
I think the CHIP uses basically the same formula as k=1, just a bit rearranged, and different latency and bandwidth (or impedance, if you will, which is 1/bandwidth) estimates.
Is it, though? I’m not certain, as I recall from reading the paper because of the parallel PoW mechanism, there might actually be less overall waste. But, I could absolutely be wrong here and as I’m not an expert, I’ll drop that here haha
The other benefits of tailstorm are irrelevant here so I’ll look back and mention on another chain.
Also, none of this CHIP would prevent tailstorm from being implemented in the future, if deemed necessary, so again, mostly irrelevant discussion for here beyond orphan rates.
1 Like
yes there is less scrapped work, so network gets more bang-for-the-buck, but is that really the thing to optimize for? saving some % in orphan rate “buys” us that much % more hashes per unit of block revenue, that’s it - just few % more hashes per block. We can just wait for the price go up for that much % and we’ll get that much more hashes, too.
One more thing, just reducing to 1-min blocks should be compared to tailstorm of T=10min and k=10, so 0.887% vs 0.089% (for 0.5s latency)
Well because that’s not the only benefit, the other (which idk is relevant to this topic) is making mining more fair and punishing selfish miners (amongst others like weak PoW which could have some benefit, and reduced confirmation latency, censorship resistance to varying degrees (which lower block times also help with!)) at the same time. Tailstorm is a nice wrap-up of general improvements.
I don’t believe so. The 1min block times without tailstorm should be compared to 1min block times with tailstorm. But I suppose that depends on the angle you’re looking at it from. I would compare 1min with to 1min without. Not a major difference but a bigger one.
1 Like
The 1min block time with tailstorm k=15 will have 4second subblocks and a huge uncle rate, which is not seen in the table, can’t just sweep that under the rug. Game mechanics of 4s subblocks and all those uncles and uncle trees haven’t been analyzed enough IMO + there’s the issue of 0 block subsidy, what then? How does the “fair” feature work out then?
1 Like
I think part of the analysis is that k-15 is too great anyways. Diminishing returns with more subblocks. k=3 or k=5 would obtain most of the benefit. Perhaps the mechanics have not been analyzed enough yet, but gaming is less fruitful when the rewards are discounted. The point of 0 block subsidy in the far future which I believe is why attack vectors considering transaction fees (which I can’t imagine would be worse with tailstorm, just equivalent (though perhaps this itself would need to be further explored)) were outside the scope of the original tailstorm paper.
But sure, let’s say 12 second subblocks (though given the tree structure not sure 12s is necessarily accurate across all cases since you could have multiple branches with discounted rewards), that certainly would increase the “uncle” rate but how drastic, I’m not actually sure. Back to the gaming of it, absolutely, further analysis would be needed.
Either way, this all makes me excited for Nexa’s implementation of Tailstorm with their 2min blocks. Perhaps not apples to apples, but should be very close for us to examine!
3 Likes
In a world where my UTXOs can come from many non-p2pkh sources, how can anyone I send money to rely on 0-conf without better doublespend protections? (ZCE?)
If I’m trying to send you $1000 and then some DeFi transaction that I got that money from gets rolled back, do we get screwed?
3 Likes
That’s a great question, thank you for that one!
Security of payments in Bitcoin Cash rests on a lot of details, stuff people like me and others have been pushing on being important. For instance the utxo model doesn’t make miner-extracted-value a thing in most cases where it is in the account model. We have been pushing to keep MeV out of the protocols and contract designs for a range of reasons.
One of the nice side-effects of MeV being absent is that it makes the miner replacing a transaction something that just isn’t economically feasible. Which is the status quo on most Bitcoin related chains and we haven’t seen it for 15 years.
This is the underlying reason why zero conf works, because first seen is actually practiced by miners. They have no reason to do otherwise. Notice that as our ecosystem grows that the full nodes people will be sending transactions to are going to be owned by non-miners (like merchants). Meaning miners won’t ever see the double spending transaction at all.
This is the bottom line why you hear the people that actually do in-person payments have no historical double spend risk. The incentives are there to keep and protect first-seen.
The tests done by BU and published by Peter Rizen in 2018 showed the propagation of a transaction onto the network was a steep starting curve with a slow tail. Meaning that 50% knew it practically instantly, the vast majority in 3 seconds. The laggards in 5 seconds.
This research is insanely useful in understanding the possible double spend attacks. With miners not accepting (or even seeing) double spends after mere seconds after the network already has the “original” transaction paying you.
