Should we add mutation tracking to the Bitcoin Cash VM?
Preface: I consider the benefits lost by mutation tracking to be less than 1% of the value of the Functions CHIP. If after more discussion this topic remains the source of uncertainty, I plan to merge the “take 3” mutation-tracking PR for 2026, provided it’s widely considered temporary/removable.
Even with mutation tracking, native functions in 2026 would be hugely valuable:
- Short-term: native functions make immediate use cases practical to implement in wallets (e.g. Quantumroot, @albaDsl’s new Haskell-based DSL projects, elliptic curve math, etc.).
- Medium-term: native functions enable far more ambitious contract projects: on-chain STARK verification, WASM-to-CashVM compilers, a Rust-to-CashVM toolchain, etc. These kinds of technically-difficult, frontier projects are more likely to spin off advanced development, audit, and formal verification tooling. Simpler projects (in terms of raw contract complexity) often can’t justify the costs of building new tools vs. one-off development and reviews, but a frontier of ambitious projects is precisely what the BCH contract ecosystem needs to level up our development and audit tooling (discussed below).
My primary concern with mutation tracking is not that it prevents function factories, but rather that it is dead weight in the protocol – useless complexity of a kind that is rarely fixed. In my review, mutation tracking:
- Slightly increases per-operation VM overhead.1
- Adds meaningful new testing surface area and edge cases in VM implementations.2
- Prevents some meaningful contract optimizations (up to ~30% larger transaction sizes for math and crypto-heavy use cases).3
- Prevents some potential simplifications in compilers and tooling.4
- Fails to improve practical contract security, and likely makes it worse (though not as badly as today’s complete lack of native functions).5
There’s nothing good in this list, but there’s also nothing terrible.
With mutation tracking, contract authors who might have otherwise used one of the banned simplifications or optimizations (described below) will shrug their shoulders and move on, the VM might forever retain the minor additional overhead, node implementations will add all the unnecessary test cases, and the ecosystem may gradually evolve cult-like excuses for the presence of mutation tracking. (Historical example: “it’s safer without loops!”).
Again, I’m willing to accept this fate if it enables native functions. At the very least, I hope this deep-dive will minimize the likelihood that mutation tracking remains permanent protocol debt.
First, some background:
Importance of native functions
The costs/losses of mutation tracking are negligible compared to today’s waste and friction caused by BCH’s lack of native functions. Even with mutation tracking, native functions would improve privacy and auditability of contracts, enable significant growth in contract ecosystem tooling, and make important use cases far more practical.
Status quo: less efficient & harder to audit contracts
On one level, even without the Functions CHIP and regardless of mutation tracking, it is practical today for contract authors to “cut themselves” (and their users) with any amount of metaprogramming within atomic transactions (and of course, covenants – an already-common kind of contract which dynamically “writes the code” of the next output), but as described in the earlier example, useful applications are:
-
Harder to implement at the wallet level – requiring specialized UTXO management code with non-trivial async behavior and network-based lag/error states.
-
More prone to privacy leaks – by otherwise-unnecessary UTXO management, which leaks timing information about wallet synchronization and any other observable characteristics of that management (helping attackers cluster activity by wallet vendor, wallet configuration, and individual user).
-
Harder to secure/audit because native functions remove several attack vectors that must otherwise be defended: without intentional, contract-implemented protection, an attacker can grief applications by racing the user’s wallet to spend sidecar UTXOs and/or malleate transaction unlocking bytecode in either the invoking or executing input. Contract authors and auditors currently need to deeply understand and carefully prevent these attacks only because our VM requires the multi-input indirection (more on that later).
Ecosystem impact of native functions
The code simplification and transaction size reductions made possible by native functions are widely applicable across BCH’s contract ecosystem, but they’re especially critical for very ambitious projects (post-quantum vaults like Quantumroot, on-chain STARK verification, WASM-to-CashVM compilers, a Rust-to-CashVM toolchain, etc.). @albaDsl’s work is another example of such tooling already being built and put to use in elliptic curve multiplication and even the TurtleVm demo of CashVM running inside CashVM.
The development of such ambitious projects would also pay dividends to the wider BCH contract ecosystem in the form of improved compiler, audit, and formal verification tooling – tooling that today’s much simpler BCH contracts can (and do) get by without, but that ambitious projects produce (as a byproduct) to tame complexity and verify correctness.
