We are ordering the subblocks already. So first means the copy of the TX which is in the first subblock.
Recommended reads:

We are ordering the subblocks already. So first means the copy of the TX which is in the first subblock.
Recommended reads:
Ah, right, you could use the same conflict resolution mechanism as with double-spending TXs and just reject the duplicate(s). That would mean the selfish mining incentives in absence of block reward would remain the same.
If we’d equally redistribute fees to only the subblocks that included the TX (but penalizing width similar to how subsidy is penalized), what’s your intuition on impact on incentives? Imagine a 10 BCH TX is mined and not much left in mempool to fund the next block. Wouldn’t it incentivize a competing miner to fork so he could at least get a portion of that?
If we’d just pool together all fees and redistributed 1/K to each subblock, no matter the position in the tree/DAG, then wouldn’t this create freeloaders / tragedy of commons: rather than trying to get TXs in their block template just mine empty blocks and get paid because others would collect some TXs.
This is incorrect. You are missing the next step. The point isn’t getting these services to accept the subblock confirmations (though they could choose to, but 0-conf still better), it is that there will be far more consistent block times. Hash issue or not, this will make block times far more consistent, which is a win for anything requiring a confirmation or more.
This would be the only ±fair way to do it. If a miner has parameters set to not accept a tx, then they shouldn’t participate in the fee.
Don’t the same anti-fork mechanisms still exist? If this is a credible threat, then the general idea of crypto is flawed. Why would they want to fork if they risk not getting the next block and not being the majority chain? Good way to lose out on monies. Maybe I’m missing the point you’re making, though.
Main block will still be aiming for 10 minutes. Exchanges does not care about number of confirmations. They want finality guaranties. That’s why they wanted the 10-blocks deep rolling checkpoint. If we can improve this with 2 minutes block times and Avalanche, we should. I think Tailstorm is interesting, but I don’t see why we need to rush this. We should focus on better and faster finality guaranties instead.
Not at any cost, what are “we” willing to sacrifice to get those faster finality guarantees? Anyway, please move general talk about block time / finality here: Lets talk about block time
The topic here is Tailstorm, and whether we could make it (or something similar) work. Evaluation vs alternatives would come after we’d have some design we think could work.
When I say fork, I mean fork the subchain in order to get a cut of the fees from TXs already included in another’s subblock, bad choice of word, let’s use “branch” further on. Imagine a steady inflow of 0.1 fee TXs coming in at a steady rate of 2 TXs / block interval, and then one of those TXs has 1.0 fee instead of 0.1.
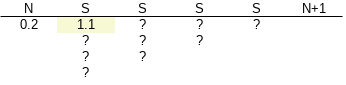
Where do we go from here? Extend the best tip with next 2 TXs, or branch to copy the 2 already mined ones + the 2 new ones? If everyone is just extending the longest chain then it wold look like this:
![]()
But, if one miner got the 1.0 fee TX, then another miner can make a branch in order to get a share of the big bounty:

The above is considering the idea of splitting the fee among duplicates, and still applying the branching penalty to lesser subchains.
It’s still better than the case where winner takes all the fees, which is essentially the same as what orphans do now, however the losing subblock would still contribute PoW:

Network gets the PoW security contribution, miner who contributed it gets nothing.
Currently, neither the losing miner nor the network get anything from it because the block would be reorged.
Yup, and looks like it could improve selfish mining, as well.