The 15 years of history shows this well, bitcoin core had to ram through replace-by-fee code to break it. Because it actually works out of the box.
You asked about a non-p2pkh transaction and this is very likely in reference to the double spend proof not protecting such. What you have to understand is that the double spend proof is meant to be a signal to the merchant (or receiver) in order to catch the ‘thief’. Like I explained in my 2018 talk (vimeo), the chance of a double spend getting through is very low, but we can’t guarentee it being zero. So the double spend proof is there to make sure that thiefs can’t just try for free until it may actually succeed. Instead the merchant gets notified.
The double spend proof doesn’t prevent or avoid technical things, it just moves the cost of trying to the thief instead of the merchant. It is meant to change behavior of people.
A non-supported transaction doesn’t mean the risk of stealing went up, it just means that you won’t get notified if they tried. The risk is, and stays, insanely low.
Next to that, wallets can (and IMO should) use p2pkh for person to person payments. So a defi wallet would transfer the money to the same person’s payments wallet where they pay the merchant from. And you instantly have a double spend proof supported scenario. Everyone happy.
Knowing that a transaction is settled within one or two seconds and knowing that miners have no incentive to assist theft, a user can then quite confidently accept a payment without confirmation. Has been the case for years now.
Normal caveats still apply. If you buy a house or a car or anything bigger, you are going to have to KYC oneself anyway. So a double spend is simply seen as a “you haven’t paid yet”.
Nowadays if you buy a car of similar, your payment has to have settled before they hand over the product. That is counted in days in the legacy finance system, so waiting couple of blocks is still going to be an amazing improvement.
3 Likes
If people pay with for example a child of a unconfirmed Moria liquidating transaction propagating on the network, then this transaction will likely be orphaned since every pool will be working to include their own to collect the 1.2x. When you have anyone-can-spend UTXOs, with high reward to those who claim, then pools will start to include their own transaction because of rational self-interest. Such a UTXO will create a totally new threat model for zero-conf.
1 Like
And the first one to suffer from that is the actual users of the protocol, the users of the script. THEIR money is being stolen by those miners.
As such, if this happens, the designers either fix it, or the users will go to another script that solves it.
Nobody wants MeV in an ‘app’, for extremely obvious reasons.
Do note that this is not solved with faster blocks. As such this example, should it become widespread, doesn’t take away the argument that to grow Bitcoin Cash, we should aim as zero conf as the main usability target.
The first user, that managed to get his liquidating transaction propagated on the network, was able to do a swap to another crypto on a service accepting zero-conf. He is now a happy ZEC owner and lost no MUSD.
Edit:
Faster blocks is not a proper solution, but it makes it a little better. If we want a proper fix we should implement Avalanche. Eliminating MEV (except from cross chain MEV) on BCH with a combination of the UTXO model and Avalanche Pre-Consensus is the way to go. The UTXO model eliminates sandwiching and Avalanche Pre-Consensus gives rapid economic security. With Avalanche Pre-Consensus, as developed on eCash, you will vote on transactions and not allow orphaning of accepted transactions in blocks for some time.
Reducing block time or enhancing security for sub-blocks is, in my opinion, far superior to ZCE. The two potential solutions that exist is either simplify the process by reducing block time while maintaining the same reward scheme (equivalent to a 10-minute block reward) or implement Tailstorm for sub-blocks, which increases complexity. The former is the better option, especially with faster internet connections.
Economic security is what matters. PoW will never provide much of it at the tip of the chain.
I thought this could be relatable on confirming that Orphan rate is very low look at Shadow research
2 Likes
My initial read of this CHIP already had me convinced that this is worth researching and considering.
With that in mind, after some time, while using BCH as my primary currency, I can’t help but notice the pain brought by waiting for confirmations. There have been many real-world scenarios where faster blocktime (or majority hashrate  ) would have made my life a lot less stressful.
) would have made my life a lot less stressful.
So, just wanted to add two sats here saying that I endorse continuing down this path of finding a reasonable proposal to addresses these issues.
6 Likes
The solution is as elegant as it is simple.
Instead of aiming for a change that has massive massive costs to the entire ecosystem, will take various years to chrystalize and safely deploy, will create bad PR / FUD and confusion.
Instead of all that bad stuff, the simple and obvious solution is available. Instant transactions accepted by the market.
Already available. Permissionless. Market driven. Elegant and simple.
Frequently missed facts;
- with BCH being the hated cousin, what makes us special is explicitly ignored by the market. BCH has sane and safe instant transaction capability. But many bigger parties don’t it.
