Title: Excessive Block-size Adjustment Algorithm (EBAA) Based on Weighted-target Exponential Moving Average (WTEMA) for Bitcoin Cash
First Submission Date: 2023-04-13
Owners: bitcoincashautist (ac-A60AB5450353F40E)
Type: Technical, automation
Layers: Network, consensus-sensitive
This has been in draft for a while and still is, but thought to make a new topic for it, as continuation of discussions here.
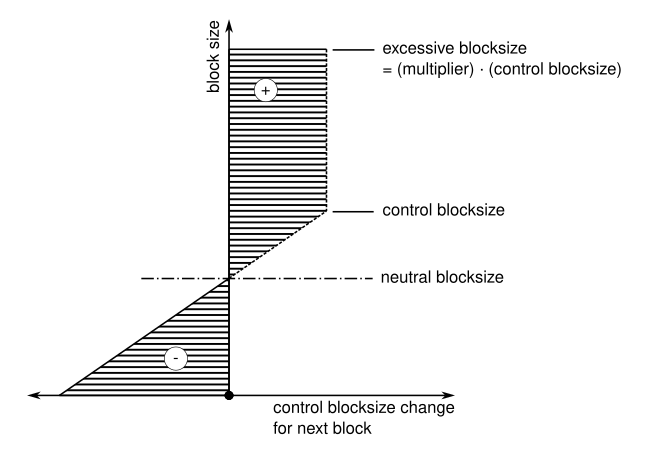
The idea of automating adjustment of blocksize limit has been entertained for a long time. The code-fork of BCH launched by BitcoinUnlimited actually implemented the dual-median algorithm proposed by @im_uname
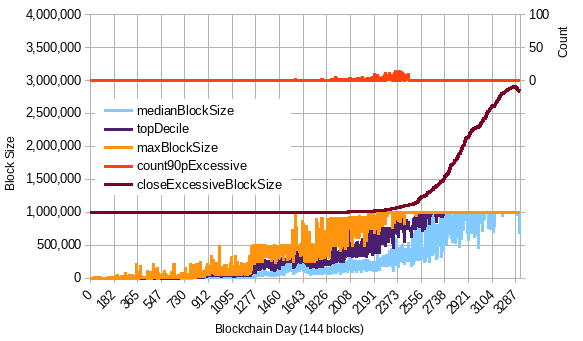
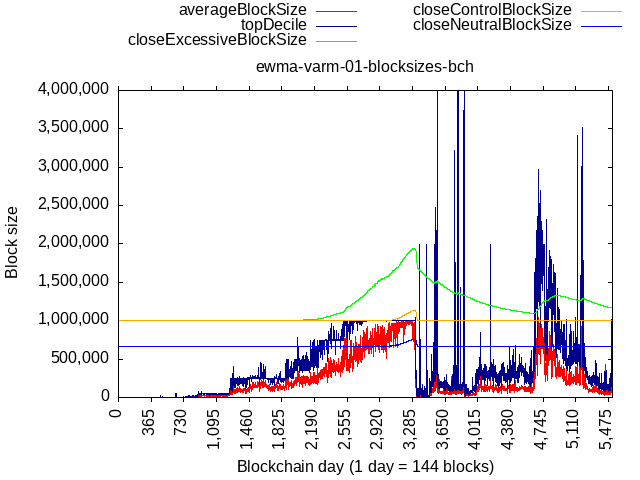
