The Satoshi-based clients almost all come with a suite of benchmarks for some core functions, written in C++.
In BCHN, developers are encouraged to look at the benchmarks to assess if a change they are making, is beneficial or detrimental to the performance of the application as indicated by these benchmarks.
Of course, no one is claiming that the benchmarks are perfect. They do not cover every aspect and are added to occasionally (both from our own work and upstream). They are also not normalized, so measurements obtained on one test platform should not automatically be assumed to be correlated to those taken on another.
One has to be careful about drawing conclusions from them on the overall performance impacts of a change.
My interest here is to see how we can work with the existing (limited) data, to give developers a better chance not to miss some significant performance degradation resulting from a change.
The overall approach used is to run the benchmarks on one system, with and without a change, and compare the results.
For example in this change request (MR 548), you will find some comparisons for some benchmarks that the developer is interested in (or chose based on what his inspection convinced him were the benchmarks that could be affected by his change):
| Benchmark | median_before | median_after | median_pct_change |
|---|---|---|---|
| BlockToJsonVerbose_1MB | 0.0526412 | 0.0505036 | -4.06 |
| BlockToJsonVerbose_32MB | 2.27232 | 2.04869 | -9.84 |
| JsonReadWriteBlock_1MB | 0.049478 | 0.0490593 | -0.85 |
| JsonReadWriteBlock_32MB | 2.15773 | 2.11123 | -2.16 |
| RpcMempool | 0.00610431 | 0.00412096 | -32.49 |
| RpcMempool10k | 0.0749306 | 0.0572924 | -23.54 |
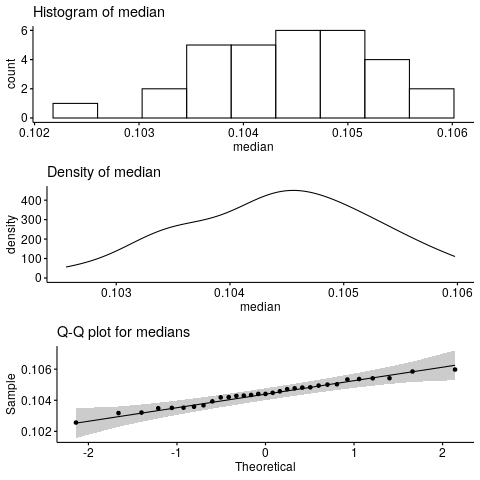
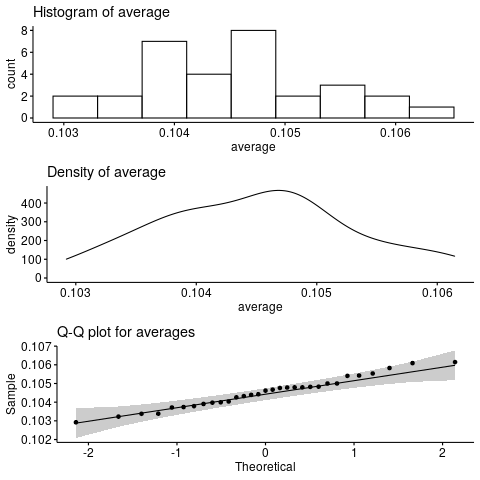
We see some ‘before’ and ‘after’ values of the median time (in seconds) of the benchmark, and a computed percentage change (negative number means improvement).
Someone else, running the same set of benchmarks on their machine, might get different number.