- It may take 5 years for instant transactions to become widespread outside of brick/mortar commerce. But faster blocks will take that long too.
- People starting to accept instant transactions is based on our market power. If, as most here believe, bch becomes popular then instant transactions become inevitable.
- Faster blocks don’t actually solve direct payments. Instant transactions are STILL required to make it a real payment system. The opposite is not the case, though. There is no need for faster blocks when the wider ecosystem accepts instant transactions.
- Towards certainty:
Instant transactions require the wider market to accept it. So it is attractive to assume that a protocol change is more certain to get what we want.
This kind of thinking is missing that the market still decides the value and usefulness of the coin. A protocol upgrade that is too expensive to active will trigger people to leave for another coin.
In short, both solutions require the market participation to succeed.
1 Like
I would agree @kzKallisti faster block could solve a lot of problems that we face right now and would definitely bring better UX in the table. The 10 min block time is outdated and current technology can handle 1-minute block easily making our life a lot easier in the process
3 Likes
Yes, and they work for everything except Automatic Market Makers on chain.
I just had to clarify since you omitted this detail.
The only thing faster confirmations “fix” is AMM markets. Otherwise we should just pursue what already works - instant transactions.
Confirmations (even 10-second ones like proposed in Infrastructure Blocks), are just not fast enough for serious real-life applications like brick and mortar stores or online shops. Instant transactions is the only way.
4 Likes
Why? Do you think variance is due to us being minority hashrate? I’ve seen people say something like “oh variance is due to switch mining causing oscillations” and I wondered where do they get that from. It sounds plausible, but is it true? This is a good opportunity to address that question.
What I found is that it used to be true (with EDAA and CW-144 DAA), but it has not been true since introduction of ASERT DAA in 2020. Still, the common knowledge persisted - because it used to be true, even though it isn’t anymore.
Now it takes a big hashrate event (big price move on BCH or BTC, or halving, or big miner misconfiguration or error) to have noticeable impact on block times. Absent that, real block times are well aligned with the theoretical distribution for a random process targeting 10 minutes.
Let’s examine a few samplings of day’s worth of block times.
Extreme Swings With EDAA
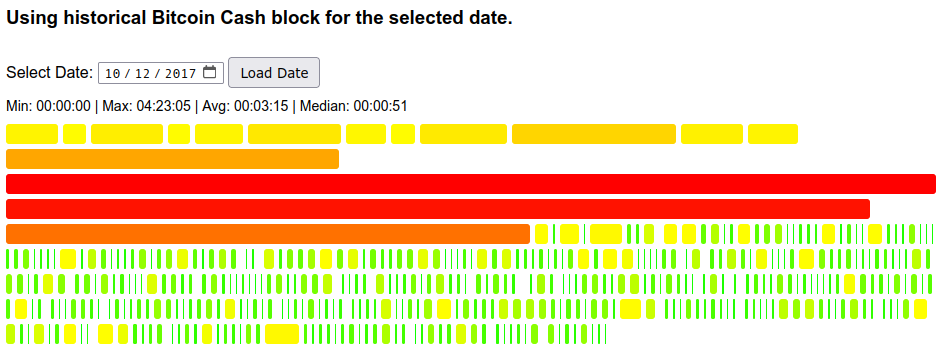
We had EDAA for 106 days (2017-08-01 to 2017-11-13), and during the period:
- Average block time was 5.86 minutes (and variance was extreme due to huge hash volatility as miners were gaming the algorithm)
- BCH created 10,577 more blocks compered to ideal 10-min schedule
- Emission schedule was shifted by 73 days, minting 132k BCH ahead of schedule
The below figure (2017-10-12) illustrates the problems well:
Oscillations With CW-144 DAA
We had CW-144 DAA from 2017-2020, and it maintained the average, but it had oscillations due to nature of simple moving average: of all blocks in the moving average window having equal impact, so when a slow block “enters” the sampling window it drops the difficulty, but then after 144 blocks it “exits” the sampling window and brings it back up - leading to oscillations and volatility in hashrate.
