
Also relevant to this topic: CHIP-2025-05 Functions: Function Definition and Invocation Operations - #20 by bitjson
6 Likes
Here is a more generalized (but untested!) version of the same concept
Imagine a redeem script of the form
OP_DUP
OP_HASH256
<hash of contract logic>
OP_EQUAL
OP_IF
<1>
OP_DEFINE
<1>
OP_INVOKE
OP_ELSE
<0>
OP_INPUTBYTECODE
// .. Series of OP_SPLITS to get the data corresponding to the first element after the redeem script of input#0
OP_DUP
OP_HASH256
<hash of contract logic>
OP_EQUALVERIFY
<1>
OP_DEFINE
<1>
OP_INVOKE
OP_ENDIF
This will act as a wrapper where either the actual logic of the contract is pushed on the stack on the current input or is supplied on the first input letting someone spend one or many UTXOs of the same (long) contract but only need to supply it once. It’s possible to only have the 32 byte hash once in the redeem script by juggling that value on stack (but I did not do that for clarity).
3 Likes
This is such a good post. I am still processing it, but it makes sense to me that since BCH is already Turing complete the “code that writes code” issue isn’t a Rubicon we’re crossing with functions, and that “static analysis” also isn’t a big need (as seen in BTC having far poorer tooling than ETH - raising available dev power and capability actually makes things SAFER because you get a bigger network effect & smarter devs who build better tooling with more funding in a bigger ecosystem).
Seems bullish for Functions.
3 Likes
Along with this:
I want to highlight again Use of Stack-Based Parameters from the CHIP (since May 23), specifically:
However, by preventing function definition and/or invocation from accepting data from the stack (i.e. directly using the results of previous computation), this alternative would complicate or prevent transpilation of complex computations from other languages (where no such limitations are imposed) to Bitcoin Cash VM bytecode. Instead, many branch table, precomputation table, and similar operation cost-reducing constructions would need to be “unrolled” into expensive conditional blocks (e.g.
OP_DUP <case> OP_EQUAL OP_IF...OP_ENDIF OP_DUP <case> ... OP_EQUAL), wasting operation cost and significantly lengthening contracts.
4 Likes
I deleted my post because my example was kind of contrived. Sorry for the noise!
Thank you to @cculianu, @MathieuG, and @emergent_reasons for discussions that prompted me to work on building out some metaprogramming examples, i.e. “function factories”.
Precomputed tables (see above excerpt from the CHIP) are the strongest example I’ve found so far.
Precomputed tables are useful for a variety of both financial and cryptographic algorithms, and there are two levels on which metaprogramming can reduce the resulting contract lengths:
- Wallet-Side Precomputed Tables – tables which are precomputed “wallet-side” and encoded in the signed transaction.
- Validation-Unpacked Tables – tables which are even cheaper to unpack during evaluation than they are to directly encode in the transaction.
To use a precomputed table, contracts can simply define a function which pushes the precomputed value at an expected index. (For multiple tables, use addition or bitwise operations to start the next table at a different function index.) When you need a precomputed value, invoke the index.
Wallet-Side Precomputed Tables
The intuition for this construction is that many small push instructions end up inflating transaction sizes more than longer pushes.
From Quantumroot “Appendix B: On CashAssembly”:
Given loops, longer stack items tend to be better for encoding: a 2,144-byte quantum signature only requires 3 bytes of overhead to encode with OP_PUSHDATA2, but it takes 67 bytes of overhead to push each signature component of a w=4 LM-OTS signature.
This effect is even more pronounced on common precomputed tables: without metaprogramming, a 256-item table (e.g. for opCost efficient bit-reversal permutation) wastes at least 1KB on encoding overhead. With metaprogramming, that comes down to ~10 bytes:
Without metaprogramming
<<0x80>> <0x01> OP_DEFINE // (encoded: 0x0201805189)
<<0x40>> <0x02> OP_DEFINE // (encoded: 0x0201405289)
<<0xc0>> <0x03> OP_DEFINE // (encoded: 0x0201c05389)
// ... (total: 256 entries)
Notice each line duplicates 0201, increments a number, and duplicates 89. That’s 4 bytes of overhead per table item, wasting of ~1024 bytes in overhead, in addition to the sum of the precomputed item lengths (here, 256 bytes). Total: ~1280 bytes.
With metaprogramming
<0x8040c0> // encoded: 0x4d00018040c0 ... (total 259 bytes)
// Then OP_SPLIT each byte and define it as a push instruction (using loops + function factories)
With metaprogramming, we’re down to only 259 bytes for the precomputed table contents, plus a few dozen bytes to encode the function factories. Total: ~300 bytes.
Validation-Unpacked Tables
Above we’ve already saved 1KB, but we can do better: instead of hard-coding the remaining 256 byte constant in the contract, we can unpack it with some cheap math. For some precomputed tables, the required opCost will rule out validation-time unpacking, but for others (like a bit-reversal lookup table), it could bring the encoding cost down even further.
Potential change: BIN vs. NUM identifiers
While working on this, I realized that we could save a byte in many of these meta-programming cases by eliminating the numeric casting requirement for function identifiers – a BIN rather than NUM.
Numeric identifiers would remain the optimal choice for most contracts (allowing single-byte pushes via OP_0 through OP_16), and even constructions relying on numeric-ness of function identifiers (e.g. iterating over a list of functions) would continue to work as in the CHIP today.
I’m going to continue reviewing this potential change, then I’ll open a PR to update that rationale section and possibly make the correction. (I’ll also add “Takes 2 & 3” to the reviewed alternatives.)
A final note
I recognize that proposing any kind of change to the Functions CHIP will reduce certainty about it’s readiness to lock-in for 2026. That’s OK with me. The protocol is forever – I would prefer any CHIP be delayed a year rather than a flaw be prematurely locked-in. (Even if the flaw is a 1-byte inefficiency in metaprogramming use cases.)
Thanks again to all the reviewers so far, and if you see something in the CHIP that isn’t clear, please don’t hesitate to ask.
4 Likes
Obvious question: wouldn’t the above be faster and couldn’t you just do the above today… if you just pushed the individual bytes to the stack individually? In other words the 256-byte array would be faster just if it were bytes on the stack… which you can use OP_PICK to select …?
As for making the function identifier a byte blob – would be fine. Might be a good idea to keep it constrained to some maximum-length byte string e.g. 8 bytes max or something.
1 Like
Pushing one byte of data requires 2 bytes of code:
0x01 <byte>
So pushing 256 bytes comes in at 512 bytes of code compared to 276 bytes in the “metaway”.
Getting a value from the stack is the same:
<index> OP_PICK vs <index> OP_INVOKE
By pushing to the stack you’d also need to drop it all before the script terminates (just a few bytes with loops).
Edit: Just realized that “do the above today” might include the use of loops at which you seem to be right. You could loop and split in the same way but instead of doing OP_CAT with 0x01 for each byte and then OP_DEFINE just push it on the stack. Should be more efficient (but would probably require a bit more juggling of the stack).
3 Likes
Oh yeah I forgot about that. “Clean stack” rule, of course. Fair point.
Take2&3 restrictions can be cleanly removed in 2027, and if we activate either take 2 or 3, we’d get a year to demonstrate uses and limitations and make a stronger case for 2027.
I’m fine with unrestricted version in 2026, but if other stakeholders can’t be convinced on time, and they’d accept the more limited version, then let’s have it for 2026, and with intention of removing the training wheels in 2027.
2 Likes
Out of curiosity:
If no constraints would be added I assume the identifier can be 10000 bytes (MAX_SCRIPT_ELEMENT_SIZE), which is the same as the actual function being defined.
What would blow up if a script defines 1000 functions of the size 10000 bytes with an identifier of the size 10000 bytes?
Edit: Thought about it and the table would be 100 Gb uncompressed. Implementation-wise only the identifier hash could be stored which would bring it down to 320 Mb in case of 32 byte hashes, but it would incur a hashing operation for each OP_DEFINE/OP_INVOKE.
Edit2: my brain obviously checked out for the weekend early, the numbers are way of.
2 Likes
Well … it would be 1000 * 10kb + 1000 * 10kb = 10MB + 10MB = 20MB. So memory-wise a bit heavy but not terrible (the script interpreter potentially runs 1 interpreter per core so on a 24 core system it could be like 480MB of memory to validate blocks… not terrible but not ideal since it’s mostly wasted space).