Of course we are interested in a few things:
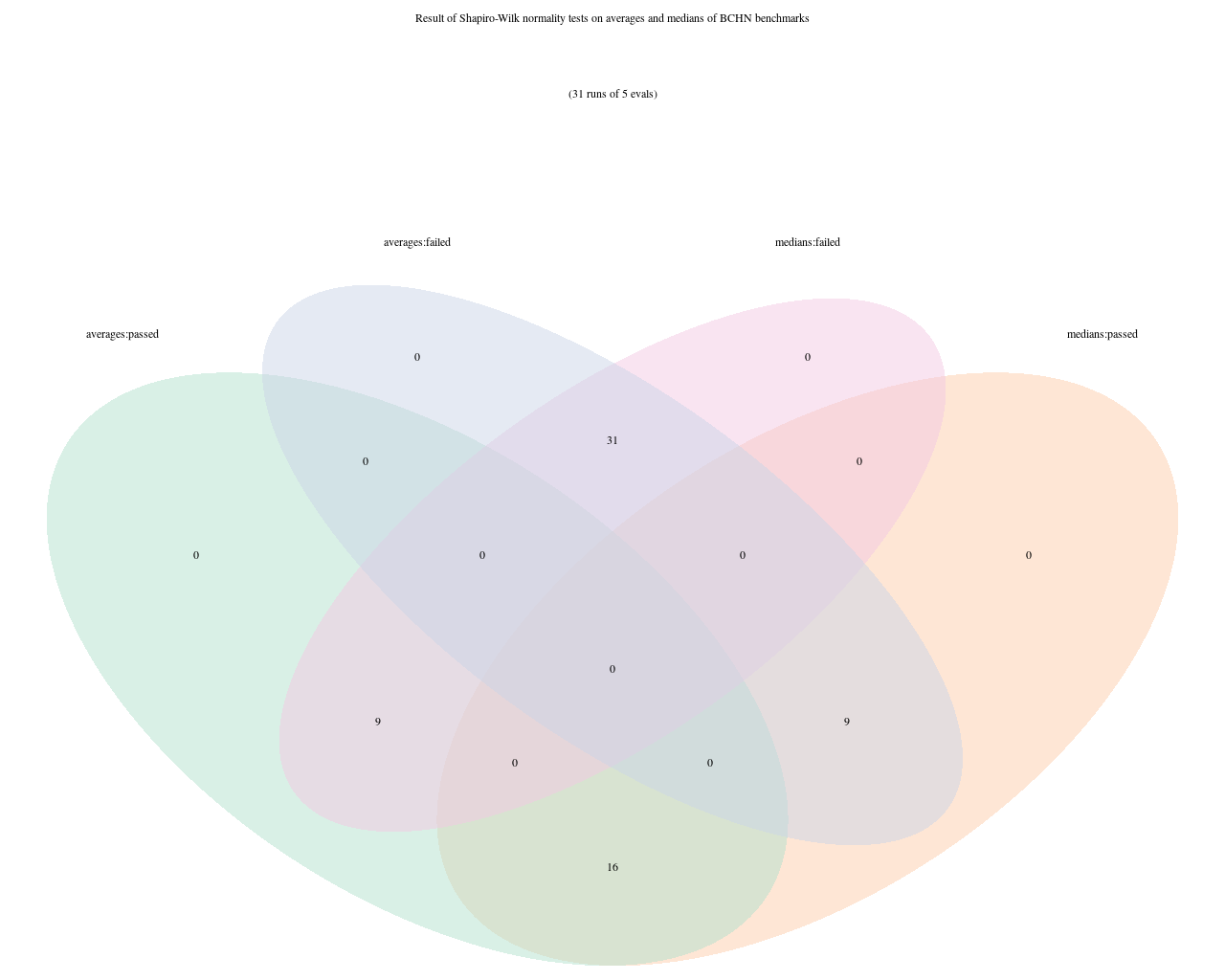
- are the measured performance changes statistically significant, or not?
- do the benchmarks performed accurately reflect the overall performance impacts, as far as we can tell from the limited (but larger than the above) set of benchmarks available to us?
In this topic I want to explore these questions further, and in the course of it, introduce some “tools” we can use to get a better grip on these questions.
For the following, I will use data produced by running the bench_bitcoin binary produced on Bitcoin Cash Node (BCHN). In other clients, the benchmark binary may be called differently, or there may be several separate programs, but the analytical tools should apply generally.