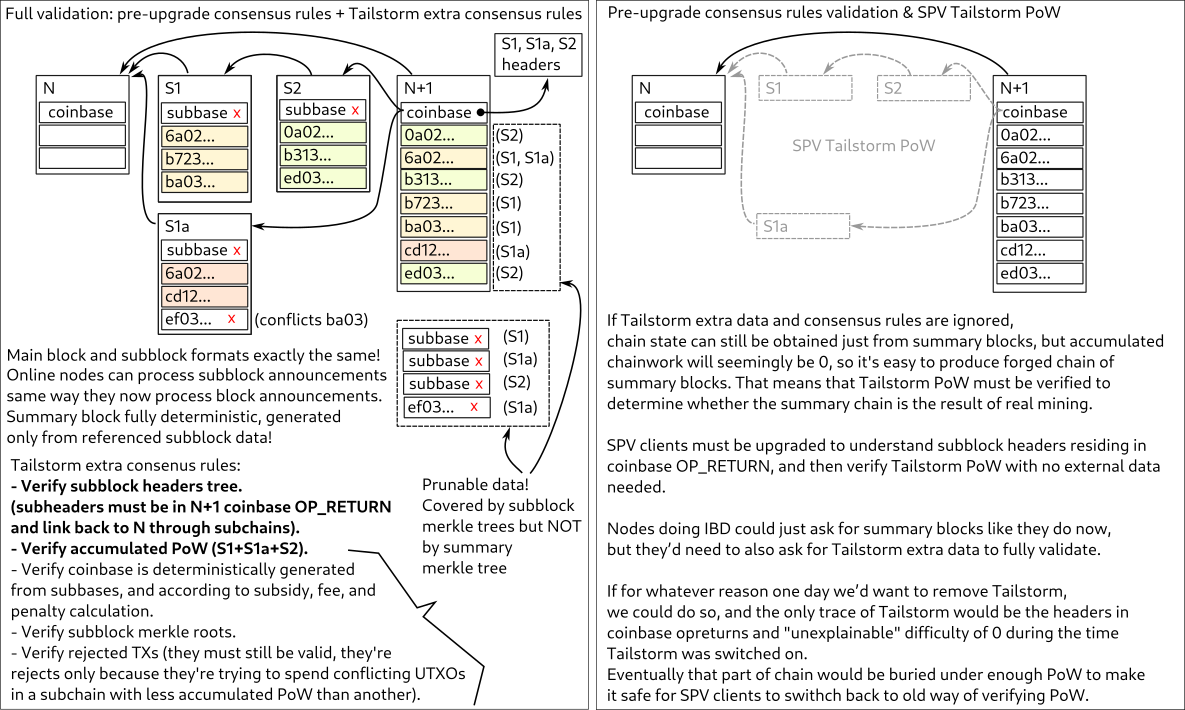
SubBlocks and SummaryBlocks. (both SB, joke here about hardest thing is naming). I’ll call it “FullBlock” instead of SummaryBlock here for that reason…
There are some higher level issues with the idea that I’m not sure people put on the table yet.
subblocks (SBs) are not required to inherit from each other. Technically every single miner can mine their own SB and only when the full block (FB) comes in are they combined.
This means that it is extremely likely to include conflicting transactions in different branches. Your node or indexer can’t reject one of two subblocks that may have been made at the same time with conflicting transactions. They both got mined. (At this point it makes sense to point out that miners CAN (and do) lie about their blocktimes) 
And that means that the entire concept of “the blocks are faster, therefore stuff confirms faster” is out the window. Only when the FB comes in do you know which of the sides of a double spend is finalized, and if the subblock containing the tx that pays you is actually used at all.
So you wait until the final block, just like today.
There is also a choice to require mining a full block or simply make it implied.
If it is implied (zero pow) that means that a conflicting transaction is actually not settled until a full block later. We don’t know which section of subblocks miners are mining on top of.
If there are two subblocks that are in conflict (contain a double spending tx), both have no children blocks, then it’s 50% which one is valid. The FB may simply reject a SB.
So simple logic dictates that you need PoW to finalize the FB. As that is the basic requirement of the Byzantine Generals solution that Satoshi invented.
But if it has PoW, that opens a can of worms:
ps. it is useful to NOT assume there will be an exact correct number of SBs as needed for a FB. Apart from accidents, going for a fraction of full PoW cost, it is likely going to become worth it to have miner assisted double spends.
Not required, but they can and this is favored - because there’s benefit in choosing to extend the longest subchain rather than referencing the previous FB.