The real problem is it would be completely slow to lookup. If you use a hash table you need to hash 10KB potentially just to do 1 lookup. Or if you use a rb-tree like std::map, that’s wasteful too potentially someone can craft identifiers that are the same except for the last byte so you can waste cycles comparing mostly-the-same 10kb blobs over and over again… and with what benefit? LOL.
1 Like
Yes. In all cases now numbers must be minimally encoded, as must be pushes. Otherwise tx malleation would be possible still in BCH, which it is not.
1 Like
Sorry, I meant the “non-canonically-encoded serialization sizes” rule which is enforced by a call to CheckMinimalPush in src/script/interpreter.cpp. The rule makes the meta programming that Jason illustrated a bit more complicated. But, yeah, function evaluation would be subject to the same evaluator flags as the rest of the redeem script.
1 Like
The take 2 and 3 would probably not be needed at all if we have a op-define-verify to go along with the (take 1) op-define.
Which IMOHO is the best of all worlds. Keep things simple by default, allow people to use a “verify” method if they want. As you can tell on the list of opcodes, this is a common design from Satoshi.
I wrote a bit more about how this works on a different thread, please allow me to just link to it instead of copy pasting the text.
Should we add mutation tracking to the Bitcoin Cash VM?
Preface: I consider the benefits lost by mutation tracking to be less than 1% of the value of the Functions CHIP. If after more discussion this topic remains the source of uncertainty, I plan to merge the “take 3” mutation-tracking PR for 2026, provided it’s widely considered temporary/removable.
Even with mutation tracking, native functions in 2026 would be hugely valuable:
- Short-term: native functions make immediate use cases practical to implement in wallets (e.g. Quantumroot, @albaDsl’s new Haskell-based DSL projects, elliptic curve math, etc.).
- Medium-term: native functions enable far more ambitious contract projects: on-chain STARK verification, WASM-to-CashVM compilers, a Rust-to-CashVM toolchain, etc. These kinds of technically-difficult, frontier projects are more likely to spin off advanced development, audit, and formal verification tooling. Simpler projects (in terms of raw contract complexity) often can’t justify the costs of building new tools vs. one-off development and reviews, but a frontier of ambitious projects is precisely what the BCH contract ecosystem needs to level up our development and audit tooling (discussed below).
My primary concern with mutation tracking is not that it prevents function factories, but rather that it is dead weight in the protocol – useless complexity of a kind that is rarely fixed. In my review, mutation tracking:
- Slightly increases per-operation VM overhead.1
- Adds meaningful new testing surface area and edge cases in VM implementations.2
- Prevents some meaningful contract optimizations (up to ~30% larger transaction sizes for math and crypto-heavy use cases).3
- Prevents some potential simplifications in compilers and tooling.4
- Fails to improve practical contract security, and likely makes it worse (though not as badly as today’s complete lack of native functions).5
There’s nothing good in this list, but there’s also nothing terrible.
With mutation tracking, contract authors who might have otherwise used one of the banned simplifications or optimizations (described below) will shrug their shoulders and move on, the VM might forever retain the minor additional overhead, node implementations will add all the unnecessary test cases, and the ecosystem may gradually evolve cult-like excuses for the presence of mutation tracking. (Historical example: “it’s safer without loops!”).
Again, I’m willing to accept this fate if it enables native functions. At the very least, I hope this deep-dive will minimize the likelihood that mutation tracking remains permanent protocol debt.
First, some background:
Importance of native functions
The costs/losses of mutation tracking are negligible compared to today’s waste and friction caused by BCH’s lack of native functions. Even with mutation tracking, native functions would improve privacy and auditability of contracts, enable significant growth in contract ecosystem tooling, and make important use cases far more practical.
Status quo: less efficient & harder to audit contracts
On one level, even without the Functions CHIP and regardless of mutation tracking, it is practical today for contract authors to “cut themselves” (and their users) with any amount of metaprogramming within atomic transactions (and of course, covenants – an already-common kind of contract which dynamically “writes the code” of the next output), but as described in the earlier example, useful applications are:
- Harder to implement at the wallet level – requiring specialized UTXO management code with non-trivial async behavior and network-based lag/error states.
- More prone to privacy leaks – by otherwise-unnecessary UTXO management, which leaks timing information about wallet synchronization and any other observable characteristics of that management (helping attackers cluster activity by wallet vendor, wallet configuration, and individual user).
- Harder to secure/audit because native functions remove several attack vectors that must otherwise be defended: without intentional, contract-implemented protection, an attacker can grief applications by racing the user’s wallet to spend sidecar UTXOs and/or malleate transaction unlocking bytecode in either the invoking or executing input. Contract authors and auditors currently need to deeply understand and carefully prevent these attacks only because our VM requires the multi-input indirection (more on that later).
Ecosystem impact of native functions
The code simplification and transaction size reductions made possible by native functions are widely applicable across BCH’s contract ecosystem, but they’re especially critical for very ambitious projects (post-quantum vaults like Quantumroot, on-chain STARK verification, WASM-to-CashVM compilers, a Rust-to-CashVM toolchain, etc.). @albaDsl’s work is another example of such tooling already being built and put to use in elliptic curve multiplication and even the TurtleVm demo of CashVM running inside CashVM.
The development of such ambitious projects would also pay dividends to the wider BCH contract ecosystem in the form of improved compiler, audit, and formal verification tooling – tooling that today’s much simpler BCH contracts can (and do) get by without, but that ambitious projects produce (as a byproduct) to tame complexity and verify correctness.
On the other hand, without support for native functions, it will remain much more difficult to attract talent and investment towards ambitious projects and tooling.
For comparison, note that the lack of native loops is much less harmful to ambitious projects, as loops are already easily unrolled, whereas native functions are far more critical for controlling program complexity. (E.g. @albaDsl first implemented a functions-centric approach, only later added loops, and the project’s elliptic curve multiplication makes heavy use of native functions.)
Case Study: Quantumroot with/without native functions
For example, Quantumroot isn’t broken by “take 3” (ignoring the other costs), and “take 2” could possibly be tweaked to avoid breaking it. On the other hand, it’s hard to see an emulated-functions variant of Quantumroot being widely adopted because:
-
Emulation requires error-prone, specialized UTXO management in wallets (see above example), entailing potentially months or years of additional integration work when taking backlogs into consideration vs. the published Quantumroot code and test suite, which can likely be implemented in weeks by some wallets, and possibly even days by Libauth-based systems. (In the future, implementations could even be measured in hours if wallet engines support directly importing audited wallet templates – the Quantumroot developer preview already includes all LM-OTS quantum-signing code implemented in CashAssembly for this reason.)
-
Privacy leaks from additional UTXO management would be far more likely without native functions (see below),
-
Transactions would require double the inputs (plus additional emulation and anti-malleation code) – so even pre-quantum transactions would be ~2-3x more expensive than today’s typical P2PKH wallets.
The above means that even if all of the additional, unnecessary work (esp. the unnecessary UTXO management code in supporting wallets) were done to roll out an “emulated-functions Quantumroot”, BCH’s practical capacity for simple quantum-ready, Schnorr-based transactions would be as if we cut the base block size to between 11MB and 16MB, with users paying 2-3x today’s single-signature transaction fees.
Note that these numbers analyze only typical Schnorr spends in the pre-quantum spending path. The losses here are 100% silly overhead from BCH’s lack of native functions (see above example) – without counting any post-quantum bytecode or signatures.
On the other hand, the existing, native-functions-based Quantumroot is already byte-length-competitive with P2PKH and additionally supports cross-input aggregation, so the corollary is that native functions enable quantum-ready capacity, today, as if the base block size were 32MB to 37MB, where the higher end is achieved by 15% smaller sweeps per-additional-UTXO than P2PKH.
These gains are achieved in an end-to-end complete contract system and supporting test suite, where final wallet implementations are waiting only on network support for the Functions, P2S, Loops, and Bitwise CHIPs.
For comparison, the Jedex proof of concept was released without a market maker implementation, awaiting emulation of BCH’s now-activated (May 2025) BigInt capabilities. As of May 2025, Jedex could now be made production ready without emulation, but the effort would require substantial additional development, testing, and verification.
