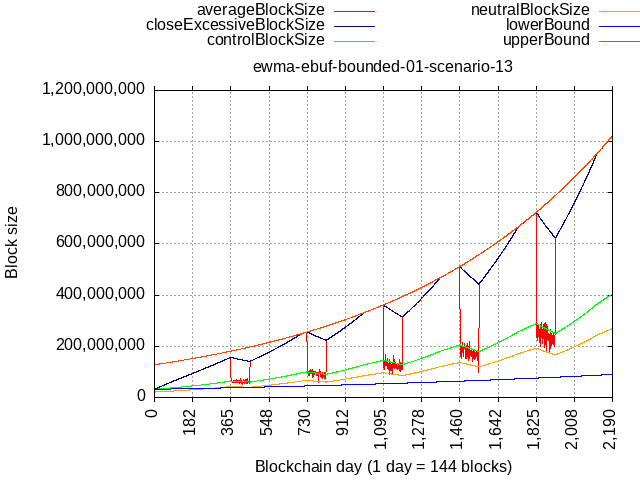
then sure, it could catch up, but is it even possible in practice to sustain 100/100, all it takes is minority hash-rate to defect or user activity to dip for whatever reason.
It would also take infinite supply of transactions to maintain the 100/100 load, from where would they come at those ever-increasing rates?
If it’s “only” 90% full 90% of the time then such load would have to be sustained for more than 4 years to catch up:
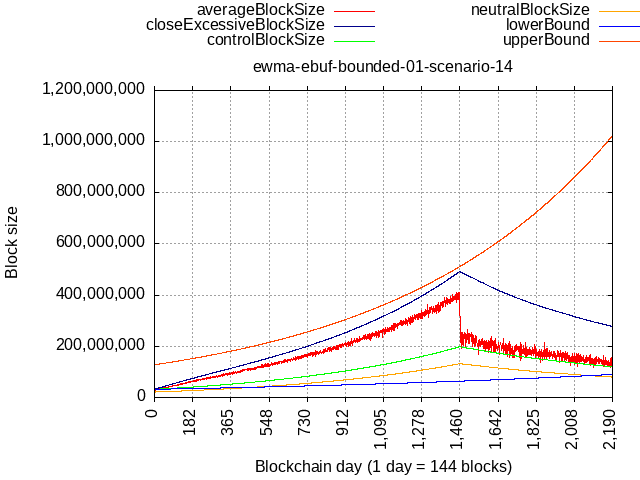
I hope this demonstrates why it’s “safe” as it is, with max. rate of 2x/yr.
Anyway, I made a new branch and pushed the change I used to generate these plots there, this is how implementation would look like with both guardrails added.
I consider it useless because in practice and after few years it would likely race ahead so much that it becomes impossible to ever hit it even with algo’s faster rates, so what purpose would it serve?
I will just repeat J. Toomim’s comment from Reddit:
Should blocks end up being consistently full, this algorithm could result in exponential growth that’s up to 2x faster than BIP101. I think that’s kinda fast, and it makes me a bit uncomfortable, but if we all hustled to beef up the network and optimize the code, we could probably sustain that growth rate for a few years, and would probably have enough time to override the algorithm and slow it down if needed, so it’s not atrocious.
What he was proposing is to replace the flat 32 MB floor value, with a slow-moving fixed-schedule curve:
So my criticism is that in the absence of demand, this algorithm is way too slow (i.e. zero growth)
This was his suggestion and explanation on why he consideres 2x/yr max. rate as something which is probably OK (and I hope my plots above demonstrate that it will be OK):
My suggestion was actually to bound it between half BIP101’s rate and double BIP101’s rate, with the caveat that the upper bound (a) is contingent upon sustained demand, and (b) the upper bound curve originates at the time at which sustained demand begins, not at 2016. In other words, the maximum growth rate for the demand response element would be 2x/year.
I specified it this way because I think that BIP101’s growth rate is a pretty close estimate of actual capacity growth, so the BIP101 curve itself should represent the center of the range of possible block size limits given different demand trajectories.
(But given that these are exponential curves, 2x-BIP101 and 0.5x-BIP101 might be too extreme, so we could also consider something like 3x/2 and 2x/3 rates instead.)