On the other hand, without support for native functions, it will remain much more difficult to attract talent and investment towards ambitious projects and tooling.
For comparison, note that the lack of native loops is much less harmful to ambitious projects, as loops are already easily unrolled, whereas native functions are far more critical for controlling program complexity. (E.g. @albaDsl first implemented a functions-centric approach, only later added loops, and the project’s elliptic curve multiplication makes heavy use of native functions.)
Case Study: Quantumroot with/without native functions
For example, Quantumroot isn’t broken by “take 3” (ignoring the other costs), and “take 2” could possibly be tweaked to avoid breaking it. On the other hand, it’s hard to see an emulated-functions variant of Quantumroot being widely adopted because:
-
Emulation requires error-prone, specialized UTXO management in wallets (see above example), entailing potentially months or years of additional integration work when taking backlogs into consideration vs. the published Quantumroot code and test suite, which can likely be implemented in weeks by some wallets, and possibly even days by Libauth-based systems. (In the future, implementations could even be measured in hours if wallet engines support directly importing audited wallet templates – the Quantumroot developer preview already includes all LM-OTS quantum-signing code implemented in CashAssembly for this reason.)
-
Privacy leaks from additional UTXO management would be far more likely without native functions (see below),
-
Transactions would require double the inputs (plus additional emulation and anti-malleation code) – so even pre-quantum transactions would be ~2-3x more expensive than today’s typical P2PKH wallets.
The above means that even if all of the additional, unnecessary work (esp. the unnecessary UTXO management code in supporting wallets) were done to roll out an “emulated-functions Quantumroot”, BCH’s practical capacity for simple quantum-ready, Schnorr-based transactions would be as if we cut the base block size to between 11MB and 16MB, with users paying 2-3x today’s single-signature transaction fees.
Note that these numbers analyze only typical Schnorr spends in the pre-quantum spending path. The losses here are 100% silly overhead from BCH’s lack of native functions (see above example) – without counting any post-quantum bytecode or signatures.
On the other hand, the existing, native-functions-based Quantumroot is already byte-length-competitive with P2PKH and additionally supports cross-input aggregation, so the corollary is that native functions enable quantum-ready capacity, today, as if the base block size were 32MB to 37MB, where the higher end is achieved by 15% smaller sweeps per-additional-UTXO than P2PKH.
These gains are achieved in an end-to-end complete contract system and supporting test suite, where final wallet implementations are waiting only on network support for the Functions, P2S, Loops, and Bitwise CHIPs.
For comparison, the Jedex proof of concept was released without a market maker implementation, awaiting emulation of BCH’s now-activated (May 2025) BigInt capabilities. As of May 2025, Jedex could now be made production ready without emulation, but the effort would require substantial additional development, testing, and verification.
In contrast, Quantumroot’s contracts are fully specified, optimized for deployment, pass RFC 8554 (and NIST-adopted) test vectors, covered by a fuzzing test suite, and already undergoing audits. I also plan to provide production-ready, open source integration tooling (via Libauth) enabling Quantumroot vaults in any integrating BCH wallets, targeting release in May 2026.
BCH quantum-readiness
From a practical perspective, the only 2026 CHIP that is important for initial rollout of Quantumroot is the Functions CHIP.
The Functions CHIP is the only 2026 CHIP used by the “quantum-wrapper”, and therefore the only CHIP considered in the above comparison – significant wallet implementation complexity, ~2-3x higher fees/bandwidth, regardless of mutation tracking (“take 3” or a modified “take 2”).
While the other CHIPs (P2S, Loops, and Bitwise) simplify the post-quantum spending paths, the “quantum-wrapper” is already designed to allow sweep-free upgrading of those post-quantum paths, meaning that even if P2S, Loops, and Bitwise weren’t to lock-in for 2026, quantum-ready wallets could still begin deployment in 2026 – without emulation-based technical debt in wallet UTXO management and on-chain contracts.
Because the post-quantum spending paths are sweep-free, such “Functions CHIP-only” wallets would even be able to incrementally adopt the additional post-quantum efficiencies made possible by P2S, Loops, and Bitwise over future years with just one, privacy-nonce-protected UTXO migration – without sweeping or otherwise leaking the privacy of each user’s vault UTXOs. (For a deeper dive, see BCH Tech Talk: Intro to Quantum-Ready Vaults using Quantumroot.)