In contrast, Quantumroot’s contracts are fully specified, optimized for deployment, pass RFC 8554 (and NIST-adopted) test vectors, covered by a fuzzing test suite, and already undergoing audits. I also plan to provide production-ready, open source integration tooling (via Libauth) enabling Quantumroot vaults in any integrating BCH wallets, targeting release in May 2026.
BCH quantum-readiness
From a practical perspective, the only 2026 CHIP that is important for initial rollout of Quantumroot is the Functions CHIP.
The Functions CHIP is the only 2026 CHIP used by the “quantum-wrapper”, and therefore the only CHIP considered in the above comparison – significant wallet implementation complexity, ~2-3x higher fees/bandwidth, regardless of mutation tracking (“take 3” or a modified “take 2”).
While the other CHIPs (P2S, Loops, and Bitwise) simplify the post-quantum spending paths, the “quantum-wrapper” is already designed to allow sweep-free upgrading of those post-quantum paths, meaning that even if P2S, Loops, and Bitwise weren’t to lock-in for 2026, quantum-ready wallets could still begin deployment in 2026 – without emulation-based technical debt in wallet UTXO management and on-chain contracts.
Because the post-quantum spending paths are sweep-free, such “Functions CHIP-only” wallets would even be able to incrementally adopt the additional post-quantum efficiencies made possible by P2S, Loops, and Bitwise over future years with just one, privacy-nonce-protected UTXO migration – without sweeping or otherwise leaking the privacy of each user’s vault UTXOs. (For a deeper dive, see BCH Tech Talk: Intro to Quantum-Ready Vaults using Quantumroot.)
Quantum-readiness without a “Quantum” upgrade
I want to highlight here again that Bitcoin Cash is uniquely positioned among top cryptocurrencies, by our high-performance contract system, to roll out fully-quantum-ready wallets in 2026, without committing to a specific, “quantum-ready” signature algorithm and/or corresponding upgrade.
Beyond this specific value for quantum-readiness, native functions are also widely useful for simplifying and making algorithms more compact and readable, meaning the Functions CHIP offers wide value across the entire contract ecosystem, regardless of Q-Day timelines.
With that background on the value of native functions, let’s examine mutation tracking specifically:
Defining mutation tracking
Below I take mutation tracking to cover both “take 2” and “take 3” – any addition to the VM which attempts to track stack items as “safe” or “unsafe” for use in function definitions, where the underlying intention is to prevent use of function factories (“code that writes code”) within a single input.
Protocol complexity & overhead of mutation tracking
Mutation tracking requires:
- Additional complexity and testing surface for VM implementations – new edge cases and consensus code spread across many opcodes,
- Slightly increased per-operation VM overhead, reducing the VM’s performance potential on heavy applications. (Think of it as up to ~1 opCost in new, real-world overhead.)
Performance is a major competitive advantage of Bitcoin Cash’s VM vs. EVM, Solana, and other contract ecosystems, so I take losses here very seriously (even if relatively small at present scale/speed).
Bitcoin Cash could soon have the most capable VM of any major, decentralized cryptocurrency; I’ll note that e.g. Solana’s VM appears to be incapable of supporting 128-bit post-quantum vaults like Bitcoin Cash’s Quantumroot.
The widely publicized Solana Winternitz Vault is an impressive (in the engineering sense) workaround for Solana’s more limited contract capabilities vs. Bitcoin Cash. The Solana vault requires unusual modifications to well-reviewed cryptography, and it still comes up short of Quantumroot’s standards-based, SHA256-only, 128-bit post-quantum security strength.1
1. This announcement describes the need for non-standard cryptographic techniques on Solana. The GitHub repo claims 112-bit post-quantum security strength.
Quantumroot implements RFC 8554 (also adopted by NIST SP 800-208), and even spends a few extra bytes in the (hidden, off-chain) post-quantum paths to maintain precise compatibility.
Aside: also note here that BCH’s SHA256 proof-of-work consensus is well understood to be ready for Q-Day (and maybe decades beyond), while nearly all Proof-of-Stake protocols today are quantum-vulnerable (and the “quantum-ready” protocols have made serious tradeoffs to claim it as a feature). BCH seems to be at-or-near #1 in post-quantum readiness, especially among top cryptocurrencies.
Ecosystem impact of mutation tracking
As mentioned above, perhaps the most visible impact of mutation tracking is the additional VM complexity and testing surface area. (Though our cross-implementation VM testing suite makes this work easier to complete and verify.) Beyond VM implementations, there’s negligible potential impact to any existing wallets, ecosystem software, contract authors, or end users – regardless of mutation tracking.
As we’ll see below, mutation tracking bans several simplifications/optimizations which primarily benefit relatively-complex contracts (up to ~30% transaction size savings); simpler contracts might save only a few bytes in rare cases. Among those more complex cases, function factories also offer some meaningful compiler and audit tooling simplifications by enabling definition of off-stack constants (see below).
Overall, mutation tracking appears only to reduce the practical usability, safety, and efficiency of BCH contracts, while meaningfully increasing protocol complexity. In these situations, my strong preference is to maximize protocol simplicity – in this case, by not adding mutation tracking to the consensus code.
Of course, if a contract/tooling developer wants some aspect of the mutation tracking behavior in their own systems, they can always add it themselves, limit use of native functions to easily verified approaches, and/or ignore native functions altogether. Plenty of tooling already ignores existing opcodes. E.g. OP_DEPTH has been prominently criticized by contributors to Miniscript and remains unused by that compiler. (Quantumroot coincidentally makes use of OP_DEPTH to minimize cross-input and cross-address aggregation, but BTC’s MINIMALIF micro-optimization for Lightning Network breaks the construction on BTC.)
I’ll now try to examine how mutation tracking is either irrelevant or counterproductive to practical contract security:
Mutation tracking makes contracts more complex, less efficient, and harder to audit
I’ll walk through examples to convey the following points:
-
Function factories would immediately enable more strategies for stack-scheduling-naive compilers to safely compile BCH contracts (esp. compilers that weren’t designed specifically for BCH, like zkVMs, Rust, etc.). Precomputed tables are easy to show without a specific compiler context, since they’re useful even to hand-optimized contracts, but the underlying idea – off-stack constants – can both simplify compilation (i.e. adding support for BCH to other compilers) and make the resulting contracts easier to audit (both manually and via tooling).
-
Function-based precomputed tables offer a significant opCost reduction vs. stack-based tables due to reduced stack juggling in hot loops (reducing transaction sizes by up to ~30% for heavy use cases).
-
We cannot possibly “ban metaprogramming”, even if that were a sensible goal – metaprogramming is easy to do today (and remember, today’s status quo offers the maximum “rug-deniability”: you have to use arcane multi-input workarounds to even emulate functions today, with plenty of little footguns that can be “missed” by audits.)
-
Pretending to ban metaprogramming (with mutation tracking via “take 2” or “take 3”) adds meaningful protocol complexity. In my opinion, mutation tracking is an anti-feature serving only to hurt practical security and usefulness.
First, to expand the earlier precomputed tables examples:
The problem with stack-based constants
The root problem with stack-based constants (and especially precomputed tables) is that the stack mutates while you’re working.
For precomputed tables, that means your “table references” get deeper or shallower at various points in your contract evaluation, and you have to interlace tracking of that offset with the actual algorithm.
Sometimes that offset is fixed and can be “baked-in” to the contract, while sometimes it’s dynamic, making complexity and performance even worse.
In practice, this means that mutation tracking would prevent contract/compiler developers from using function factories in specific cases to simplify compilers, minimize dead weight in hot loops, and simplify compiled contract code. With mutation tracking (especially with loops), complex contracts will remain meaningfully harder to develop and audit because every part of today’s contracts must share and mutate two giant stacks.
Precomputed tables optimize opCost
Before we go further, it’s important to understand that precomputed tables are aimed at optimizing for performance, i.e. opCost: to make the code more efficient rather than (directly) to make it denser.
For many heavy math and cryptography algorithms (post-quantum crypto, zero-knowledge proof verification, homomorphic encryption, financial market scoring for large sets of multidimensional prediction markets, etc.), the real bottleneck to practical implementation is opCost – making opCost the difference between a simple, low-fee transaction or a messy series of expensive transactions.
Of course, this is an intentional and important protection for the network: the opCost density limits ensure that every transaction either validates quickly or is rejected. Essentially, the network is demanding that all contracts be at least as-fast-to-validate-per-byte as “payments-only” transactions.