If there were demand for 8 GB blocks and a corresponding amount of funding for skilled developer-hours to fully parallelize and UDP-ize the software and protocol, we could have BCH ready to do 8 GB blocks by 2026 or 2028. BIP101’s 2036 date is pretty conservative relative to a scenario in which there’s a lot of urgency for us to scale. At the same time, if we don’t parallelize, we probably won’t be able to handle 8 GB blocks by 2036, so BIP101 is a bit optimistic relative to a scenario in which BCH’s status is merely quo. (Part of my hope is that by adopting BIP101, we will set reasonable but strong expectations for node scaling, and that will banish complacency on performance issues from full node dev teams, so this optimism relative to status-quo development is a feature, not a bug.)
1 Like
The main topic these days has been this lower bound, to replace the flat 32 MB floor with some fixed-schedule floor curve that would estimate trivial capacity that gets added naturally simply because stuff gets better and cheaper by default. You can’t buy a 486 PC now, right, you buy the cheapest one off the shelf it will be better than some PC 10 years ago.
Toomim and @Jessquit are both advocating for it. Problem is, a fixed-schedule slower exponential may look safe now, but it compounds forever, and what if tech. growth fails to maintain exponential growth? We’d end up with what would effectively be no limit.
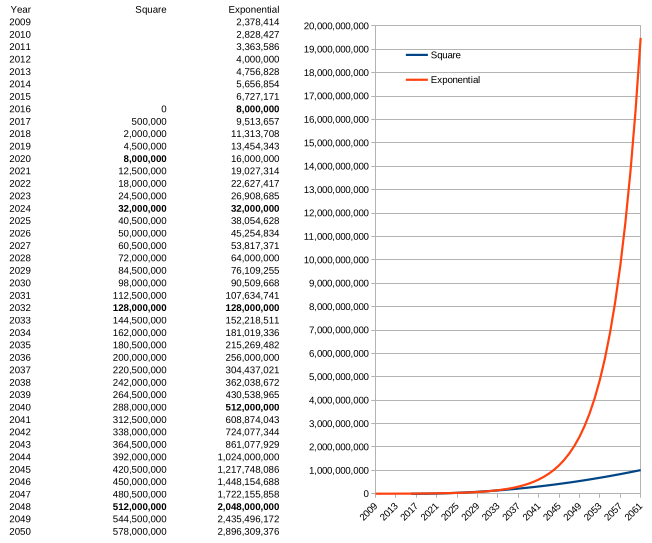
But, who forces us to consider only exponential? In that plot, I added a quadratic curve for comparison, and I have to say it has appeal, because the time to double increases with each doubling, while with exponential it is constant - observe the bolded values. The square would bring us to 1 GB in 2061, 2 GB in 2080, 4 GB in 2106, 8 GB in 2144 …
2 Likes
Apologies, a bit of a blunder on my part. Trying to catch up on the discussion and learn. I confused the notion of a maximum growth rated bounded by the algorithm itself mentioned in the CHIP with one that is hard-coded as both had been discussed. Thank you for the clarification. Cheers
4 Likes
Comparison of with/without boundaries, here initialized with 0.707 MB in 2009, and plotting evolution of sum of block sizes of BTC+BCH+ETH.