Quantum-readiness without a “Quantum” upgrade
I want to highlight here again that Bitcoin Cash is uniquely positioned among top cryptocurrencies, by our high-performance contract system, to roll out fully-quantum-ready wallets in 2026, without committing to a specific, “quantum-ready” signature algorithm and/or corresponding upgrade.
Beyond this specific value for quantum-readiness, native functions are also widely useful for simplifying and making algorithms more compact and readable, meaning the Functions CHIP offers wide value across the entire contract ecosystem, regardless of Q-Day timelines.
With that background on the value of native functions, let’s examine mutation tracking specifically:
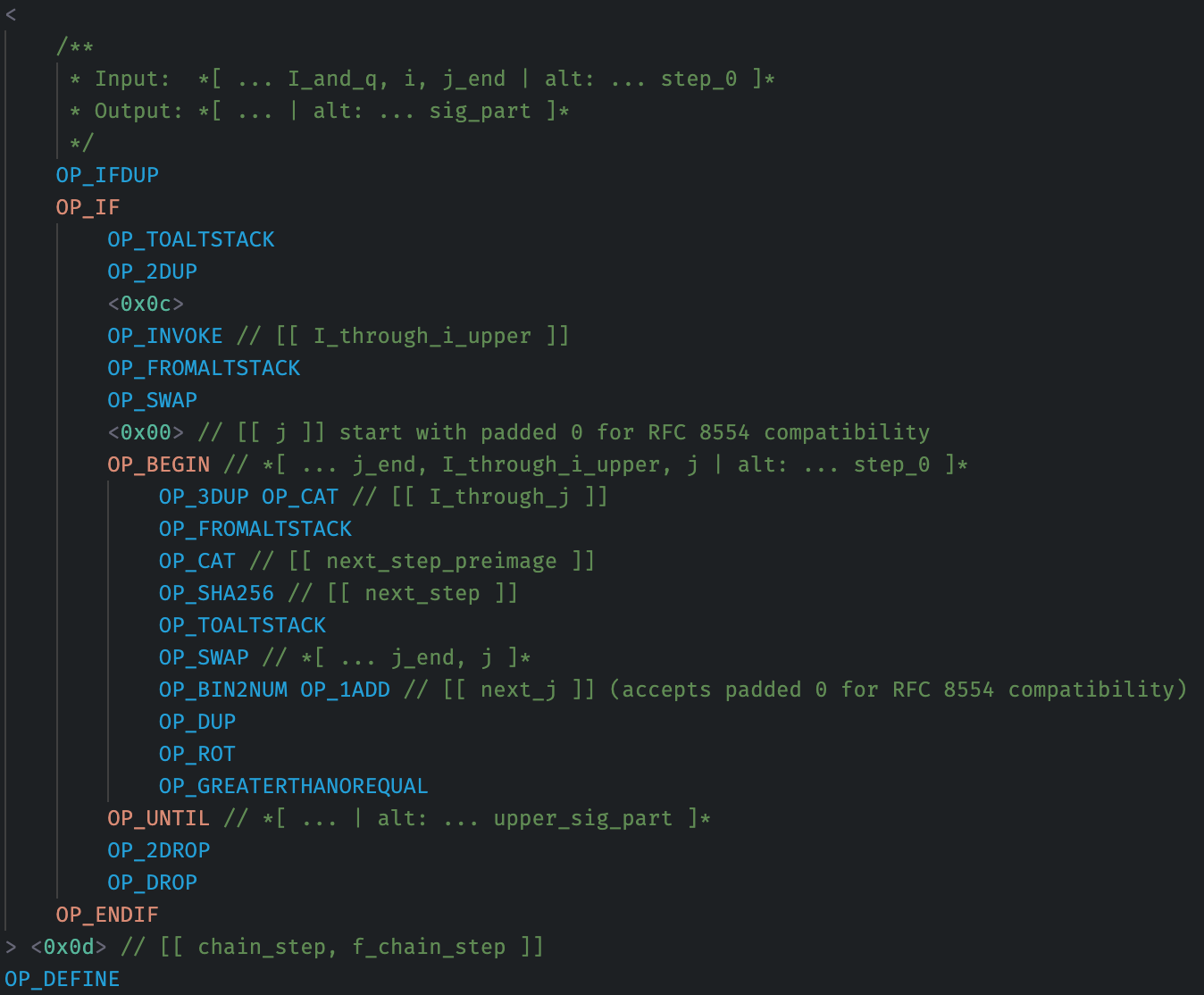
Defining mutation tracking
Below I take mutation tracking to cover both “take 2” and “take 3” – any addition to the VM which attempts to track stack items as “safe” or “unsafe” for use in function definitions, where the underlying intention is to prevent use of function factories (“code that writes code”) within a single input.
