Also want to share logs from a recent benchmark run here (and also attaching a formatted image of just the BCH_2023 VM results for convenience):
The benchmarks use Libauth’s bch_vmb_tests (BCH Virtual Machine Bytecode) file format described in more detail here. We mark some tests as benchmarks by including the string [benchmark] in their description field.
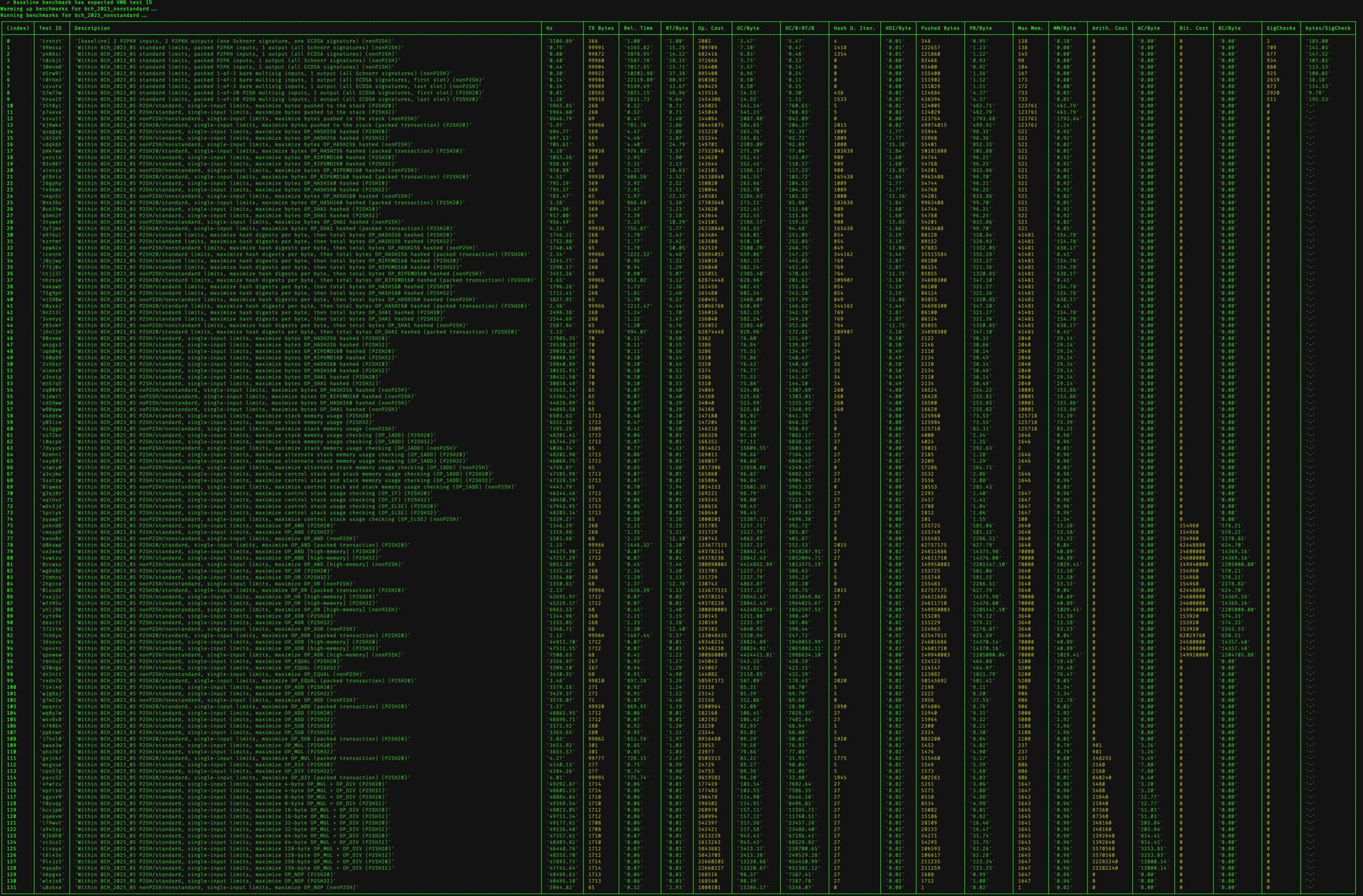
One of the benchmarks (trxhzt) is also marked with the string [baseline]; that is the most “average” possible transaction, including 2 P2PKH inputs (one Schnorr signature, one ECDSA signature), and 2 P2PKH outputs, useful to illustrate the expected baseline “density” of computational cost in transaction verification (validation time / spending transaction byte length).
In general, our goal is to tune limits such that valid contracts do not significantly exceed this “relative time per byte” (RT/byte) density. There are currently other standard transactions with higher RT/byte values (see 1-of-3 bare legacy multisig, first slot, but note that the Libauth results reflect Libauth’s lack of signature or sighash cache; BCHN’s results here are much closer to baseline).
Libauth’s implementation of both the VM and benchmarking suite print out quite a bit more information than any other implementations need: single-threaded validations-per-second on the current machine (Hz), Relative Time (Rel. Time), Operation Cost (Op. Cost), Hash Digest Iterations (Hash D. Iter.), Pushed Bytes, Max Memory (Max Mem.), Arithmetic Cost (Arith. Cost), Bitwise Cost (Bit. Cost), and SigChecks (according to the 2020 upgrade spec). Each of these also has a column where they are divided by transaction byte length to provide relative densities. These columns are useful for understanding what is happening and designing new benchmarks, but other node implementations only need to determine RT/byte to validate their performance across all kinds of contracts.
You’ll also see some outdated benchmarks from previous iterations of the proposal (before we began constraining compute/memory by density of pushed bytes) – I’ll delete those from the final set soon, but wanted to first publish them and share the results to make it easier for others to validate that counting pushed bytes is a more reliable approach.



 )
)