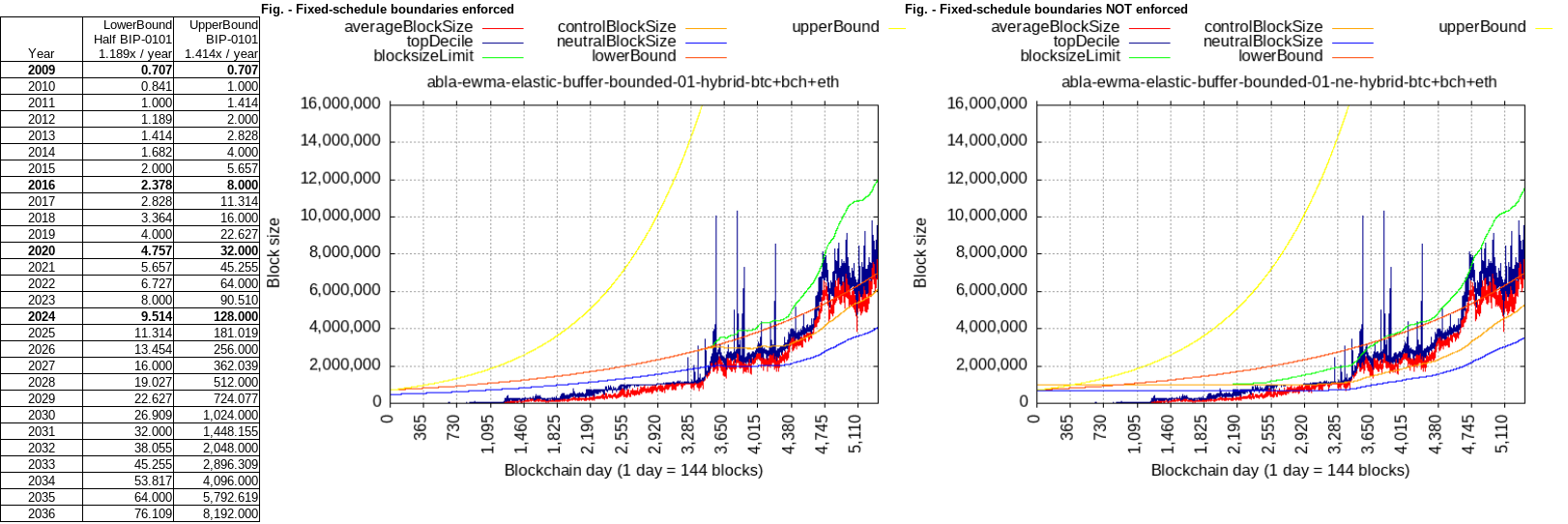
Upper (BIP-0101) curve is never to be hit.
Lower curve (half BIP-0101 rate) at first works to grow the limit even without any volume, but once volume comes, the demand-driven limit (green) crosses over and doesn’t go back, making the lower bound kinda pointless from then onwards, right?
Even without the lower bound, the network activity itself is able to drive the algorithm to form a monotonic curve, it doesn’t go down (even though it could)! The “neutralBlockSize” (blue) is the threshold for the algorithm - as long as more bytes are mined above it than gaps below it - it all keeps going up.
Also, the lower bound rates are arbitrary and starting point is arbitrary, as well. If initialized at Bitcoin genesis, the schedule would be bringing it to 9.5 MB in 2024! So, if we’re so much ahead of schedule, do we even need it anymore? 32 MB flat floor is plenty to bootstrap the demand-driven algorithm.
Can we keep it simple and not overthink / overengineer this by adding useless extras?
1 Like
Case 1: the lower limit is slower than the algo: It does nothing.
Case 2: the lower limit is faster than the algo: due to the nature of any meaningful (exponential) growth curve, it’s going to quickly be so large as to be undifferentiated in practical terms from unlimited. This violates the basics of any block cap algorithm.
Case 3: in-between doesn’t happen on exponential curves except in some outrageous statistical anomaly.
Worst case: really bad, equivalent to unlimited. This isn’t an acceptable approach IMO, besides the additional complexity it puts on consensus. It doesn’t matter if it would be nice if real capacity were there to meet some imaginary future demand - if it’s not there, it’s not there. Hanging a sword of damocles (unlimited block cap) over BCH’s head is not going to motivate all the various and growing number of stakeholders to massively overprovision in case a unicorn happens by.
If we do get to a point that there is demonstrated and credible commitment from the whole ecosystem to massively overprovision, then that would be a reasonable time to consider such an exceptional engineering decision.
3 Likes
What is required in order to confirm this feature for the next major upgrade cycle? I agree with Shadow, this is something that can be bikeshedded ad infinitum. The current proposal satisfies all significant concerns and is a big step up both technically and from a marketing perspective. Let’s push this off dead center and get it in the works.
BCA becoming confident enough that it won’t be torpedoed by a significant stakeholder (and torpedoing is the natural state of CHIP, so that’s not bad per se) that he finalizes the chip and proposes it for uptake, where stakeholders look around the room and decide to implement as specified, or not.
The milestones of the process that GP and I think others follows are here. Any CHIPs not already finalized are late at this point.