Protocol complexity & overhead of mutation tracking
Mutation tracking requires:
-
Additional complexity and testing surface for VM implementations – new edge cases and consensus code spread across many opcodes,
-
Slightly increased per-operation VM overhead, reducing the VM’s performance potential on heavy applications. (Think of it as up to ~1 opCost in new, real-world overhead.)
Performance is a major competitive advantage of Bitcoin Cash’s VM vs. EVM, Solana, and other contract ecosystems, so I take losses here very seriously (even if relatively small at present scale/speed).
Bitcoin Cash could soon have the most capable VM of any major, decentralized cryptocurrency; I’ll note that e.g. Solana’s VM appears to be incapable of supporting 128-bit post-quantum vaults like Bitcoin Cash’s Quantumroot.
The widely publicized Solana Winternitz Vault is an impressive (in the engineering sense) workaround for Solana’s more limited contract capabilities vs. Bitcoin Cash. The Solana vault requires unusual modifications to well-reviewed cryptography, and it still comes up short of Quantumroot’s standards-based, SHA256-only, 128-bit post-quantum security strength.1
1. This announcement describes the need for non-standard cryptographic techniques on Solana. The GitHub repo claims 112-bit post-quantum security strength.
Quantumroot implements RFC 8554 (also adopted by NIST SP 800-208), and even spends a few extra bytes in the (hidden, off-chain) post-quantum paths to maintain precise compatibility.
Aside: also note here that BCH’s SHA256 proof-of-work consensus is well understood to be ready for Q-Day (and maybe decades beyond), while nearly all Proof-of-Stake protocols today are quantum-vulnerable (and the “quantum-ready” protocols have made serious tradeoffs to claim it as a feature). BCH seems to be at-or-near #1 in post-quantum readiness, especially among top cryptocurrencies.
Ecosystem impact of mutation tracking
As mentioned above, perhaps the most visible impact of mutation tracking is the additional VM complexity and testing surface area. (Though our cross-implementation VM testing suite makes this work easier to complete and verify.) Beyond VM implementations, there’s negligible potential impact to any existing wallets, ecosystem software, contract authors, or end users – regardless of mutation tracking.
As we’ll see below, mutation tracking bans several simplifications/optimizations which primarily benefit relatively-complex contracts (up to ~30% transaction size savings); simpler contracts might save only a few bytes in rare cases. Among those more complex cases, function factories also offer some meaningful compiler and audit tooling simplifications by enabling definition of off-stack constants (see below).
Overall, mutation tracking appears only to reduce the practical usability, safety, and efficiency of BCH contracts, while meaningfully increasing protocol complexity. In these situations, my strong preference is to maximize protocol simplicity – in this case, by not adding mutation tracking to the consensus code.
Of course, if a contract/tooling developer wants some aspect of the mutation tracking behavior in their own systems, they can always add it themselves, limit use of native functions to easily verified approaches, and/or ignore native functions altogether. Plenty of tooling already ignores existing opcodes. E.g. OP_DEPTH has been prominently criticized by contributors to Miniscript and remains unused by that compiler. (Quantumroot coincidentally makes use of OP_DEPTH to minimize cross-input and cross-address aggregation, but BTC’s MINIMALIF micro-optimization for Lightning Network breaks the construction on BTC.)
I’ll now try to examine how mutation tracking is either irrelevant or counterproductive to practical contract security:
Mutation tracking makes contracts more complex, less efficient, and harder to audit
I’ll walk through examples to convey the following points:
-
Function factories would immediately enable more strategies for stack-scheduling-naive compilers to safely compile BCH contracts (esp. compilers that weren’t designed specifically for BCH, like zkVMs, Rust, etc.). Precomputed tables are easy to show without a specific compiler context, since they’re useful even to hand-optimized contracts, but the underlying idea – off-stack constants – can both simplify compilation (i.e. adding support for BCH to other compilers) and make the resulting contracts easier to audit (both manually and via tooling).
-
Function-based precomputed tables offer a significant opCost reduction vs. stack-based tables due to reduced stack juggling in hot loops (reducing transaction sizes by up to ~30% for heavy use cases).