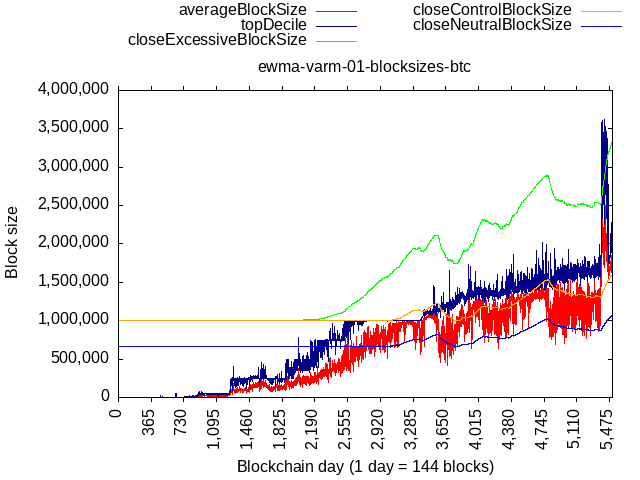
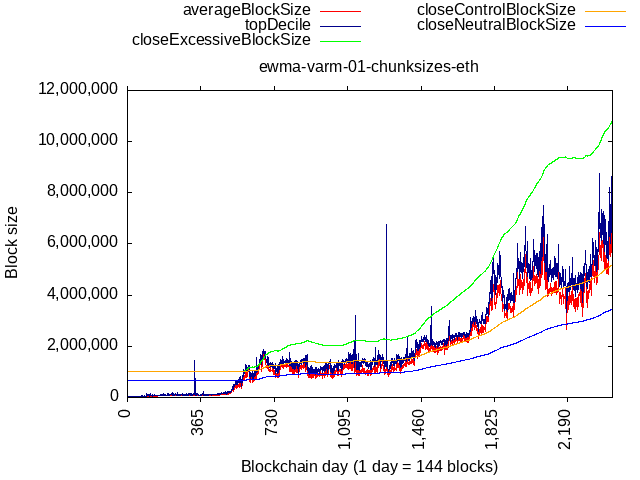
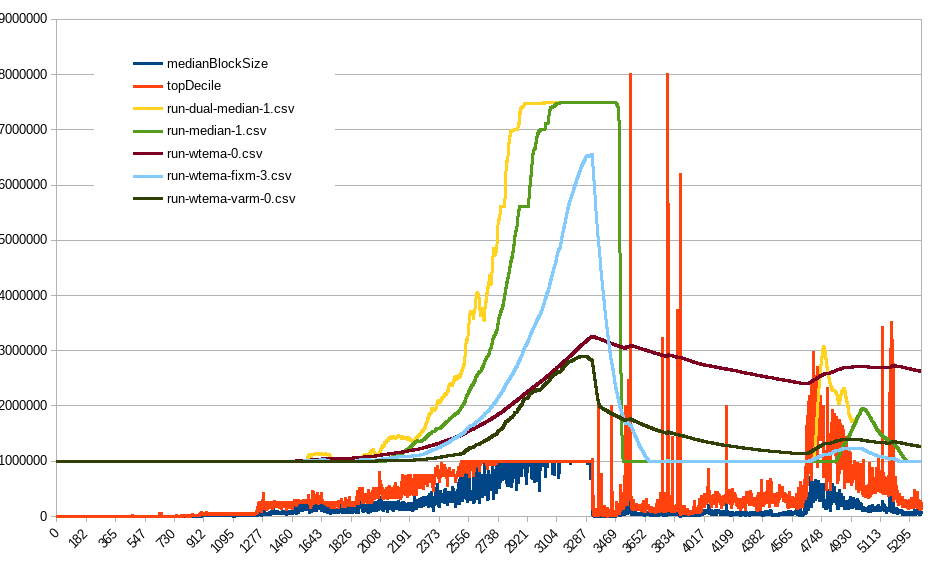
The last post in the linked discussion compares the algos back-tested against actaul BCH and ETH blocks, I’ll repeat it here:
- single median, like Pair’s (365 day median window, 7.5x multiplier)
- dual median, like im_uname’s OP here (90 and 365 day windows, but 7.5x multiplier)
- wtema with zeta=10 and 4x/yr max, my old iteration
- wtema with zeta=1.5 and 4x/yr max, multiplied by fixed constant (5x)
- wtema with zeta=1.5 and 4x/yr max, multiplied by a variable constant (1-5x) - my current proposal
BCH data:
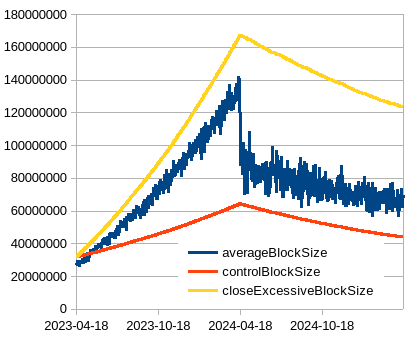
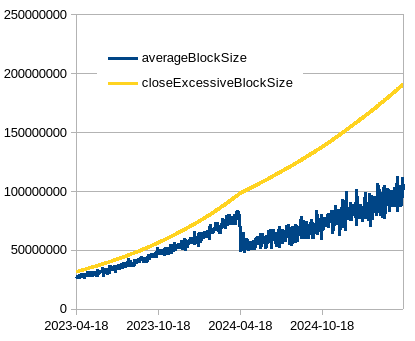
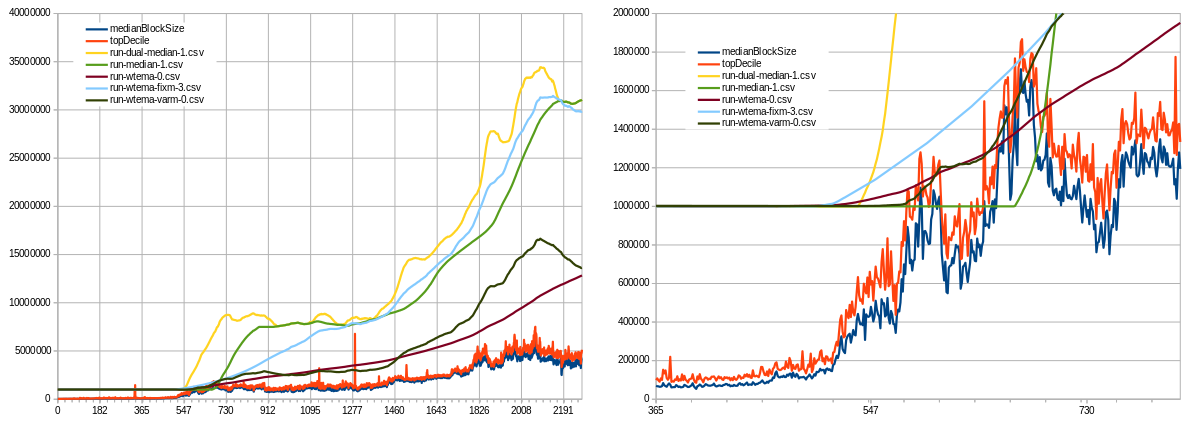