The below figure (2019-10-12) illustrates this effect well:
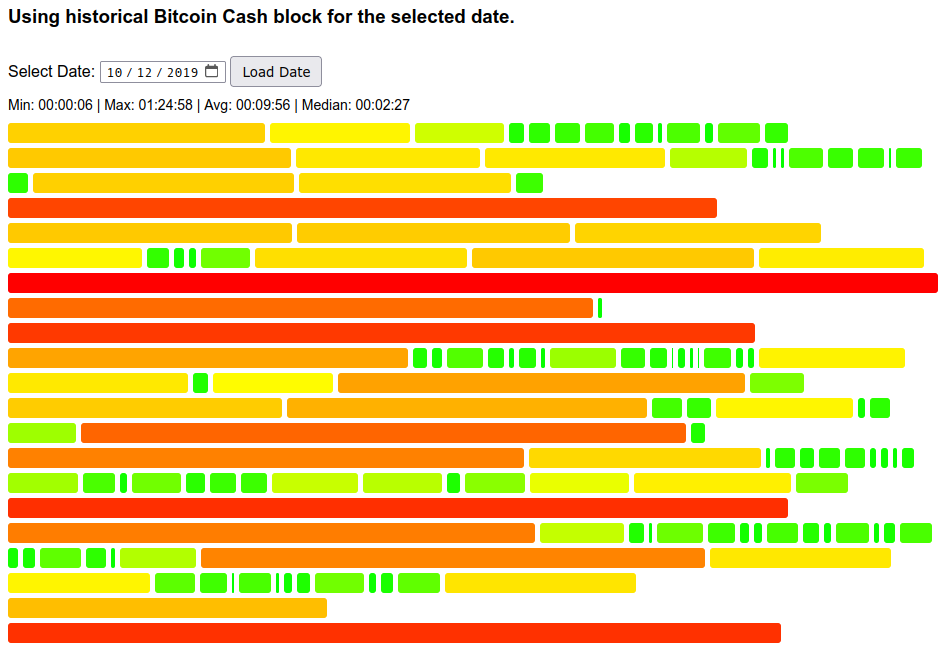
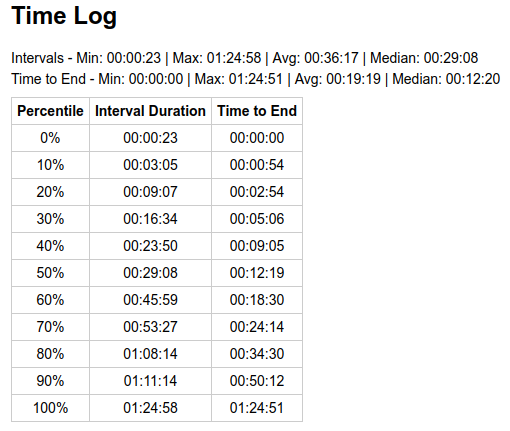
Packs of short blocks followed by packs of long blocks are pronounced. We can compare all the percentiles with calculated theoretical probabilities:
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | ||
| 0.7%* | 00:04 | |
| 10% | 01:03 | |
| 20% | 02:14 | |
| 30% | 03:34 | |
| 40% | 05:06 | |
| 50% | 06:56 | |
| 60% | 09:10 | |
| 70% | 12:02 | |
| 80% | 16:06 | |
| 90% | 23:02 | |
| 99.3%* | 49:37 |
* 1 block per day (1/144 = 0.7%)
Notice that the whole distribution of wait times is skewed far from the theoretical random process (median 1-conf wait of 12 minutes, while in a truly random process it is expected to be 7 minutes).
So yes, it definitely used to be true that DAA oscillations and miners switching were causing additional variance. Jonathan Toomim’s analysis goes more in depth on this.
Current Situation (ASERT)
Is that still the case, are we now experiencing additional variance or is it better aligned with expected theoretical distribution?