-
We cannot possibly “ban metaprogramming”, even if that were a sensible goal – metaprogramming is easy to do today (and remember, today’s status quo offers the maximum “rug-deniability”: you have to use arcane multi-input workarounds to even emulate functions today, with plenty of little footguns that can be “missed” by audits.)
-
Pretending to ban metaprogramming (with mutation tracking via “take 2” or “take 3”) adds meaningful protocol complexity. In my opinion, mutation tracking is an anti-feature serving only to hurt practical security and usefulness.
First, to expand the earlier precomputed tables examples:
The problem with stack-based constants
The root problem with stack-based constants (and especially precomputed tables) is that the stack mutates while you’re working.
For precomputed tables, that means your “table references” get deeper or shallower at various points in your contract evaluation, and you have to interlace tracking of that offset with the actual algorithm.
Sometimes that offset is fixed and can be “baked-in” to the contract, while sometimes it’s dynamic, making complexity and performance even worse.
In practice, this means that mutation tracking would prevent contract/compiler developers from using function factories in specific cases to simplify compilers, minimize dead weight in hot loops, and simplify compiled contract code. With mutation tracking (especially with loops), complex contracts will remain meaningfully harder to develop and audit because every part of today’s contracts must share and mutate two giant stacks.
Precomputed tables optimize opCost
Before we go further, it’s important to understand that precomputed tables are aimed at optimizing for performance, i.e. opCost: to make the code more efficient rather than (directly) to make it denser.
For many heavy math and cryptography algorithms (post-quantum crypto, zero-knowledge proof verification, homomorphic encryption, financial market scoring for large sets of multidimensional prediction markets, etc.), the real bottleneck to practical implementation is opCost – making opCost the difference between a simple, low-fee transaction or a messy series of expensive transactions.
Of course, this is an intentional and important protection for the network: the opCost density limits ensure that every transaction either validates quickly or is rejected. Essentially, the network is demanding that all contracts be at least as-fast-to-validate-per-byte as “payments-only” transactions.
So: optimizations which help contracts lower net opCost can ultimately help to reduce transaction sizes in these heavy use cases – enabling their greater throughput on BCH.
Optimizing code length (high opCost)
To demonstrate for the bit-reversal example, here’s one approach to optimization – for each byte, the contract could perform the below operations. Note that this is already fairly opCost-optimized vs. a naive 8-iteration loop over each byte:
// test: <0x12>
OP_DUP <1> OP_LSHIFTBIN <0xaa> OP_AND
OP_SWAP <1> OP_RSHIFTBIN <0x55> OP_AND
OP_OR
OP_DUP <2> OP_LSHIFTBIN <0xcc> OP_AND
OP_SWAP <2> OP_RSHIFTBIN <0x33> OP_AND
OP_OR
OP_DUP <4> OP_LSHIFTBIN <0xf0> OP_AND
OP_SWAP <4> OP_RSHIFTBIN <0x0f> OP_AND
OP_OR
// check: <0x48>
This minimizes contract length by eliminating the initial overhead of the precomputed table, but it has an opCost of 3330 per bit-reversed byte (excluding any OP_INVOKEs, so we’re generously assuming it’s used in only one tight loop).
Optimizing OpCost (low opCost)
On the other hand, a precomputed table can unpack or read from a hard-coded table, paying some fixed upfront opCost and then minimizing the per-byte opCost (by eliminating all shifts/math per byte):
// test: <0x12>
OP_INVOKE // internal: <0x48>
This has an opCost of only 201 per byte, consisting almost entirely of base instruction cost (OP_INVOKE plus the internal push). This is both a ~15x improvement and much more “close to the metal” (within the CashVM sandbox) – minimizing VM interpreter revolutions.
These gains add up across large and heavy computations, reducing or eliminating the need to pack input data for opCost budget, and ultimately leading to less waste and smaller transaction sizes.
For performance-sensitive use cases, this can easily be the difference between practical and impractical.
So the takeaway: for these precomputed table examples, the difference between “this use case works” and “this hits VM limits” is actually determined by invocation-site opCost. And by extension, since longer inputs give you more compute, in these cases the real bottleneck on contract length is the opCost of invocation sites.
Comparing to stack-based deep picking
Note that the above doesn’t yet explain why some contracts benefit from function-factory-based precomputed tables (since you can still deep PICK from a stack-based table), but now we’re looking at the right numbers – we want to minimize invocation-site opCost.