So: optimizations which help contracts lower net opCost can ultimately help to reduce transaction sizes in these heavy use cases – enabling their greater throughput on BCH.
Optimizing code length (high opCost)
To demonstrate for the bit-reversal example, here’s one approach to optimization – for each byte, the contract could perform the below operations. Note that this is already fairly opCost-optimized vs. a naive 8-iteration loop over each byte:
// test: <0x12>
OP_DUP <1> OP_LSHIFTBIN <0xaa> OP_AND
OP_SWAP <1> OP_RSHIFTBIN <0x55> OP_AND
OP_OR
OP_DUP <2> OP_LSHIFTBIN <0xcc> OP_AND
OP_SWAP <2> OP_RSHIFTBIN <0x33> OP_AND
OP_OR
OP_DUP <4> OP_LSHIFTBIN <0xf0> OP_AND
OP_SWAP <4> OP_RSHIFTBIN <0x0f> OP_AND
OP_OR
// check: <0x48>
This minimizes contract length by eliminating the initial overhead of the precomputed table, but it has an opCost of 3330 per bit-reversed byte (excluding any OP_INVOKEs, so we’re generously assuming it’s used in only one tight loop).
Optimizing OpCost (low opCost)
On the other hand, a precomputed table can unpack or read from a hard-coded table, paying some fixed upfront opCost and then minimizing the per-byte opCost (by eliminating all shifts/math per byte):
// test: <0x12>
OP_INVOKE // internal: <0x48>
This has an opCost of only 201 per byte, consisting almost entirely of base instruction cost (OP_INVOKE plus the internal push). This is both a ~15x improvement and much more “close to the metal” (within the CashVM sandbox) – minimizing VM interpreter revolutions.
These gains add up across large and heavy computations, reducing or eliminating the need to pack input data for opCost budget, and ultimately leading to less waste and smaller transaction sizes.
For performance-sensitive use cases, this can easily be the difference between practical and impractical.
So the takeaway: for these precomputed table examples, the difference between “this use case works” and “this hits VM limits” is actually determined by invocation-site opCost. And by extension, since longer inputs give you more compute, in these cases the real bottleneck on contract length is the opCost of invocation sites.
Comparing to stack-based deep picking
Note that the above doesn’t yet explain why some contracts benefit from function-factory-based precomputed tables (since you can still deep PICK from a stack-based table), but now we’re looking at the right numbers – we want to minimize invocation-site opCost.
Again, the root problem here is that our “table references” shift while we’re working, so we have to interlace tracking of stack mutation with the actual algorithm.
This stack juggling makes contracts more complex, adds a lot of wasteful indirection (further from “bare metal”), and it also makes contracts much harder to write and audit.
Also, because such stack juggling requires specialized stack-aware compiler algorithms, it’s also a serious barrier to entry for projects/compilers that might otherwise be able to port code or add BCH as a drop-in compilation target.
Some real juggling examples:
Level 1 with function factories
For reference, here’s a reasonable byte-by-byte bit-reversal permutation function optimized with a function-factory-produced precomputed table:
// ... Setup table ...
// Bit-reverse binary array:
<> // [[ output_slot ]]
<0x01020304> // [[ input ]]
OP_REVERSEBYTES
OP_BEGIN
<1> OP_SPLIT OP_SWAP // Get next byte
OP_INVOKE // Bit-reverse it
OP_ROT OP_CAT // Append to output_slot
OP_SWAP // Place remaining bytes back on top
OP_SIZE OP_NOT OP_UNTIL // Loop until bytes are gone
OP_DROP // out: 0x8040c020
// No tear-down required, stack is clean
The hot loop here has an opCost of ~1100 (including the OP_UNTIL and invoked push). The precomputed table is directly referenced like a constant, no additional manipulation of each byte needed, just split and invoke.
Level 1 without function factories
Now for a best case scenario without function factories: references are only used in one spot, and the stack isn’t changing depth under them. This still requires the contract to hard-code depth calculation math and stack-juggling before each deep pick, e.g.:
// Setup stack-only precomputed table:
// Initially a few bytes cheaper, but increases invocation-site opCost
<0x008040c020 /* ... */ > // endianness reversed for stack-juggling efficiency
OP_BEGIN
<1> OP_SPLIT
OP_SIZE OP_NOT
OP_UNTIL
OP_DROP
// Bit-reverse binary array:
<> // [[ output_slot ]]
<0x01020304> // [[ input ]]
OP_REVERSEBYTES
OP_BEGIN
<1> OP_SPLIT OP_SWAP
<2> OP_ADD // <- Breaks if this code's depth offset changes
OP_PICK // (Copies from up to 257 deep in the stack)
OP_ROT OP_CAT
OP_SWAP
OP_SIZE OP_NOT OP_UNTIL
OP_DROP // out: 0x8040c020
// Later stack clean-up (at contract end):
OP_TOALTSTACK
OP_BEGIN
OP_DROP
OP_DEPTH OP_NOT
OP_UNTIL
OP_FROMALTSTACK // out: 0x8040c020
This stack-based implementation is:
-
Not safely portable – you cannot safely include this code in a function and execute it in two code locations as the depth offset (here,
2) must match. You need to either A) duplicate the code and modify the hard-coded indexes to match the expected deep-picking depth offset in the new code location, or B) parameterize the function with the stack-depth offset to use (i.e. additional juggling in the hot loop) - Internally brittle – if the logic in this loop changes slightly, the stack depth at the referencing location might increase or decrease by one. This is particularly messy for compilers attempting to optimize the loop – it might be more efficient to reference the table earlier or later, and the compiler might need to try a few options, between which the precise offset will be different based on the juggling.
- Less efficient – managing the offset inside the hot loop adds at least 1 base instruction cost (total opCost: ~1200), including an OP_ADD (or OP_SUB) numeric operation, which is fundamentally more costly than stack operations (meaning this code is another unnecessary step removed from “bare metal” performance, implying it would probably retain more opCost even if some future upgrade lowered base instruction cost simply because the OP_ADD (+ numeric interpretation + re-encoding for the stack) is one of the most costly parts of this loop on real hardware).
Level 1 comparison with vs. without function factories
I think there are substantial contract efficiency and safety benefits of compilers being allowed to use metaprogramming/function factories here:
- The metaprogramming approach is easier to prove correct – even a compiler that doesn’t have “deep CashVM support” can safely translate code into fixed snippets at each location. The depth offset of the table doesn’t need to be tracked, and movements in the code won’t cause unexpected behavior.
- There’s also substantial performance/opCost improvement – a “less smart” compiler can do up to 10% better in these spots than the smartest-possible, CashVM-focused compiler, even though the compiler is more “stack-scheduling naive” – perhaps it’s just filling in cookie-cutter “loop templates” that are well-reviewed, dropping them into the compiled output at the right spot, and not bothering with any sort of contract-wide stack scheduling optimization (just directly translating code in source order).
Note again, the CashScript compiler today relies heavily on deep stack picking and simple find/replace rules (no “optimal” stack scheduling), so CashScript is an example of one of those “less smart” compilers right now.
CashScript could probably use function factories to more safely implement some high-language features (esp. loops referencing constant data structures) in ways that produce much more auditable code artifacts, and such constructions would even leapfrog (in performance/contract length) the efficiency gains of a far-harder compiler migration from deep-picking to optimized stack scheduling.
Stepping back: I think this observation is especially relevant for non-BCH-native toolchains like zkVM projects, LLVM, AssemblyScript, Rust, etc. where the compiler could be extended to add BCH as a target.
Metaprogramming gives these projects some additional, immediate flexibility to implement the dynamically assigned constants they expect, without necessarily requiring deep-picking and stack juggling support. Even if the resulting bytecode is a little less byte-efficient than “perfectly-optimized CashVM bytecode”, if function-factory-based strategies are sufficiently-similar to some compilation path currently in use, it becomes much easier to re-use compiler infrastructure from other targets, dropping in simple setup/teardown blocks to smooth over any differences. (Note, 99% of this value is probably possible just with native functions regardless of mutation tracking, but any edge cases could make a huge difference: “yes, you can just port that exactly, use this snippet and it will work how you expect” vs. “no, we deliberately made metaprogramming more obscure to use, you’ll have to either implement deep stack tracking or fiddle with these multi-input workarounds.”)