Steady State (ASERT)
Days with sideways price movement (2024-09-26) show variance expected of a random process:
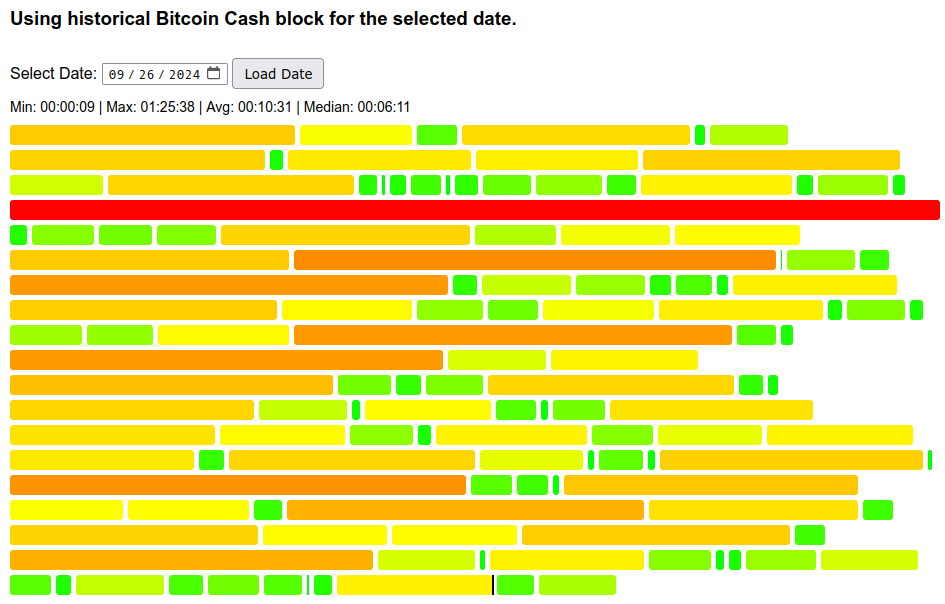
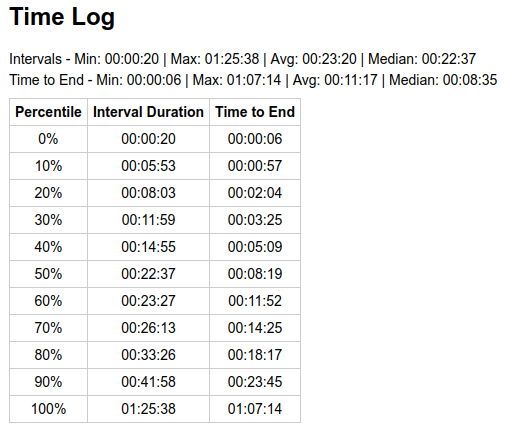
There’s still some discrepancy in percentiles when compared to above theoretical, because 1 day worth of blocks (144 blocks) is still a small sampling window, not enough to fully smooth out impact of luck, and some switch mining can still impact our block times. However, it is much less pronounced than just normal variance of a random process.
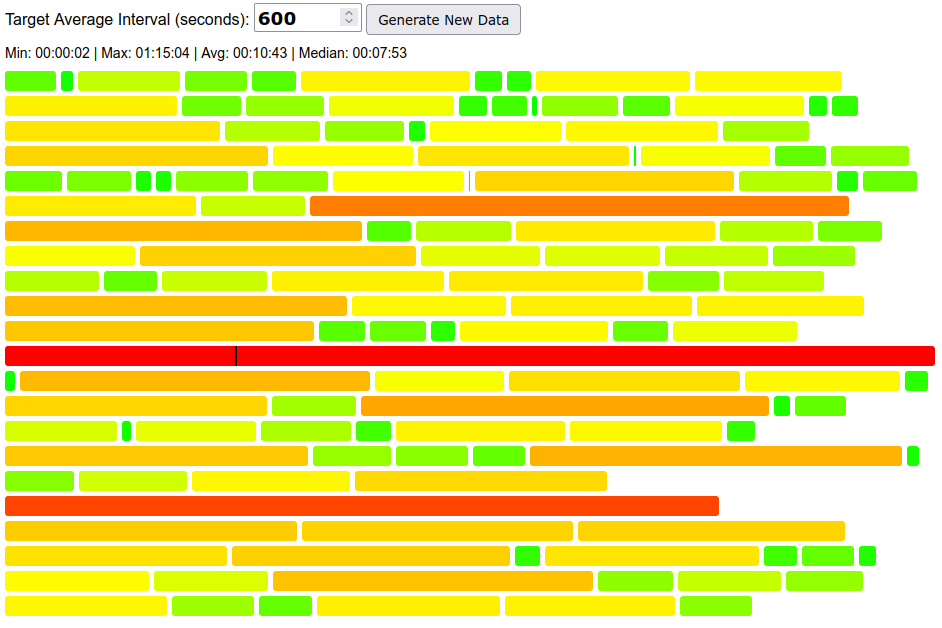
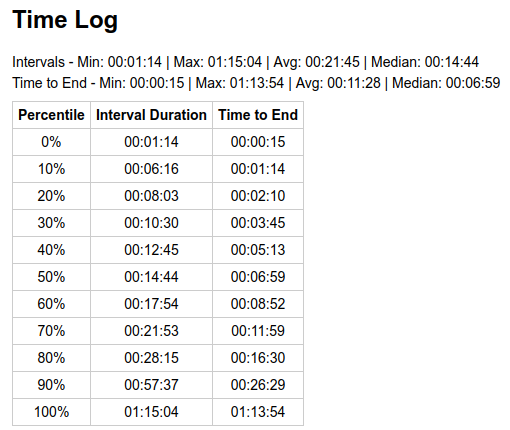
To confirm impact of luck, we can generate random data and observe interval distribution looks similar, and the percentiles table is affected by the particular sampling of ~144 blocks:
Upward Price Move (ASERT)
If the price goes up enough, the average block time is expected to be proportionally faster until DAA catches up - but the individual block times are still expected to be randomly distributed around the stretched average. See sample from 2025-05-22, it had a +9% price move and result was 9:10 average (-8%) for the day.