Again, the root problem here is that our “table references” shift while we’re working, so we have to interlace tracking of stack mutation with the actual algorithm.
This stack juggling makes contracts more complex, adds a lot of wasteful indirection (further from “bare metal”), and it also makes contracts much harder to write and audit.
Also, because such stack juggling requires specialized stack-aware compiler algorithms, it’s also a serious barrier to entry for projects/compilers that might otherwise be able to port code or add BCH as a drop-in compilation target.
Some real juggling examples:
Level 1 with function factories
For reference, here’s a reasonable byte-by-byte bit-reversal permutation function optimized with a function-factory-produced precomputed table:
// ... Setup table ...
// Bit-reverse binary array:
<> // [[ output_slot ]]
<0x01020304> // [[ input ]]
OP_REVERSEBYTES
OP_BEGIN
<1> OP_SPLIT OP_SWAP // Get next byte
OP_INVOKE // Bit-reverse it
OP_ROT OP_CAT // Append to output_slot
OP_SWAP // Place remaining bytes back on top
OP_SIZE OP_NOT OP_UNTIL // Loop until bytes are gone
OP_DROP // out: 0x8040c020
// No tear-down required, stack is clean
The hot loop here has an opCost of ~1100 (including the OP_UNTIL and invoked push). The precomputed table is directly referenced like a constant, no additional manipulation of each byte needed, just split and invoke.
Level 1 without function factories
Now for a best case scenario without function factories: references are only used in one spot, and the stack isn’t changing depth under them. This still requires the contract to hard-code depth calculation math and stack-juggling before each deep pick, e.g.:
// Setup stack-only precomputed table:
// Initially a few bytes cheaper, but increases invocation-site opCost
<0x008040c020 /* ... */ > // endianness reversed for stack-juggling efficiency
OP_BEGIN
<1> OP_SPLIT
OP_SIZE OP_NOT
OP_UNTIL
OP_DROP
// Bit-reverse binary array:
<> // [[ output_slot ]]
<0x01020304> // [[ input ]]
OP_REVERSEBYTES
OP_BEGIN
<1> OP_SPLIT OP_SWAP
<2> OP_ADD // <- Breaks if this code's depth offset changes
OP_PICK // (Copies from up to 257 deep in the stack)
OP_ROT OP_CAT
OP_SWAP
OP_SIZE OP_NOT OP_UNTIL
OP_DROP // out: 0x8040c020
// Later stack clean-up (at contract end):
OP_TOALTSTACK
OP_BEGIN
OP_DROP
OP_DEPTH OP_NOT
OP_UNTIL
OP_FROMALTSTACK // out: 0x8040c020
This stack-based implementation is:
-
Not safely portable – you cannot safely include this code in a function and execute it in two code locations as the depth offset (here,
2) must match. You need to either A) duplicate the code and modify the hard-coded indexes to match the expected deep-picking depth offset in the new code location, or B) parameterize the function with the stack-depth offset to use (i.e. additional juggling in the hot loop)
-
Internally brittle – if the logic in this loop changes slightly, the stack depth at the referencing location might increase or decrease by one. This is particularly messy for compilers attempting to optimize the loop – it might be more efficient to reference the table earlier or later, and the compiler might need to try a few options, between which the precise offset will be different based on the juggling.
-
Less efficient – managing the offset inside the hot loop adds at least 1 base instruction cost (total opCost: ~1200), including an OP_ADD (or OP_SUB) numeric operation, which is fundamentally more costly than stack operations (meaning this code is another unnecessary step removed from “bare metal” performance, implying it would probably retain more opCost even if some future upgrade lowered base instruction cost simply because the OP_ADD (+ numeric interpretation + re-encoding for the stack) is one of the most costly parts of this loop on real hardware).
Level 1 comparison with vs. without function factories
I think there are substantial contract efficiency and safety benefits of compilers being allowed to use metaprogramming/function factories here:
-
The metaprogramming approach is easier to prove correct – even a compiler that doesn’t have “deep CashVM support” can safely translate code into fixed snippets at each location. The depth offset of the table doesn’t need to be tracked, and movements in the code won’t cause unexpected behavior.
-
There’s also substantial performance/opCost improvement – a “less smart” compiler can do up to 10% better in these spots than the smartest-possible, CashVM-focused compiler, even though the compiler is more “stack-scheduling naive” – perhaps it’s just filling in cookie-cutter “loop templates” that are well-reviewed, dropping them into the compiled output at the right spot, and not bothering with any sort of contract-wide stack scheduling optimization (just directly translating code in source order).