The penalty system incentivizes mining on top of best known subtip in order to avoid the penalty. It also incentivizes against subblock witholding because then nobody will see your blocks and they’ll extend the other branch while you mine in secret, and if the public branch wins - you get hit by the penalty if your branch will be shorter.
Why, if the mempool policy stays the same, how would you even obtain a conflicting TX? If anything, it’s likely that subs will include duplicates, like the scenario im_uname laid out:
a quick top-of-my-head example:
block A1-A2 is the longest subchain.
block B1 competes with A1 and has a transaction T1 that doesn’t conflict with A1, yet doesn’t exist in A1-A2 either. it’s a branch, uncle, whatever.
I now want to mine A3. Can I mine T2 that spends from outputs of T1, if block B1 “contributes” transactions? I assume I’ll need to include T1 first so my block is internally consistent. If I include T1, did block B1 actually “contribute” anything?
To which I answered:
I see, good Q, yeah you’d have to include T1, or you’d have to extend the subchain that already has it
Yup. Not rejecting is the secret sauce of Tailstorm, it integrates blocks that would otherwise be orphaned: takes in their PoW contribution + any non-conflicting TXs, and there’s PoW-based dispute resolution for conflicts.
Re. time, they can lie, sure, but it has no effect here. Accumulated PoW settles the dispute just like now, not the reported time. In case of equal PoW (same competing subchain length) it’s a coin toss based on subhashA < subhashB.
No, because if you observe your TX is included in a fast-advancing subchain, you can have some confidence that it won’t be replaced by another subchain - just like now you can have confidence that a 2conf won’t be reorged by another tip.
Miners are incentivized to announce their subblocks ASAP, so let’s say K=60, and there are subtips:
the network needs just 1 more SB in order to announce a FB, and then everyone’s expected to start mining on top of it, else they risk their extra SB getting reorged.
If you have a TX in 1., then you can be pretty sure it will win over whichever tip produces the last SB.
If you have a TX in 2. or 3., there’s uncertainty, if 3. mines the last SB and it has a conflict then it’s a coin-toss. If 2. mines the last SB then it wins over any TX in 3. but NOT against 1.
If 2 SBs arrive simultaneously, the FB picks one of them, and shortly after some SBs in the next epoch start appearing so the network can have confidence which FB won.
You can’t mine a FB unless there’s a pick of SBs available that would accumulate (1-K) PoW.
At that moment, mining a SB would imply overproducing PoW and you risk the SB getting reorged by some other miner mining a FB and not picking your SB. There’s incentive to go for a FB as soon as enough SBs have been announced.
You could still go for an empty SB or FB, why not? Not sure it breaks header-first, I’m not ready to claim either yes/no at this moment.
You’d see higher number of branching / 10min, but not orphans / 10min. That’s the secret sauce. The would-be-orphans get merged, their miners get paid (and only get hit by 1/K penalty), so latency has less impact on their profit, so big pools get less of an advantage over small pools.
If small pools are trying to stay on main branch in order to avoid penalty, sometimes they’d manage, sometimes they wouldn’t, and then you’d have something like this:
-- F -- o -- o -- o --o -- o -- o -- o -- o -- o -- o -- o -- F -- o -- o --
\ o \ o \ o \ x
When they’re not late - they just extend the best tip. When they’re late, they branch off the best tip, but their subs later get picked up by the FB. Only if they’re late to the last sub would their sub get orphaned.
Their loss here would be (3 * 1/K) + 1/K = K.
Compare that to just reducing block time, you’d have this:
-- o -- o -- o -- o --o -- o -- o -- o -- o -- o -- o -- o -- o -- o -- o --
\ x \ x \ x \ x
Their loss here would be 4K.
Ah, so you’re saying that the double spend problem is solved at the mempool level already today. 
You have between 5 and 10 seconds, a block comes in every 16 seconds? “Fast approaching” is not the term I’d use. Because that requires you to stand still for a minute or so. Which is actually what you were trying to avoid.