Now let’s make this example one level more complex:
Level 2 with function factories
Pattern: an algorithm begins with an array, performs computations on each item by referencing a previously-computed value, ultimately reducing the array into one result (e.g. “XOR the values”).
Note that this is a pattern for which the depth offset of the data changes at each iteration of the loop. In this case, the pick-depth is simply one-item shallower on each iteration.
Function-factory-based table, the reduction step:
// ... Setup table ...
<1> OP_TOALTSTACK // [[ alt: output_slot ]]
<0x01> <0x02> <0x04> // start with an array of values
OP_BEGIN
OP_INVOKE // Lookup next value in precomputed table
OP_FROMALTSTACK
OP_XOR // Reduce it into output_slot
OP_TOALTSTACK
OP_DEPTH OP_NOT // Loop until items are consumed
OP_UNTIL
OP_FROMALTSTACK // out: 0xe0
Hot loop opCost: ~800 (including the OP_UNTIL and invoked push).
Level 2 without function factories
Here’s what it looks like to track a stack-based precomputed table’s offset from within this logic:
<0x20> <0xc0> <0x40> <0x80> <0x00> // setup tiny stack-based table (order must be reversed)
<0x00> OP_TOALTSTACK // [[ alt: output_slot ]]
<0x01> <0x02> <0x04> // start with an array of values
OP_BEGIN
OP_DEPTH <5> OP_SUB // [[ remaining_items ]]
OP_TUCK // Save for OP_UNTIL
OP_ADD // [[ next_value_stack_offset ]]
OP_PICK // Deep pick from table
OP_FROMALTSTACK
OP_XOR // Reduce it into output_slot
OP_TOALTSTACK
<1> OP_LESSTHANOREQUAL // Loop until last item
OP_UNTIL
OP_BEGIN OP_DROP OP_DEPTH OP_NOT OP_UNTIL // clear table
OP_FROMALTSTACK // out: 0xe0
Hot loop opCost: ~1100, a 37.5% increase, meaning that for opCost constrained applications (heavy math/crypto), mutation tracking could increase such transaction sizes by up to 37.5%, in addition to the substantial increase in code complexity.
In this example again, location-dependent stack information is baked into the code, making this less portable, more brittle, and/or less efficient – now including both an OP_SUB and an OP_ADD exclusively for stack juggling purposes, meaning this snippet is also two relatively-heavy (numeric) operations away from “bare metal” performance.
There are many ways to refactor this code (see: Turing completeness) to reference the precomputed table without stack depth changes, but these also increase opCost in the hot loop and cloud the algorithm with CashVM-specific implementation details – meaning more BCH-specific compiler work and/or hand optimization effort. (For example, to avoid the stack depth change, you could first iterate over the items and copy values from the precomputed table – in order – to the altstack, then in another pass, pull them one at a time from the altstack to consume both.)
9 Likes
Level 3: Module-Lattice-Based Digital Signature Standard (ML-DSA)
Now that we’ve reviewed the above array reduction snippet, I want to highlight a post-quantum signature standard that reads from a precomputed table in double-nested loops: FIPS 204, Module-Lattice-Based Digital Signature Standard (ML-DSA), reads from the Zetas Array (Appendix B, page 51) inside the very hot internal loops of Algorithms 41 (NTT, page 43) and 42 (inverse of the NTT, page 44).
Notice each reference site is nested inside two loops, where the internal loop is accumulating computed values into an array, i.e. changing stack depth. Given the above example, it’s reasonable to estimate that an off-stack precomputed table in these algorithms will significantly simplify the code, eliminate at least two stack juggling/index arithmetic locations, and commensurately reduce opCost.
Finally, here’s a Bitauth IDE import link demonstrating the encoding efficiency gains of using function factories in this case:
- With a very simple function factory, that same table can be encoded in 808 bytes.
- With function factories banned (via mutation tracking), the encoded length of the “header” which sets up the precomputed table is 2,151 bytes.
As a contract-based ML-DSA implementation will likely be opCost constrained (and of course, substantially harder to implement without off-stack constants), this implies that with mutation tracking, transactions including lattice-based, post-quantum signatures will be at least ~1.3KB larger – and that’s before accounting for algorithm code size, public key lengths, and the actual quantum signatures.
(Aside: a contract-based ML-DSA implementation would be very technically interesting, but I strongly encourage you to use Quantumroot for at least the next few years – it’s meaningfully safer and already maximizes pre-quantum efficiency.)
Level 3, split into two locations
Finally, this example doesn’t need a precomputed table (because the work being done is simply OP_SHA256), but it’s instructive to understand how more deeply-nested control flow can appear in various algorithms (here, LM-OTS signing):
A function definition containing the hottest, inner loop:
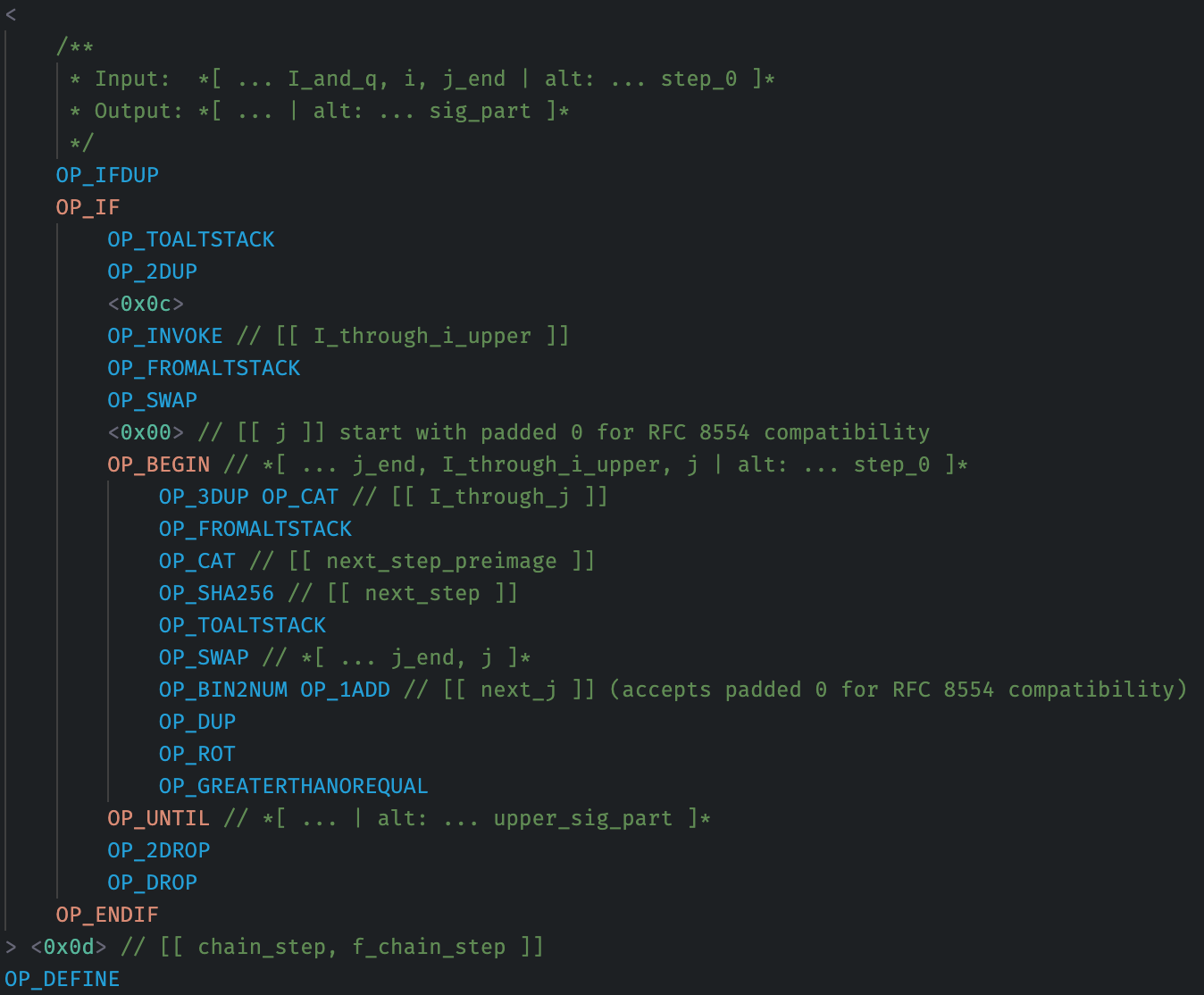
And the outer loop:
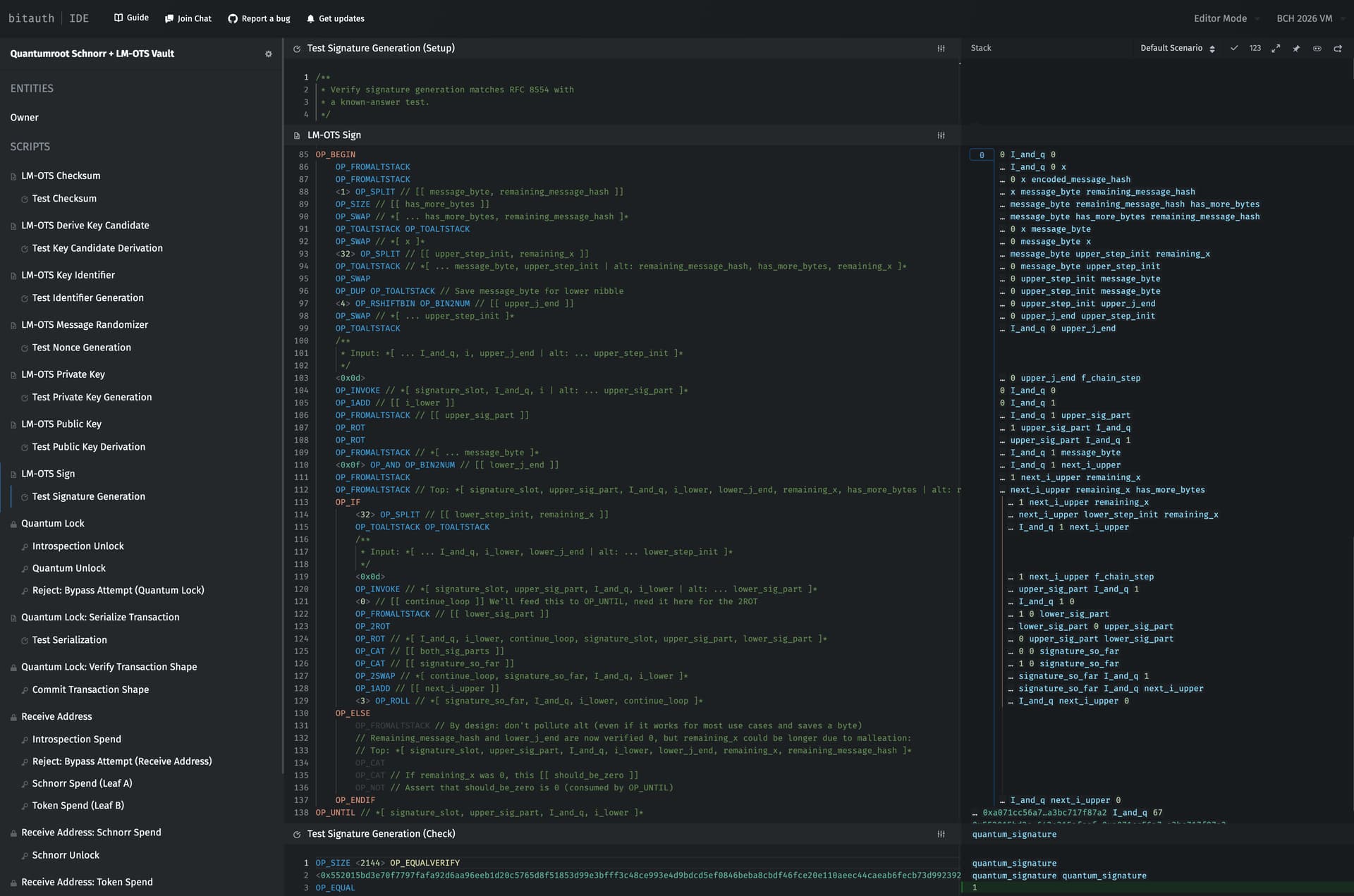