Ethereum data (note: size is that of “chunks” of 50 blocks, so we get 10-min equivalent and can better compare), the right fig is the same data but zoomed in on early days, notice the differences in when the algos start responding and their speed. Also notice how the fixed-multiplier WTEMA pretty much tracks the medians but is smooth and max speed is limited as observed in the period 547 to 1095.
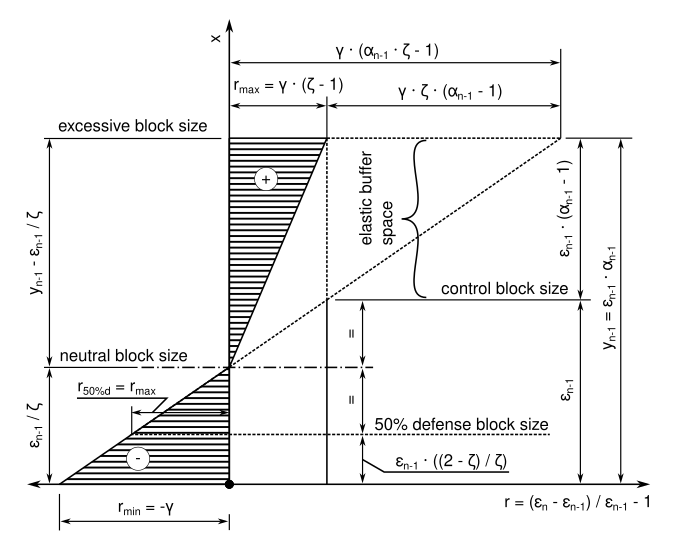
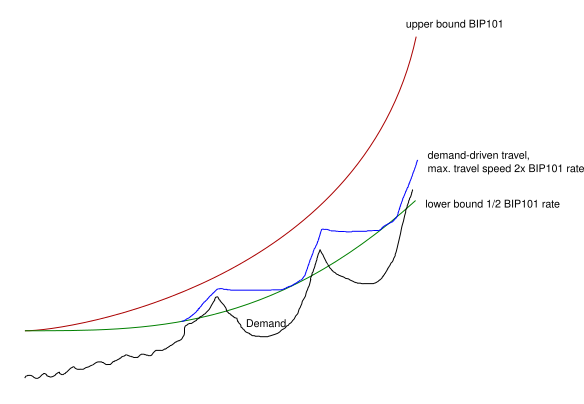
Key difference between wtema with zeta=10 and wtema with zeta=1.5 is in algo stability at %hashrate mining at max. With z=1.5, 50% mining at max and 50% mining at some flat value would be stable, while with zeta=10 it would not and the limit would continue growing.