Note again, the CashScript compiler today relies heavily on deep stack picking and simple find/replace rules (no “optimal” stack scheduling), so CashScript is an example of one of those “less smart” compilers right now.
CashScript could probably use function factories to more safely implement some high-language features (esp. loops referencing constant data structures) in ways that produce much more auditable code artifacts, and such constructions would even leapfrog (in performance/contract length) the efficiency gains of a far-harder compiler migration from deep-picking to optimized stack scheduling.
Stepping back: I think this observation is especially relevant for non-BCH-native toolchains like zkVM projects, LLVM, AssemblyScript, Rust, etc. where the compiler could be extended to add BCH as a target.
Metaprogramming gives these projects some additional, immediate flexibility to implement the dynamically assigned constants they expect, without necessarily requiring deep-picking and stack juggling support. Even if the resulting bytecode is a little less byte-efficient than “perfectly-optimized CashVM bytecode”, if function-factory-based strategies are sufficiently-similar to some compilation path currently in use, it becomes much easier to re-use compiler infrastructure from other targets, dropping in simple setup/teardown blocks to smooth over any differences. (Note, 99% of this value is probably possible just with native functions regardless of mutation tracking, but any edge cases could make a huge difference: “yes, you can just port that exactly, use this snippet and it will work how you expect” vs. “no, we deliberately made metaprogramming more obscure to use, you’ll have to either implement deep stack tracking or fiddle with these multi-input workarounds.”)
Now let’s make this example one level more complex:
Level 2 with function factories
Pattern: an algorithm begins with an array, performs computations on each item by referencing a previously-computed value, ultimately reducing the array into one result (e.g. “XOR the values”).
Note that this is a pattern for which the depth offset of the data changes at each iteration of the loop. In this case, the pick-depth is simply one-item shallower on each iteration.
Function-factory-based table, the reduction step:
// ... Setup table ...
<1> OP_TOALTSTACK // [[ alt: output_slot ]]
<0x01> <0x02> <0x04> // start with an array of values
OP_BEGIN
OP_INVOKE // Lookup next value in precomputed table
OP_FROMALTSTACK
OP_XOR // Reduce it into output_slot
OP_TOALTSTACK
OP_DEPTH OP_NOT // Loop until items are consumed
OP_UNTIL
OP_FROMALTSTACK // out: 0xe0
Hot loop opCost: ~800 (including the OP_UNTIL and invoked push).
Level 2 without function factories
Here’s what it looks like to track a stack-based precomputed table’s offset from within this logic:
<0x20> <0xc0> <0x40> <0x80> <0x00> // setup tiny stack-based table (order must be reversed)
<0x00> OP_TOALTSTACK // [[ alt: output_slot ]]
<0x01> <0x02> <0x04> // start with an array of values
OP_BEGIN
OP_DEPTH <5> OP_SUB // [[ remaining_items ]]
OP_TUCK // Save for OP_UNTIL
OP_ADD // [[ next_value_stack_offset ]]
OP_PICK // Deep pick from table
OP_FROMALTSTACK
OP_XOR // Reduce it into output_slot
OP_TOALTSTACK
<1> OP_LESSTHANOREQUAL // Loop until last item
OP_UNTIL
OP_BEGIN OP_DROP OP_DEPTH OP_NOT OP_UNTIL // clear table
OP_FROMALTSTACK // out: 0xe0
Hot loop opCost: ~1100, a 37.5% increase, meaning that for opCost constrained applications (heavy math/crypto), mutation tracking could increase such transaction sizes by up to 37.5%, in addition to the substantial increase in code complexity.
In this example again, location-dependent stack information is baked into the code, making this less portable, more brittle, and/or less efficient – now including both an OP_SUB and an OP_ADD exclusively for stack juggling purposes, meaning this snippet is also two relatively-heavy (numeric) operations away from “bare metal” performance.
There are many ways to refactor this code (see: Turing completeness) to reference the precomputed table without stack depth changes, but these also increase opCost in the hot loop and cloud the algorithm with CashVM-specific implementation details – meaning more BCH-specific compiler work and/or hand optimization effort. (For example, to avoid the stack depth change, you could first iterate over the items and copy values from the precomputed table – in order – to the altstack, then in another pass, pull them one at a time from the altstack to consume both.)