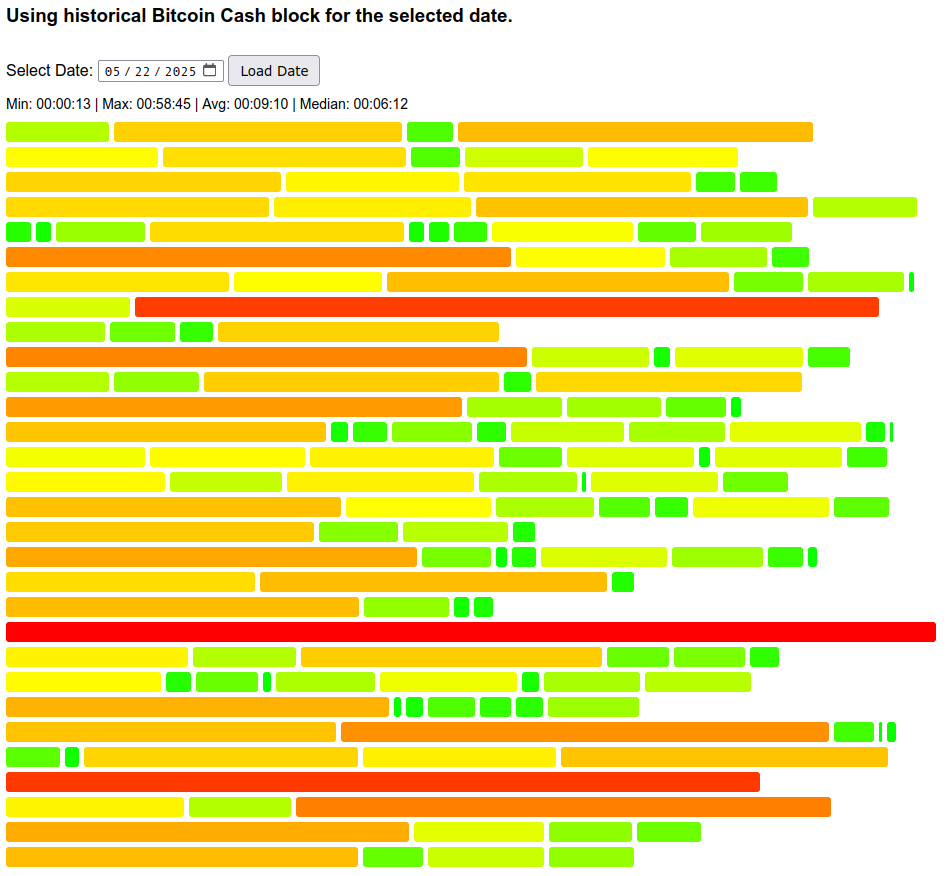
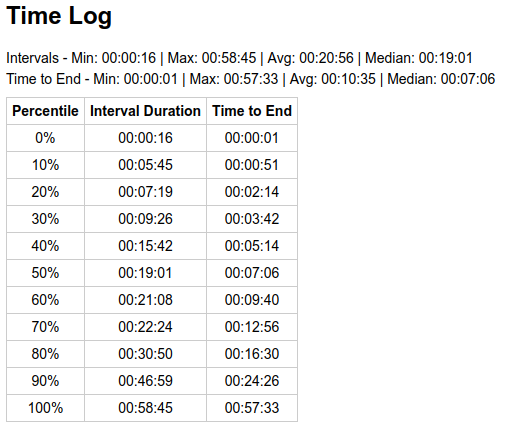
We still had an outlier of 58 minutes, and if you pick a random point on the timeline for that day - you get a distribution where there’s 20% chance of waiting >16 minutes, and 10% chance of waiting >24 minutes. This is close to theoretical:
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | (case 550s average) | |
| 0.7%* | 00:04 | 00:04 |
| 10% | 01:03 | 00:58 |
| 20% | 02:14 | 02:03 |
| 30% | 03:34 | 03:16 |
| 40% | 05:06 | 04:41 |
| 50% | 06:56 | 06:21 |
| 60% | 09:10 | 08:24 |
| 70% | 12:02 | 11:02 |
| 80% | 16:06 | 14:45 |
| 90% | 23:02 | 21:06 |
| 99.3%* | 49:37 | 45:29 |
* 1 block per day (1/144 = 0.7%)
Downward Price Move (ASERT)
We can observe the same in a downward price move (2025-02-03). The price moved -15% over 2 days, and block time average for the 2nd day was +22% off target.