The outer loop calls a function in two different locations per iteration, and that twice-called function has a hot inner loop.
Consider how much more complicated this code would become if it needed to deep-pick something from the stack inside the inner loop. At the very least, the hot loop function would need to be inlined with different, hard-coded, stack-depth offsets. Depending on the precise opCost optimization context, a “perfectly optimizing” compiler (or human/LLM) may even choose to minimize encoded bytes by parameterizing the function with offset juggling, increasing the opCost of the inner loop and introducing the code portability/brittleness/obscurity and auditing difficulty discussed above.
Zero-opCost Function Invocation
The above Quantumroot example highlights another optimization made uniquely possible by function factories: because a function is used in two different places within the outer loop, it would be more opCost efficient to inline these calls, omitting the OP_INVOKEs entirely. With function factories banned, you’re forced to choose either the opCost-optimized construction – duplicating the bytecode – or the bytecode length-optimized construction used in the above example (which is not opCost constrained).
If Quantumroot were an opCost-constrained contract, needing to improve performance to further minimize transaction sizes, the contract could be refactored to concatenate the bytecode from chunks provided at the beginning of the contract – the repeated segments of bytecode are then deduplicated over the wire, while the invocations within the outer loop are entirely inlined (and simply executed by a single “main” function) – i.e. invocation-site opCost overhead in the hot area becomes zero, as the would-be reference has been directly compiled into the bytecode.
Aside: this is exactly how Forth is designed to work
On a much more theoretical level: I want to highlight that this “concatenation of program bytecode” is precisely how Forth was designed to work. (Forth is the language on which Satoshi based Bitcoin Cash’s VM.)
Forth is a high-level, concatenative programming language, and this sort of metaprogramming is precisely why it is “stack-based” – the stack is how you pass data between functions without specifying input and output parameters. The high-level syntax is designed to maximize composability of data and functions (“words”), without glue code between those words.
Forth’s inventor, Charles Moore, called Forth a “Problem-Oriented Language”, intended to create new “application-oriented languages” (i.e. metaprogramming), that are efficient and concise (see: “1% the code”) all the way down to the hardware (making it well suited to bootstrapping). Of course, the Bitcoin Cash VM only has an interpret mode rather than separate compile/interpret modes (significantly simplifying VM implementations), and it is also opinionatedly application-optimized (by Satoshi) in the core instruction set to minimize bytecode length using single-byte opcodes as complex core words (OP_CHECKSIG, OP_CHECKMULTISIG, etc.).
The point here is that from a theoretical perspective, significant design effort and iteration went into the underlying concatenative syntax, and that iteration was specifically aimed at producing more code-length-concise programs – both for humans to read and for machines to execute – by allowing code to be re-ordered, composed, and extended via concatenation.
In my opinion, Bitcoin Cash VM upgrades should focus primarily on practical usability, contract security, performance/throughput, etc., but for stakeholders concerned with more abstract properties like elegance and language consistency – note that mutation tracking would be an unusual and contradictory choice.
Reviewing risks: auditing function factory-compressed code
Let’s now look at a more abstract use case for function factories: compressing contract bytecode by extracting common segments and encoding them in a self-unpacking, executable header.
Note that even without function factories, sufficiently complex contracts (especially compiled contracts) are likely to be compressible by some degree of deduplication using simple, statically-applicable optimizations – common segments can be extracted and replaced with inline OP_INVOKEs.
With function factories, even further optimizations are made possible: composition of segments can be performed with stack operations and concatenation rather than deeply nested functions and/or contiguous invocations (e.g. <1> OP_INVOKE <2> OP_INVOKE ...).
These optimization strategies (with or without function factories) are potentially very valuable for complex contracts and advanced compilers – they enable removal of dead weight with extremely minimal implementation complexity (see Rationale: Simple, Statically-Applicable Contract Length Optimizations). Further, external/audit verification is trivial and deterministic: simply compare the evaluated result to the expected, uncompressed code. This is far better than the situation today, where hand-optimizations of compiled outputs must often be hand-audited.