3 Likes
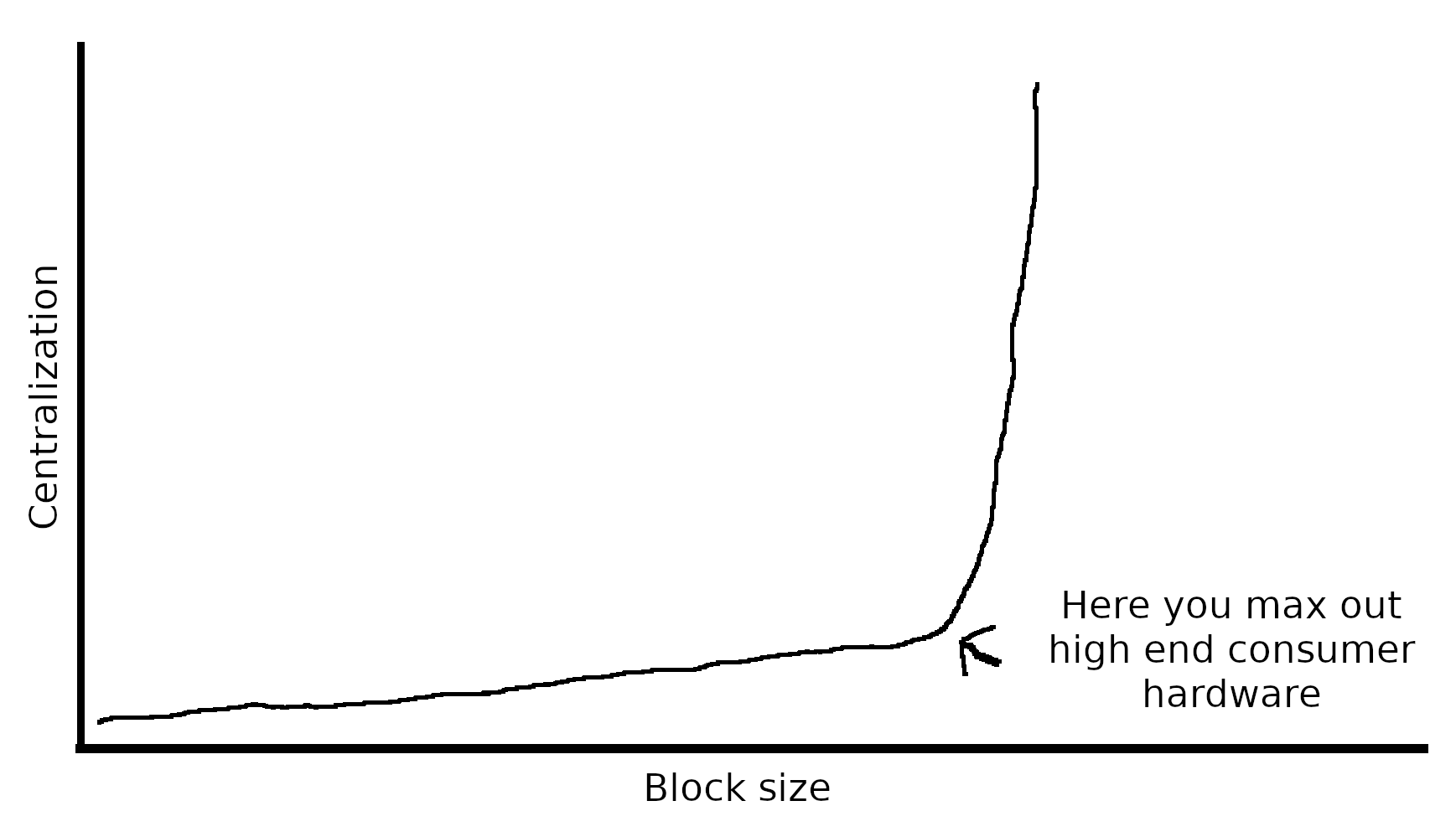
I support this approach. A limit is needed so you can’t feed unlimited false blocks to nodes. Many of the small blocker arguments are also valid concerns, but they are of course not a concern at 1MB. Bigger scale is an upward slope when it comes to decentralized nodes. When you max out high end consumer hardware it suddenly goes exponential. That’s why we must keep the block size limit below the point where we max it out. Fortunately both software and hardware allows for scaling over time.
4 Likes