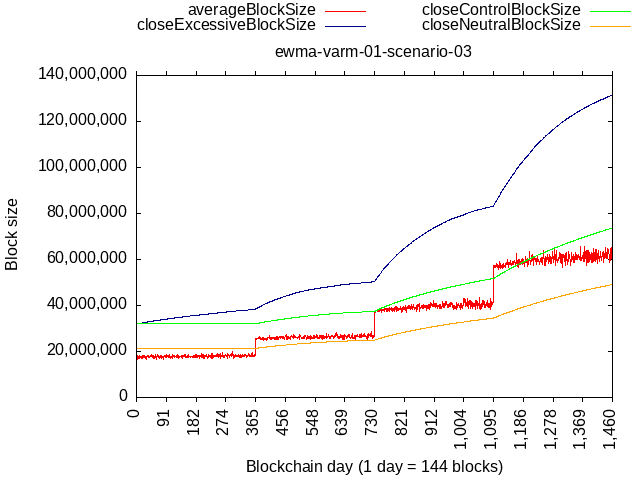
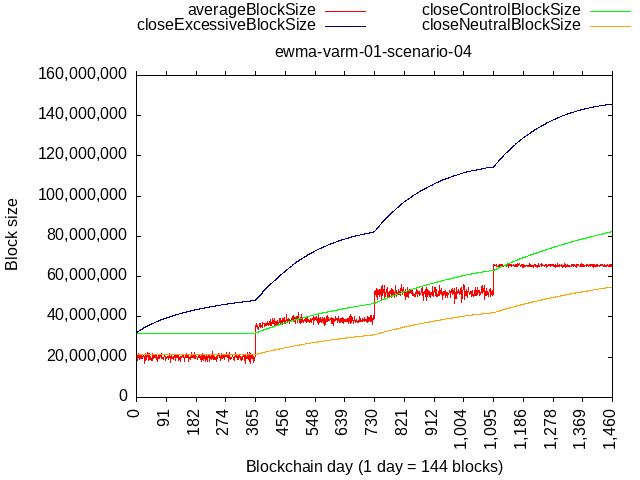
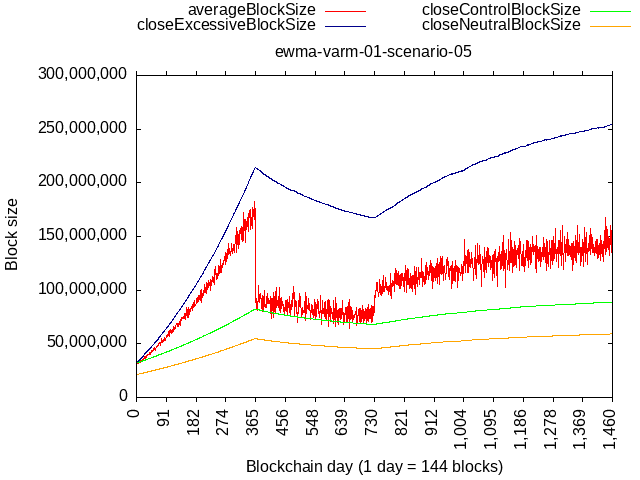
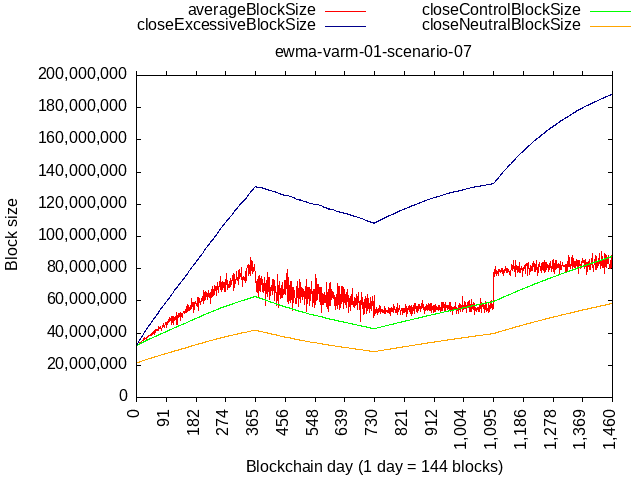
To illustrate, below is a simulated scenario where we initialize the algorithm with 32 MB limit & multiplier=1 and then:
- 1 year where 80% hash-rate mines exactly at the limit, and 20% mines flat 8 MB - this epoch results in about 5x increase of the limit
- 1 year where 50% hash-rate mines exactly at the limit, and 50% mines flat 8 MB - this epoch results in reduction of about 25% (and asimptotically approaches a point of stability)
Left - wtema zeta=1.5 with variable multiplier 1-5
Right - wtema zeta=10