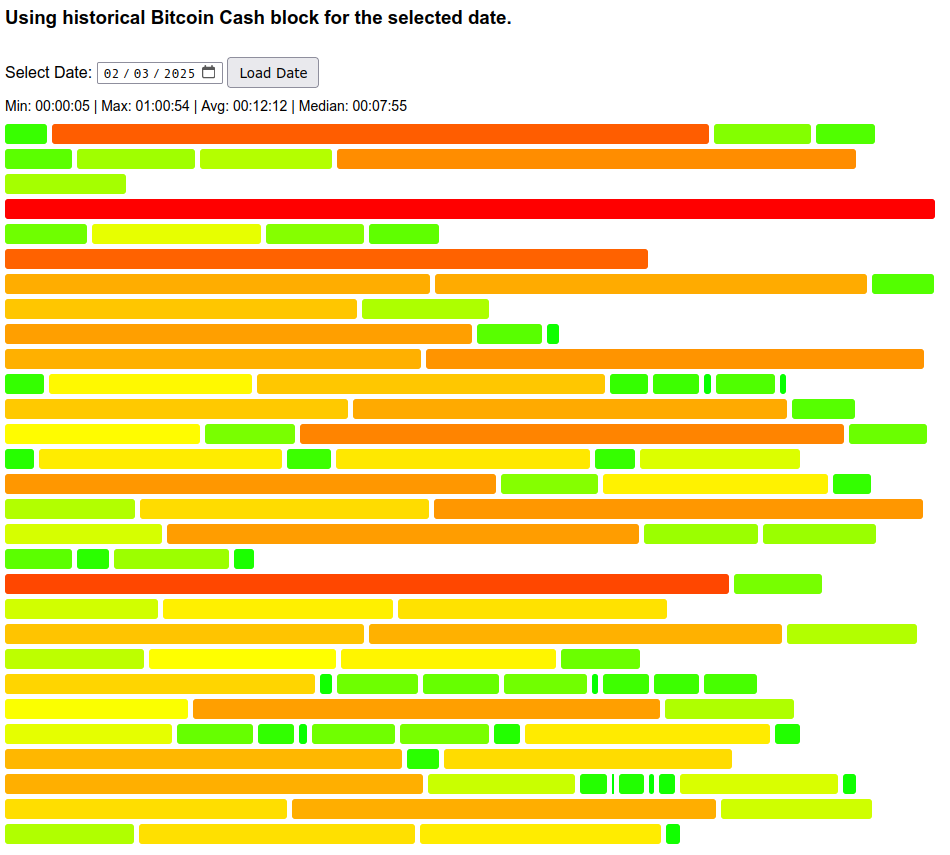
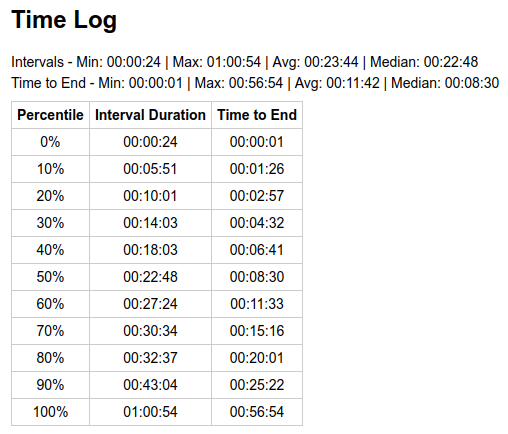
The distribution of individual times was still aligned well with theoretical for the matching average.
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | (case 732s average) | |
| 0.7%* | 00:04 | 00:05 |
| 10% | 01:03 | 01:17 |
| 20% | 02:14 | 02:43 |
| 30% | 03:34 | 04:21 |
| 40% | 05:06 | 06:14 |
| 50% | 06:56 | 08:27 |
| 60% | 09:10 | 11:11 |
| 70% | 12:02 | 14:41 |
| 80% | 16:06 | 19:38 |
| 90% | 23:02 | 28:05 |
| 99.3%* | 49:37 | 60:32 |
* 1 block per day (1/144 = 0.7%)
Block Reward Halving (ASERT)
What about halving? It should have impact equivalent to a 50% price drop.