Note also that VM limit bounds checking is unaffected by this compression – if your contract has a chance of coming close to the VM limits, you need to audit the bounds in either case (or better yet, opt for a fail-safe design, see CHIP). Further, the task of bounds auditing is precisely equivalent between the two cases, they differ only in your starting opCost budget (because the optimized contract is shorter) – after the function factories are finished and the “main” function begins, the behavior of the remaining program is the same (by design, see Rationale: Preservation of Alternate Stack).
Reviewing risks: bytecode readability
One potential reaction to this idea – made worse by many programmers being unfamiliar with stack-based languages – is to ask, “won’t that make the code harder to read?”
The answer is categorically no, both from the perspective of human-eyes reviews and (much more reliable) audit tooling.
This is the case because you see both the “compressed” code and “uncompressed” code at the same time – the uncompressed code is the deterministic result of the compressed code, and you can always look at both for every audit. Thus, as an auditor, you’ve only received new information – before you could only look at the uncompressed code, but now you can see a version in which duplication or boilerplate has been stripped away, leaving only the bits that matter.
For example, consider deeply nested conditional trees (OP_IF ... OP_IF ...OP_ELSE ... OP_ENDIF ... OP_ENDIF) of spending policies based on a table (maybe some advanced multi-sig vault with lots of process and fallbacks). Even if you were exceptionally comfortable with eyeballing raw CashAssembly, the “compressed” version may be significantly more auditable than the resulting, deeply-nested tree of policy conditions, because the conditions are defined in data, while the deeply-repetitive OP_IF/OP_ELSE/OP_ENDIF operations are noise: they’re generated from the table. (Note, a more evolved version of this example is Miniscript compiling to a P2WSH output.)
To help visualize, here’s a simple tree (though this section is meant to consider any such heavily-structured, generated contract):
<alice.public_key> OP_CHECKSIG
OP_IF
<authorization_message> <bob.public_key> OP_CHECKDATASIG
OP_IF
OP_TRUE
OP_ELSE
<cat.public_key> OP_CHECKSIG
OP_IF
OP_TRUE
OP_ELSE
OP_FALSE
OP_ENDIF
OP_ENDIF
OP_ELSE
OP_FALSE
OP_ENDIF
Today, if a malicious actor were to make structural changes to such a contract, an informal review might miss a new, stray OP_ELSE snuck into a deeply nested clause within the “uncompressed” tree, perhaps as part of a formatting change. However, given the additional availability of a compressed version, such a change (malicious or accidental) becomes more likely to be caught by an auditor:
Before the malicious change, the tree was already being systematically-generated, and typical updates would only modify some input data. After the malicious change, the “compressed” version (whether designed by hand or some algorithm) will also have to change, giving the auditor/tooling two chances to catch the maliciousness. Additionally, underhandedness in one version will be more visible in the other: to modify only one tree leaf in the uncompressed version, the compressed version needs a targeted conditional for just that leaf, rendering a very visible change in the compressed version. On the other hand, underhandedness in the compressed version (without a targeted conditional) will very likely multiply during “decompression” into many small modifications throughout the uncompressed version.
Of course, we’ve been very generous with the idea of an “audit” here – your human eyes are quite likely to miss subtle errors or underhanded exploits in either version; sufficient audits should not rely solely on visual checks and/or LLM once-overs. Regardless, careful analysis has revealed that even with a very loose definition of “auditability” – humans reading strings of text – compression with function factories has negligible or positive impacts on the overall auditability of code.
Reviewing risks: self-unpacking code
At first encounter, some people will jump to the conclusion that the mere possibility of useful, “self-unpacking” code means that we’ll soon be inundated by contracts full of scary, hard-to-understand stack gymnastics and invocations.
As described above, this first impression is mistaken – compression can only reveal new information to auditors and auditing software. However, let’s also review the underlying assumptions – I think this perspective also misunderstands where we are today:
- We are – already today – inundated by deep-picking-based contracts, with significant trust placed on compiler tooling, and significant room for underhanded exploits inserted at multiple levels in the toolchain. As contracts get more complex – and especially with loops (see the above array reduction example) – the compiled results are getting far harder to “audit” with your human eyes. We need better tools, and soon. This cannot be directly fixed by a network upgrade, but a sufficiently capable VM can encourage investment in those tools (see below).
- This perspective also presupposes that obscure kinds of metaprogramming will be both commonly chosen by contract authors and considered plausibly non-malicious by auditors. This is obviously not the case given the necessity of this deep-dive: such distrust of metaprogramming already exists that a stakeholder wants to sacrifice some VM performance and complexity – possibly forever – to discourage its use. Contracts employing function factories in even slightly non-obvious ways face a serious uphill battle to convince an auditor that such constructions aren’t inherently malicious. Function factories are therefore risky places for malicious authors to hide underhanded exploits, as they’re a magnet for review.
- As we saw with precomputed tables, there are important cases where function factories can significantly simplify complied code, even to human eyes, in addition to the simple contract-length gains.
- From a purely quantitative perspective, it takes quite a few bytes of overhead to do any function-factory-based compression (reused segments must be at least 3 bytes to even warrant a definition, and any duplication or stack operations add to this baseline). The most efficient constructions also minimize bytes by clustering the “unpacking” together (because of multi-step opcodes, see “Appendix B: On CashAssembly”). I.e. any deviations from “there’s some unpacking here at the top” will therefore draw even more scrutiny, even from a purely efficiency-focused perspective, with any audits or tooling raising red flags and requiring substantial explanation.
- Finally, because of that quantitative reality, use cases for function factories are already relatively unusual (simplifying or optimizing large, complex, and performance-sensitive contracts) vs. today’s most common, CashToken-based DeFi apps, meaning from yet another angle – function factories will continue to be rare, carefully reviewed, and well-justified. (Again, if “enabling function factories” required negative tradeoffs from a VM performance or complexity perspective, it would not pass my own bar of “yes, this is useful enough to justify additional protocol complexity”. However this deep-dive reviews the opposite situation: mutation tracking would add significant, possibly-permanent complexity to the VM and protocol in an attempt to somehow make BCH contracts safer. So far we’ve seen that in practice it would achieve precisely the opposite: mutation tracking would simply make BCH less safe and less useful.)
How to prevent real underhanded code
Let’s switch now to looking at what I consider to be real underhanded code.
This doesn’t require functions, and it’s a bug in a very widely-useful construction today: introspection-based, cross-input aggregation.
Correctly implemented, this snippet can significantly reduce the sweep costs of nearly every kind of user-held contract. It’s extremely low overhead – meaning it’s already a good idea for most P2SH contracts, and it’s the underlying reason why Quantumroot is 15% cheaper-per-additional-UTXO than standard P2PKH today (and the savings even increase if you don’t need 128-bit post-quantum security strength):
<key.public_key> OP_CHECKSIG
OP_IFDUP OP_NOTIF // Keep a 1 if the signature passed.
OP_DUP OP_INPUTINDEX OP_NUMNOTEQUAL OP_VERIFY // For security ⚠️: verify it's not this input!
// Now we just need to check that the other input matches, meaning it has a valid signature:
OP_UTXOBYTECODE // [ sibling_utxo_bytecode ]
OP_ACTIVEBYTECODE OP_EQUAL // ✅ Done, the other input has a valid signature.
OP_ENDIF
// (Note: the above comments are intentionally misleading, see explanation below.)
(Here’s a Bitauth IDE import to explore.) This contract lets you either:
- Prove you can sign for the public key, or
- Prove you already signed for this exact address in another transaction input.
Job’s done, right?
The vulnerability here requires significant understanding of transaction context and malleability, so it’s extremely plausible that honest contract authors and auditors will miss it – especially if they’re coming to BCH from non-UTXO-based contract ecosystems.
The vulnerability: this contract can be spent by anyone who simply knows two of these UTXOs, no signature required, by pointing each introspection spending path at the other input. The malicious author can then watch the mempool, waiting to swipe a large-enough aggregated spend. (For details and one solution, see BCH Tech Talk: Intro to Quantum-Ready Vaults using Quantumroot.)
In isolation, this is quite easy for an audit to catch, but remember we’re talking about intentional maliciousness – this could be several steps down a complex conditional, hidden inside some P2SH path, unrevealed until a company is migrating a cold vault. (This sort of targeted attack has happened in the wild, where to minimize detection, the malicious code only activated for very large wallet balances.)