Your answer also doesn’t actually address the point I made. Two subblocks having conflicting transactions. Completely legal to do, provided they are not in the same sub-tree.
The statement that you can have confidence that it won’t get replaced is misguided. That misses the entire concept of WORK. The reason people are doubting bch is because we’re the < 1% coin. And it costs peanuts to reorg us.
A subblock costs much less to reorg compared to the full block. You can’t assume they won’t be.
This sounds very much like reorganizing chairs on the deck of the Titanic. All your assumptions of security are based on miners not wanting to make some other miner lose their subblock and thus payout. But your assumptions actually use the COST of a full block, which it is not. At all. It is like 1/50th or so.
The rest of your answers are all over the place. Either you’re not at all following my explanation, or you chose to not understand. Either way, re-read above point if you want to understand the issues. I’m not here to convince you.
I liked this self-undermining point most:
So, in my scenario of you not being certain that getting included in a SB means it will actually get mined in a FB was me thinking another SB could conflict with it.
Instead you’re now saying that all SBs can be completely ignored and the FB can just skip all transactions that were in the SBs that lead to it!
Nice.
Incentives are such that everyone’d want to extend the main subchain. If you broadcast a TX and it gets 2 confs in the main chain, chances are it would continue to get mined by honest miners.
Dishonest miner would need to branch an older subblock if he’s to have a shot at getting a conflict be accepted instead of your TX, and he’d be losing money by trying to win the race vs main chain because rewards of lesser branches are penalized.
Even if race is equal and there’s uncertainty until FB decides a winner and chain advances to next epoch - then observing both TXs works like superpowered DSP - one that can cover any kind of TX.
But it costs, and the cost would grow with subchain lenght just like it now grows with confs. Attempting to doublespend a 0-conf TX costs nothing.
Yes, legal, but it costs the lesser branch’s miner. If he’s intentionally creating a branch just to include a conflict, he’ll take a 1/K hit on revenue of that sub. Edit: Yeah, if he’s overtly trying to replace it the total cost of attempt can be just (N/K)*1/K for the epoch. This way, everyone would be alerted of the attempt & race.
But as you’ll see below, if he’s trying to do it covertly, then he stands to lose N/K.
I’m not, but if the amount is not worth the cost of branching, then it’s unlikely. Same logic now applies for reorgs, right? With subs you get more granularity in accumulation of cost-to-replace.
It’s 1/50 when the sub is at the tip, but if your TX is buried at the beginning of that subchain, the miner who’d want to replace it in the FB would have to pop some N subblocks from the tip and replace them with his, and during that time network could advance to next epoch he’d lose all those extra subs rather than just 1.
I was imprecise, when I said empty FB I wanted to say that it doesn’t contribute any additional TX on top of whatever TX the subblocks it references already included.
The FB is is still confirming whatever TXs are in the subblocks it references.
If you need just 1 more sub to reach required number of subs to produce a FB, you can mine an empty SB and then a FB and advance the chain.
You can reference the subs without validating the TXs in them, but you won’t know the UTXO state until you do the validation, so you’d have to keep adding empty subs until you catch up with validation to avoid risk of putting in a TX which would invalidate your block.
So, I think it doesn’t break header-first mining, but sure, we must examine the edge cases more carefully to better understand.
Someone pointed out that Tailstorm is reminiscent of Ethereum’s uncle blocks. There are however some key differences, noting them here for future reference:
Jianyu Niu, Chen Feng, “Selfish Mining in Ethereum” (2019) demonstrated that Ethereum’s PoW consensus system is more vulnerable to selfish mining than Bitcoin. It’s not surprising considering there’s incentive to intentionally uncle weaker miner’s blocks in order to reduce their revenue and increase our own (nephew reward).
Thinking about this more, it depends on how we arrange data structures, but there will be trade-offs.
With the above idea full blocks would look like and link up just like regular blocks do now, but they’d all have apparent difficulty reduced to 1/K (if you’re just looking at FBs and ignoring subblock headers).