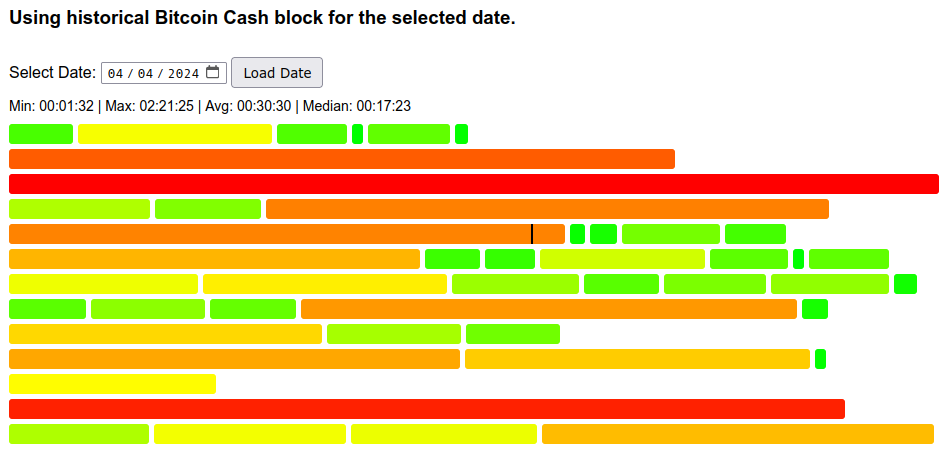
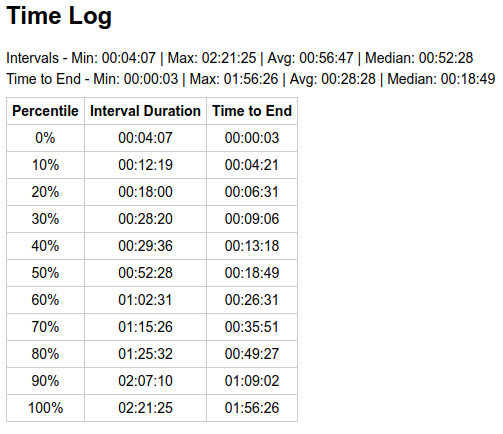
Looks like, on the 1st day, it was more pronounced than anticipated, indicating miners played it safe and removed (or moved to BTC) more hashpower than 50%. The distribution of individual times was still aligned well with theoretical for the matching average, despite the small sample size (47 blocks for that day).
| likelihood | of waiting less than | |
|---|---|---|
| (case 600s average) | (case 1830s average) | |
| 0.7% | 00:04 | 00:13 |
| 10% | 01:03 | 03:13 |
| 20% | 02:14 | 06:48 |
| 30% | 03:34 | 10:53 |
| 40% | 05:06 | 15:35 |
| 50% | 06:56 | 21:08 |
| 60% | 09:10 | 27:57 |
| 70% | 12:02 | 36:43 |
| 80% | 16:06 | 49:05 |
| 90% | 23:02 | 70:14 |
| 99.3% | 49:37 | 151:20 |
* 1 block per day (1/144 = 0.7%)
I think this is the only case where our share in total sha256d haspower would matter. Thankfully such events only happen once every 4 years. 
What Does This Mean for The CHIP?
Nice thing is that extremes scale with target block time, what is now 0.5 to 30min range (90% of waits) could become 0.05 to 3min by reducing the target/average time to 1min, and impact of the next halving would be increased to 0.15 to 9min waits for a day or two (assuming 1/3 hashpower drop like last time).
Impact due to price/hashrate volatility would be barely noticeable, since a 20% move would have just 12 seconds impact on the average (as opposed to 2 minutes now).
3 Likes
It’s not just AMMs, it is any public-use contract where there could be a significant number of concurrent users - such contract UTXOs have a chance of accidental double-spends and only 1 transaction chain will get through.
Yup, 0-conf is a must for brick and mortar, but for it to be safe the user must be spending a confirmed UTXO, rather than have unsafe 0-conf dependencies (like P2SH). Unless you were trading on a DEX while waiting in cashier line, you should have some confirmed UTXOs in your wallet, ready for safe 0-conf use
4 Likes