Again, this is an easy vulnerability to accidentally introduce today, as most contract authors and today’s tools tend to over-focus on the bytecode of a single input. Program flow within a single contiguous block of code is relatively easier to understand and audit than complex situations involving multiple inputs working together.
By extension, single-input underhandedness is substantially harder to get away with than multi-input underhandedness – mistakes in multi-input systems are quite likely, even by non-malicious contract authors.
In practice, this means that malicious contract authors are more likely to hide maliciousness in today’s existing function-emulation workarounds than they would be in single-input constructions like native functions. Giving honest contract authors maximally-capable functions – minimizing the frequency with which honest contracts reach for multi-input constructions – therefore seems likely to make such maliciousness “stick out more” to auditors.
Reality: contract tooling lags behind ecosystem growth
I would love for Bitcoin Cash’s contract ecosystem to get stronger, safer, automatic tooling to audit for the above type of vulnerability (again, such vulnerabilities exist today and are even made easier to hide by the lack of native functions). I certainly have such tooling on my backlog, particularly as part of continuing to audit the Quantumroot contracts before (hopefully, 2026) deployment.
However, it’s hard for many projects to justify such huge investments for a single contract, especially when their contract is simple and/or modular enough to be reasonably “hand-auditable”. Successful projects do things that don’t scale to get their product in front of users faster.
This weakness in demand for generalized audit tooling is exacerbated by the average simplicity of (seen) BCH contracts today, where much harder (unseen) projects are not even begun due to the obvious lack of critical programming constructions: most importantly, functions. (Again, loops are trivial to unroll.)
On the other hand, if a significant arm of the BCH contract development ecosystem were plowing ahead on far more ambitious, harder-to-verify projects, the rest of the ecosystem would benefit from the tooling they produced. E.g. porting an on-chain STARK verifier (whenever one ships full privacy – such that it could be used in privacy covenants), extending Rust to add a CashVM target, developing a WASM-to-CashVM compiler, etc.
The proven way to get better tooling is growth in contract development. If we want better audit tooling, formal verification of contracts, more capable compilers, etc. we need to increase the addressable market of contract developers sufficiently to attract such investments.
To drive this home, Aside: the 2011-era “static analysis” debate:
Comparisons to hypothetical future upgrades
Because I specifically highlighted precomputed tables as a strong use case for function factories, I’d like to strengthen the argument by considering some possible future upgrades (no plans to CHIP, just for completeness):
OP_STORE and OP_FETCH
If a future upgrade were to enable setting variables via OP_STORE and reading via OP_FETCH, these operations could also be used for creating and reading from precomputed tables. This would enable part of the opCost and compiler/tooling advantages discussed above (minus zero-opCost invocation and simple compression + auditing).
However, OP_STORE would likely be aimed at a different (mutable) access pattern, allowing a single stack item to be stored without first encoding it as a push operation, but disallowing the more complex composition available via OP_DEFINE, e.g. pushing multiple stack items (e.g. for pre-split use as an array), or performing a combination of pushes and additional function calls. Additionally, OP_STORE would (presumably) allow mutation, slightly changing the safety profile vs. the immutable constants enabled by OP_DEFINE. Finally, depending on the contract author/compiler, mutable variables might be used elsewhere in the contract, meaning a precomputed table would either 1) crowd out single-byte-push indexes (OP_1NEGATE and OP_0 through OP_16), therefore adding bytes to those OP_STORE/OP_FETCH sites, or 2) be forced to use another “sub-namespace” (e.g. <index> <0x01> OP_CAT OP_FETCH for 0xNN01) losing some of the opCost advantage.
OP_STOREVAR, OP_FETCHVAR, OP_STORECONST, and OP_FETCHCONST
If we expand the hypothetical to 4 new opcodes: OP_STOREVAR, OP_FETCHVAR, OP_STORECONST, and OP_FETCHCONST, the “const” variants become more comparable to function factory-based tables (immutable and available low-indexes). However, if OP_STORECONST were aimed at single stack-item storage, it would still not be capable of storing/pushing multiple stack items and/or function calls. Such an upgrade would consume two additional opcodes for relatively-small gains – most of the new value would be in OP_STOREVAR and OP_FETCHVAR, with OP_STORECONST and OP_FETCHCONST essentially replicating a single-value-limited OP_ENCODE OP_DEFINE, just in a new namespace. (Where OP_ENCODEs purpose is minimally-encoding any stack item as a push instruction.)
Even if there were enough demand to activate all 4 opcodes, the overall usefulness of the VM would only have been maximized by leaving out mutation tracking – complex contracts would have the option of two built-in immutable namespaces (OP_DEFINE and OP_STORECONST) and one mutable (OP_STOREVAR), with OP_DEFINE behaving like traditional Forth word definition (with shadowing/redefinition disallowed), OP_STORECONST optimized for single constants, and OP_STOREVAR optimized for mutable variables. From a practical perspective, compilers/tooling/contracts already utilizing OP_DEFINE-based precomputed tables would be able to easily add support for the additional namespace(s), perhaps saving a few bytes by freeing up OP_1NEGATE and OP_0 through OP_16 for more efficient use in another namespace.
Re minimal-encoding and/or OP_ENCODE
On the topic of minimal-encoding: for safety, and to minimize the complexity of statically-applicable optimizations, functions should not have differing VM parsing behavior than top-level contract code (Rationale: Simple, Statically-Applicable Contract Length Optimizations and Rationale: Preservation of Alternate Stack). (Enforcement of minimal encoding, and later SegWit, were not very elegant solutions to the problem of unlocking bytecode malleability [see detached signatures], but nevertheless, minimal-encoding is enforced, and can’t be loosened without exposing real contracts.)
If there were sufficient demand, it’s possible an OP_ENCODE could smooth over the asymmetry in single-byte push encoding created by mandatory minimal encoding, but in practice emulating OP_ENCODE is cheap, and it’s most likely to be used in places where extra bytes matter less (e.g. setting up precomputed tables with single-byte indexes) vs. places where savings are more critical (e.g. hot loops).
Finally, note that OP_SIZE already performs the same function as this hypothetical OP_ENCODE for most 1-byte values and all 2-75 byte values – up to 600-bit numbers – efficiently covering a large portion of off-stack constant use cases.
Conclusion: mutation tracking is an anti-feature
Hopefully this deep dive will help people to review the costs of mutation tracking.
I remain open to hearing arguments in favor of mutation tracking, but for now my summary is:
- Mutation tracking cannot possibly achieve what it aims to accomplish: we have “code that writes code” already (both in atomic transactions, and of course, covenants).
- Mutation tracking is counterproductive to contract complexity and audit safety.
- Mutation tracking adds meaningful protocol complexity and wastes VM performance.
On the other hand, the thing banned by mutation tracking – function factories – increase the practical usefulness and throughput of Bitcoin Cash:
- Function factories reduce implementation costs and complexity in both compilers and contracts.
- Function factories enable ~10-30% opCost reductions in hot loops, i.e. an up to 30% decrease in transaction sizes for some math/cryptography-heavy contracts.
- Function factories enable additional, pure-code-length optimizations that are easy to apply and audit, especially for large contract systems.
Overall, mutation tracking appears to be entirely an anti-feature, adding at least dozens of lines of consensus critical code for zero practical benefit and meaningful losses: worse VM performance, larger transaction sizes, less auditable contracts, and more complex compilers/tooling.
Therefore in my opinion, mutation tracking is not sufficiently valuable to justify the additional protocol complexity.
Thank you for reading, and thank you to @emergent_reasons, @Jonathan_Silverblood, @Jonas, @albaDsl, and @cculianu for questions and discussions which made it into the above deep-dive. I’m insta-posting this without review by any of these contributors – any errors or omissions are my own. Questions and discussion appreciated.
Again:
11 Likes
I would like to amplify this aspect of benefits. Having functions is more than a particular use case. By having functions we will change how people design any non-trivial contract, and the result will be better contract designs all across. No wonder all programming languages have functions.
8 Likes
I just want to amplify that my two biggest gripes with any form of mutation restriction are these two considerations:
It’s just 1 more edge case to test and to get right internally in the implementation and while the code can be removed someday if the restriction is lifted – it’s just nasty code.
And any new OP_CODE we add now needs to consider whether it touches the stack and if so what its effect is on the “executable bit” – it’s one more thing to specify and just adds mass to an already-large mass that is the VM specification. Meh.
11 Likes