This is a problem for header-first mining: you could mine subblocks header-first but not the full blocks, because how would you compute merkle root when it would have to cover all the TXs contributed by the subblocks?
Or, we make FBs merkle root cover just its own TXs (so that it can be an empty block). But then we break the view for non-upgraded software: they wouldn’t see subblock TXs unless they ask for subblocks, too.
Aargh!
Your imprecision happened to just allow you disagree with my statement that a miner needs to validate and have all transactions in order to make an FB.
You correcting this means that the original points of creating a lot more orphans as explained by me above is back on the table.
I think you misunderstand header-first mining. Not a single miner today pushes out blocks that have unverified transactions contained in them.
If you depend on that, you’re doing it wrong.
I had it wrong. FB can’t be done header first with the structure I was considering above because you’d at least need the list of subblock TXIDs to compute the FB’s merkle root. Maybe it could be done with an alternative structure, but then you have more breakage elsewhere (similar breakage to changing block time).
Not quite, this still holds:
There’d be orphan risk just around the FB, but subblocks can still get mined header-first so they still have that advantage.
Then you agree.
Where today there are no orphans, TailStorm introduces a very large increase of orphans as I explained in message 44. (this being msg 52).
Agree that FB can not be mined header-first with the structure considered here. If that’s a deal breaker then we could investigate alternative ways to implement Tailstorm and see where that leads us.
That’s an overstatement, because:
Compared to header-first, you’ll be slightly delayed only on the FB and only for the time it takes you to:
and this delay will only happen every Kth subblock, and risk losing 1/K of the epoch’s reward. In parallel you can do: complete full validation (TX consensus rules + update UTXO state). When that completes, you can start adding any new TXs to FB’s block template.
We can argue whether this is significant or not, but do you agree the above is accurate?
You seem to be in love with arguing your way through technical problems. This is not a marital issue, this is a technical problem where it really doesn’t matter what I or you think about it. It matters how it works in the real world.
I have explained to you with a very simple analysis that it will behave massively worse than status-quo. You can continue arguing that it’s not that bad, and maybe you expect normal people (as you’re a self-described autist) to relent if you want it so much.
Facts remain, all I’ve said in post 44 stands and is true.
We go from virtually no orphans to removing header-first (on FBs) and thus introducing delays that are not 100ms but likely counted in full seconds with small blocks. But much longer with 1GB blocks. Which will create lots of orphans. QED.
You also missed the second point; when there is a need for an exact number of subblocks and more are not allowed to be used in a a full block, then you get orphans on subblocks too. Especially when there are lots of them per 10 minutes. (also explained in comment 44).
You know me, I’d like to be accommodation and I try to stay on focus. But most people would have given up when you didn’t try to solve the issues, instead just try to explain the flaws away.
Your choice, you can take the oldie’s comments about the issues you’ll face on implementations or not. In which case it will show up on actual implementation which may be a year down the road and you’d be going back to the drawing table.
Personally I expect this to be a fatal flaw that completely dismisses TailStorm, the basic concept is too complex to allow header-first mining. Therefor you’ll have more orphans which means it is a net negative.
1 GB blocks would mean 17 MB subblocks (K=60), and it is those last 17 MB + computing merkle root on all TXIDs (about 160 MB big list of TXIDs) that would be delaying your start of mining the FB. Let’s say it is as you say - a deal breaker.
I’m in the “How can we make this work?” mode of thinking, and you’re in the “This is why it won’t work.” mode. You win this round. 
It doesn’t dismiss Tailstorm, it dismisses this particular approach to implementing it.
Why even try implementing it if what you point out is a deal breaker.
It’s back to drawing table now, to find a way where header-first mining works on all blocks, and see if other deal breakers would appear as a consequence of accommodating header-first mining.
Just for reference, the no-PoW-in-FB variant would look something like this:
Impact:
Note that non-upgraded SPV security reduction is present in previous yes-PoW-in-FB, but it goes down to 1/K rather than 0.